Java并发——非阻塞队列之ConcurrentLinkedQueue源码解析
在Java并发体系中,很多并发场景都离不开队列。比如Java中的定时任务框架、线程池框架、MQ等。本篇文章将记录我的队列学习之旅中的无阻塞队列源码学习。
线程安全性
首先,队列必须是线程安全的,否则,在并发场编程中,就失去了使用队列的意义了。队列实现线程安全的方式有两种: 非阻塞队列和阻塞队列 。本篇文章我们先研究非阻塞队列。
非阻塞队列
在Java中要实现非阻塞的线程安全,一定绕不开自旋和CAS这一对好搭配。基于这个认知,我们来深入剖析一波Doug Lea大神笔下的ConcurrentLinkedQueue的源码。
ConcurrentLinkedQueue的结构
ConcurrentLinkedQueue是一个基于链表的无界线程安全队列。采用FIFO的方式。它的结构如下:
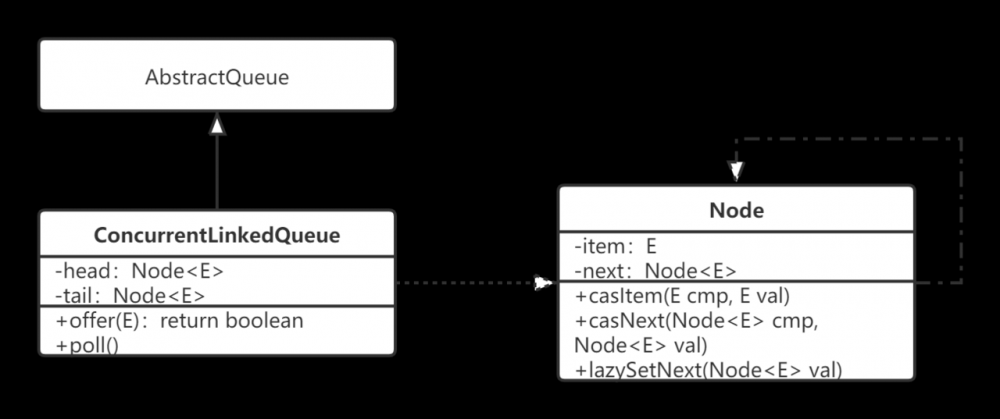
入队源码解析
我们以两个线程来模拟它的入队过程,这个过程很艰难,但是弄懂了之后,将发现不过如此! 源码中的one表示第一次循环,two表示第二次循环,three表示第三次循环。
public boolean offer(E e) {
// 线程1、线程2同时进入,
// 首先,校验不为空,如果为空,则抛出NPE
checkNotNull(e);
// 线程1、线程2同时将当前元素构建一个新的Node节点
final Node<E> newNode = new Node<E>(e);
// 这是一个死循环,以保证元素最终一定入队成功。
// one:初始化时,t变量指向tail,p变量指向t,即p->t->tail.
// two:线程2由于第一次循环CAS操作失败了,因此将进行第二次循环,
// two:此时,依然是p->t->tail。因为线程1并没有改变tail的值,所以tail依然是没有改变的。
// three:线程2的第三次循环来咯,此时p节点已经指向了真正的尾节点了。
for (Node<E> t = tail, p = t;;) {
// one:一开始时,q变量指向p节点的next节点,即:指向tail的next节点,此时next节点为空。
// two:此时q = p.next,虽然tail没有变化,但是tail的next节点已经不为空了!
// two:因为线程1已经通过CAS操作设置成功了!因此,此时线程2将跳转到else分支
// three:由于p已经指向了真正的尾节点,因此p.next == null成立,因此,此时线程2将进入if分支。
Node<E> q = p.next;
// one:此时,线程1和线程2都会执行到这里,进入if分支。
if (q == null) {
// one:线程1和线程2同时通过CAS操作设置tail节点的next节点
// one:此时必然只有一个线程CAS操作成功。假设线程1执行成功,线程2执行失败。
// three:线程2通过CAS操作设置尾节点的next节点。
if (p.casNext(null, newNode)) {
// one:线程1执行成功后,此时p == t 这个条件是成立的,因此不会通过CAS操作更新tail节点指向尾节点,退出循环。
// one:而线程2执行失败了,因此,将指向第二轮循环。
// three:线程2如果执行成功后,此时p指向的是真正的尾节点,而t节点依然指向的是tail节点,由于线程1并没有更新tail节点为尾节点,因此p!=t成立!
if (p != t)
// three: 线程2通过CAS操作更新tail节点指向尾部节点,
// 就算更新失败了也没有关系,说明又有其他线程更新成功了,
// 线程2退出循环。
casTail(t, newNode); // Failure is OK.
return true;
}
}
else if (p == q)
// 这个分支的成立条件只有一种情况,那就是初始化时的情况,此时p=q=null.
p = (t != (t = tail)) ? t : head;
else
// two: 此时将通过for循环寻找到真正的尾节点并赋值给p变量。
// 找到后,进入第三次循环three.
