微服务架构深度解析与最佳实践 - 第五部分:七个应对策略之性能、一致性与高可用

七个关键问题的应对策略-续
3.关于微服务对性能的影响
大家可以先思考 2 个问题:延迟(latency)和吞吐量(throughout)有什么关系? 延迟是响应时间么?
先说一下延迟和响应时间,延迟是对于服务本身来说的,响应时间是相当于调用者来说的(更多的内容可以参考《数据密集型应用系统设计》一书):
-
延迟(latency) = 请求响应出入系统的时间
-
响应时间(ResponseTime)= 客户端请求开始,一直到收到响应的时间 = 延迟 + 网络耗时
理想状态下,延迟越低,吞吐越高,当然这是对单机单线程而言的,在分布式下就不成立了,举个反例:
比如从密云水库,拉一个水管到国贸,水流到国贸,需要 1 小时;如果再拉一个水管到顺义,20 分钟就可以。如果你在国贸用水龙头接水,你可以单位时间接到非常多的水,这个数量跟你在过国贸还是顺义,没有关系,只跟水库单位时间输入的水量/水压有关系。但是如果你在水管里放一个小球,它从密云到国贸的时间是到顺义的时间的三倍,这样对于到国贸的这个水管系统,延迟很高,但是系统的吞吐量跟到顺义的是一样的。
同理,如果一个单体系统,被拆分成了 10 个服务,假如一个业务处理流程要经过 5 个服务,这 5 个服务只要是每个吞吐量(TPS/QPS)不低于原先的单体,那么整个微服务系统的吞吐量是不变的。
相反地,我们通过服务变小,关系变简单,数据库简化,事务变小等等,如果 5 个系统的吞吐都比原来的系统打,那么改造后的系统,整体的吞吐也比之前要高。那么这个过程的副作用是什么呢?
简单的说,就是延迟变高了,原来都是本地调用,现在变成了 5 次远程调用,假设每次调用的网络延迟在 1-10 毫秒(物理机房+万兆网卡可以很低,云环境下比较高),那么延迟就会比之前增加增加 5-50 毫秒,而且前提是分布式下的请求,使用异步非阻塞的流式或消息处理方式,同步阻塞会更高,而且影响吞吐量。好在低延迟的系统要求比较少见,对于一般的业务系统来说,可以水平扩展的能力比延迟增加几毫秒要重要的多。
比如我们在淘宝或者京东,买个衣服,交易步骤的处理,在秒级都是可以接受的,如果是机票、酒店、电影票之类的,分钟级以上都是可以接受的。
再举一个现实的例子,某个公司从 2016 年起,就在做微服务改造,研发团队规模不大,业务发展很快,基础设施没有跟上,自动化测试、部署都没有。同时这个公司的主要核心业务是一个低延迟高并发的交易系统,微服务拆分导致系统的延迟进一步增大,客户满意度下降。很快研发团队就发现了拆分成了多个小系统以后,比单体更难以维护,继而采取了措施,把部分微服务进行合并,提高可维护性和控制延迟水平。
对于分布式微服务系统的低延迟设计,更多信息可以参考 Peter Lawyer 的博客:https://vanilla-java.github.io/。
4.怎么考虑拆分后的数据一致性
微服务提倡每一个服务都使用自己的数据库存储,这就涉及到老系统的数据库拆分改造。一般的数据库拆分,我们可以把不同业务服务涉及的表拆分到不同的库中去,这样如果之前的事务中操作的两个表如果被拆分到了不同的数据库,就会涉及到分布式事务。下面先解释一下分布式事务。
我们知道 ACID(原子性 Atomicity、一致性 Consistency、隔离性 Isolation、持久性 Durability)定义了单个数据库操作的事务性,这样我们就能放心的使用数据库,而不用担心数据的一致性,操作的原子性等等。由于数据库同时可以并发的给多个应用、多个会话线程使用,这样就涉及到了锁,隔离级别和数据可见性等一系列工作,好在关系数据库都已经帮我们解决了这些问题。