p = (p != t && t != (t = tail)) ? t : q;
}
}
复制代码
通过以上的源码分析,我们知道了元素是如何入队的,并且能够理解为什么tail节点并不总是尾节点了。 以图片的形式展示入队的过程如下:
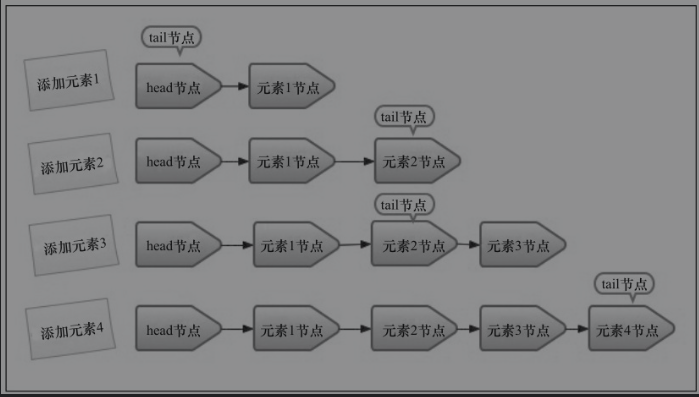
以上的入队过程为什么要设计的这么复杂呢?tail节点能不能必须是尾节点呢?我们带着这样的问题来尝试进行优化:
public boolean offer(E e) {
checkNotNull(e);
Node<E> n = new Node<>(e);
for(;;) {
Node<E> t = tail;
if(t.casNext(null, t) && casTail(t, n)) {
return true;
}
}
}
复制代码
让tail节点永远指向队列的尾节点,这样实现的代码量很少,并且语义更加清晰。但是Doug Lea大神却偏偏不按照我们普通人的思路实现。因为这样做有一个明显的缺陷:每次都要通过循环CAS更新tail节点。如果能够减少循环次数,就能够提高入队效率。
所以Doug Lea大神采用了“间隔式”的方式来更新tail节点。即:当tail节点和尾节点超过一定距离才更新tail节点。JDK1.7之前,用的是HOPS变量来控制距离,而JDK1.8则通过p == t来判断,其本质是和HOPS变量的作用一样的。其实这种处理方式从本质上来说就是通过增加对volatile变量的读操作来减少volatile变量的写操作,而读操作比写操作的效率要高很多,所以入队的效率才会有所提升!
通过以上解析,入队其实就是解决两个问题:1.更新tail节点;2.找到尾节点。其中对于更新tail节点,Doug Lea大神做了特殊优化,优化的方式就是“间隔式”的更新tail变量。
出队源码解析
同样的,我们以两个线程来模拟队列出队的过程。有了入队的解析过程,相信出队的解析会轻松一些,因为出队和入队的一些思想是一样的。源码如下:
public E poll() {
restartFromHead:
// 死循环
// 线程1和纤程2同时进入循环。
for (;;) {
// one: 一开始,p->h->head,即指向头节点
// two: 线程2由于cas操作失败,因此将进行第二次循环,此时依然是p->h->head
// three: 线程2将进行第三笔循环执行,此时h = head,然而,p = head.next,即下个节点了。
for (Node<E> h = head, p = h, q;;) {
// one: 线程1、线程2同时获取到head的元素item
// two: 线程2执行获取head的item,由于线程1已经将head节点的item设置成null了,因此线程2获取的item = null,因此进入第一个else if分支。
// three: 线程2将获取到下个节点的元素,
E item = p.item;
// one: 线程1、线程2同时通过CAS操作来设置头节点的item为null,
// 此时,必然只有一个线程设置成功,另一个线程设置失败,假设是线程1设置成功。线程2设置失败,此时线程2进行第二次循环。
// three: 线程2通过CAS操作成功。
if (item != null && p.casItem(item, null)) {
// one: 线程1执行到这里,并且此时p = h = head,因此判断条件不成立,返回item.
// three: 线程2执行到这里,p != h 判断条件成立。因此cas更新hdead节点。如果p.next为空,则就为p节点自己,否则就是p.next节点。
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// two: 线程2执行到这个判断分支,目的是设置q = head节点的next节点。
// 如果q == null成立,则说明已经到了队列尾部,此时直接更新头结点并返回null。
// 如果q != null,线程2将继续执行第二个else if分支。
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
// two: 线程2继续判断p == q,如果条件成立,则说明又有其他线程更新了head节点,则使用新的head重新循环。
// 如果条件不成立,则继续执行else分支。为了当前例子的分析,假设这里条件不成立。
else if (p == q)
continue restartFromHead;
// two: 线程2执行到此处,执行p = q,实际上就是将head节点的下个节点赋值给p变量,即:p = head.next.此时线程2将继续进行第3次循环。
else
p = q;
}
}
}
复制代码
通过以上的分析,我们发现,出队和入队的处理思想居然是一致的。即head节点不总是指向头节点。也是采用“间隔式”的方式更新。更具体一点就是:如果head节点的元素不为空,则直接取head节点的元素且不会更新head节点,当head节点的元素为空时,才会更新head节点指向头节点。
以图片的形式展示出队的过程如下:

其他方法说明
| 方法名 | 说明 |
|---|---|
| peek() | 获取元素而不删除元素,但是也会像poll那样更新head节点 |
| size() | 当前队列中的有效元素个数,这个方法得到的结果不一定精确,因为它没有使用同步锁,在统计的过程中,队列可以进行入队、出队和删除元素操作。因此不是线程安全的 |
| remove(Obj o) | 删除元素 |
总结
ConcurrentLinkedQueue是非阻塞队列的经典实现。非阻塞队列的应用场景大多是多端消费的场景。

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