但是在 SOA、分布式服务化和微服务架构的大背景下,数据拆分到多个不同的库已经是常态,这种改造或者设计中,同一个业务处理涉及到的关联数据生命周期可能要贯穿到多个不同的数据库,如果没有事务保证,那么数据的一致性或者正确性就会收到破坏,账就可能会错乱了,平台或者客户就会产生损失了。
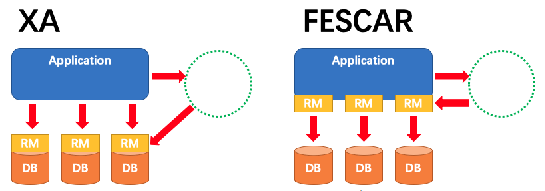
如何保证数据的事务性,则是一个非常有意思的话题。传统的数据库和消息系统一般都是支持 XA 分布式事务,通过一个 TM 事务管理器协调各个 RM 资管管理器,每个 RM 管理自己的本地事务,通过两阶段提交 2PC 来保障一致。
由于 CAP 的不可能三角约束下,我们大部分时候选择了从 ACID 到 BASE(Basically Available 基本可用, Soft-state 柔性状态, Eventually consistent 最终一致),这样分布式事务我们一般也从 XA 变成了 TCC(Try-Commit-Cancel),把分布式事务的控制权从底层资源层(比如数据库)挪到了业务实现层,从而通过释放数据库层的锁,来提升性能和灵活性。具体情况可以参阅下面的两个文章。
-
分布式事务的原理综述,讲的非常详细: https://mp.weixin.qq.com/s/sy PKHc km6uZ3TgJYfRnw
-
分布式事务解决方案与适用场景分析,结合实际,详细说明了 TCC 的原理和用法: https://mp.weixin.qq.com/s/Okvgn5beGy5aJypfu6mKcg
我的好朋友长源和张亮,也分别写过一个分布式事务的系列:
-
长源-漫谈分布式事务:https://zhuanlan.zhihu.com/distributedDatabase
-
张亮-分布式事务:https://shardingsphere.apache.org/document/current/cn/features/transaction/
如果直接操作数据库或者支持 XA/JTA 的 MQ,可以使用 XA 事务。其他情况,可以使用开源的分布式事务中间件。开源的分布式事务中间件有 Apache ServiceComb Pack,Seata/Fescar,Apache ShardingSphere 等。
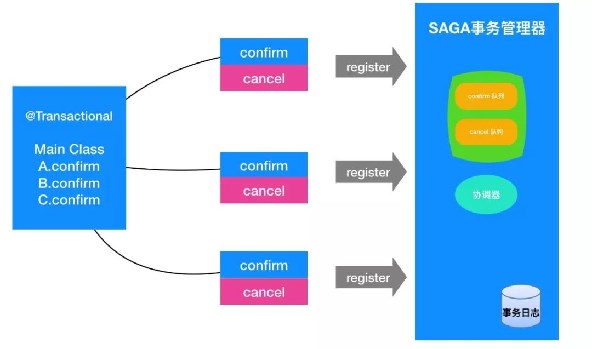
但是实际上,对大部分业务来说,性能远大于分布式事务带来的强一致性要求。更多时候,我们可以先牺牲掉强一致性,甚至是准实时一致性,先让多个不同节点的服务,都自己单独把业务执行掉。然后再通过定时任务去检查是否一致的状态,如果不一致,保证可以从某个存储拿到原来的数据,重新执行即可。这时候其实是做了补偿的操作,补偿会带来数据重复处理的情况,就是检查的时候没有执行,但是去补偿操作的时候,可能已经在执行了。
特别是我们使用异步的 MQ 之类的方式做业务处理和补偿,消息也可能由于 MQ 的机制而重复。这时候我们只需要加上业务处理的幂等操作即可,比如订单处理,我们可以使用 Redis 或者 RoaringBitmap,把最近的 10000 个订单 id 或者 1 小时以内的订单 id,都放进去,每次订单处理之前,先看一下 id 是不是已经在里面了,如果是说明重复了,就不处理。
总之,最好的处理办法就是直接牺牲掉强一致性和准实时一致性,不用事务,既简单,又快速。
5.系统的高可用可伸缩如何实现
1) 扩展立方体

既然分布式的核心是水平扩展系统,那么我们先来看看“扩展立方体”,如上图所示,扩展有三个维度:
-
x 轴-水平复制:复制系统,简单说就是集群,把整个系统作为一个整体,重新部署几套,前面加上集群管理器或者负载均衡器;
-
y 轴-功能解耦:拆分业务,按业务把不同的部分切割开,这样可以使用服务化的方式,把不同服务独立部署,然后各个服务可以自己多实例部署来扩展;
-
z 轴-数据分区:切分数据,把相同的数据按照不同的属性切割开来扩展系统,比如都是用户,VIP 用户比普通用户对平台交易的价值高,我们就可以把 VIP 用户相关的数据单独切分出来,单独提供资源处理,这样可以在 VIP 用户访问量很大(比如 VIP 用户都是高频的量化交易程序)时,单独给 VIP 用户增加机器资源,扩展 VIP 用户的交易订单处理能力。
我们可以通过上面三个维度的扩展性,灵活的应用到自己的场景里去。高水平扩展性带来我们随时给系统增加机器资源的能力。假设 A 系统的可用性为 99%,忽略掉负载均衡器的可用性,那么每多一个 A 服务节点,就意味着我们的可用性再增加 2 个 9,2 个节点是 99.99%,3 个节点就是 99.9999%的可用性。(这也说明了为什么要拆分数据库,数据库跟系统是串行的,只使用一个数据库,就意味着数据库宕机导致所有的服务节点都不可用了。)
2) 无状态系统
同时为了做到尽量高的扩展性,我们需要尽量让每个服务是无状态的、不共享状态和数据,这样的话每个服务才能随时增加机器。
3) 版本机制与特性开关
当我们新上线一个功能,或者升级一个现有功能的时候,可能会产生不兼容,或者对客户有未预期的影响,这个时候考虑提供版本化的接口,或者使用特型开关,在一定的时间窗口内实现对客户的兼容和友好用户体验。
4) 容错机制
分布式环境下,我们默认上下游和基础设施都是不可靠的,那么怎么在不可靠的假设基础上实现可靠性?这就要求我们考虑容错性,实现面向负载和面向失败的设计,考虑系统的限流、服务熔断和降级、系统过载保护等。
5)尽早发现问题
程墨 Morgan 在 https://www.zhihu.com/question/21325941/answer/173370966 里提到的 case 一样,不要画蛇添足,做一些不必要的操作,“要让服务稳定而高可用,靠的可不是一台服务器,应该用多服务的方式来应对”,如果系统可能会发生问题,就让问题早点暴露,而不是让系统带病运行,最终问题大爆发,可能错过了最佳的处理时机。我也深有体会,特别是交易类的系统,如果带着一些不一致的 bug 运行一段时间,可能会让大量的交易账目出错,再来修补问题,更正数据,代价非常大,甚至要赔偿给用户上百万美元。
6)根因分析、积累故障处理经验
历史告诉我们,错误如果不彻底分析原因解决,一定会再次发生。所以,把所有犯过的错,出过的故障,积累起来,每次都做根因分析,一层层的复盘,找到本质原因,制定改进行动项,才能解决这一类问题。经过一段时间的积累,再分析这一段时间的故障情况,就知道我们的研发团队哪一块的能力有缺失,应该去增强和补充这一块的能力。通过积累处理经验,提升系统的可用性和稳定性。
上面总结了一些高可用可伸缩的要点,下面的小节会讲到自动伸缩扩容。
正文到此结束
- 本文标签: 集群 交易系统 实例 src Action 数据分区 微服务 ip 线程 NSA Document dist Atom 高可用 幂等 自动化 数据库 redis 解析 同步 Features 高并发 限流 tab 数据 时间 订单处理 分布式 QPS 测试 负载均衡 UI GitHub 开源 文章 id sharding 服务器 https map SDN 总结 生命 MQ 本质 apache 酒店 SOA 锁 博客 IO bug 部署 java git 京东 管理 分布式事务 http Service 一致性 并发 云 网卡
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

