WePay机器学习反欺诈实践:Python+scikit-learn+随机森林
【编者按】 将机器学习算法用于金融领域的一个很好的突破口是反欺诈,在这篇博文中,WePay介绍了支付行业构建机器学习模型应对很难发现的shell selling欺诈的实践心得。WePay采用了流行的Python、scikit-learn开源学习机器学习工具以及随机森林算法。以下是文章内容:
什么是shell selling?
虽然欺诈几乎涉及各种领域,但相对于传统的买方或卖方仅仅担心对方是否是骗子,支付平台需要担心的是交易双方。如果其中任何一方存在信用诈骗,真正的持卡人发现和撤销费用,平台自身就要进行账单偿还。
shell selling是在这种情况下特别受关注的欺诈类型的一种。基本上,当交易双方都带有欺骗性质时,这种模式便会发生,比如说有一个犯罪分子用偷来的一个信用卡账户来支付两笔支付。
shell selling可能很难发现,因为这些欺骗者姿态很低调。他们通常没有多少“真正”的客户,所以你不能依靠用户反馈结果,用这种方式你会碰到更多传统的欺骗者。当一个商人在一个很短的时间段里获得了来自同一个IP的一堆付款时,这很明显,但主导这种欺诈罪行的情况往往比这还要复杂很多。他们常常使用各种各样的技术来隐藏自己的身份和逃避侦测。
由于shell selling是一个普遍的难题,而且很难被发现,所以我们决定建立一个机器学习算法来帮助抓住它。
构建机器学习算法注意事项
在WePay,我们采用Python建立整个机器学习的流程,采用流行的 scikit-learn 开源学习机器学习工具包。如果你还没有使用过scikit-learn,我强烈建议你尝试。对于欺诈模型这类需要不断重新训练和快速部署的任务,它有很多优点:
- scikit-learn使用一个统一的API来跨不同机器学习算法实现模型拟合 与预测,使得不同算法之间的代码复用真正有效。
- 网络服务(web services)的评分可以利用Django或Flask直接进行基于Python的服务器托管,从而使部署更为简单。我们只需要安装scikit-learn,复制导出模型文件和必要的数据处理管道代码到网络服务实例用于启动。
- 整个模型的开发和部署周期完全用Python独立编写。这给了我们一个超过其他流行机器学习语言像R或SAS的优势,后者需要模型在投入生产之前被转换成另一种语言。除了通过消除不必要的步骤简化了开发,这还给予我们更多的灵活性来尝试不同的算法,因为通常情况下,这个转换过程并不好处理,它们在另一个环境中的麻烦会多于价值。
算法:随机森林(Random Forest)
回到shell selling,我们测试了几种算法,然后选定能给以我们最好的性能的算法:随机森林。
随机森林 是Leo Breiman 和 Adele Cutler开发的一种基于树形结构的集成方法,由Breiman于2001年在机器学习期刊的评议文章中首次提出[1]。随机森林在训练数据的随机子集上训练许多决策树,然后使用单个树的预测均值作为最终的预测。随机子集是从原始的训练数据抽样,通过在记录级有放回抽样(bootstrap)和在特征级随机二次抽样得到。
我们尝试的算法的召回率,随机森林提供了最佳的精度,紧随其后的是神经网络和另外一种集成方法AdaBoost。相比于其他算法,随机森林针对我们碰到的各类欺诈数据有许多的优势:
- 基于集成方法的树可以同时很好地处理非线性和非单调性,这在欺诈信号中相当普遍。相比之下,神经网络对非线性处理地相当不错,但同时受到非单调性的羁绊,而逻辑回归都无法处理。对于使用后两种方法来处理的非线性和/或非单调性,我们需要广泛的和适当的特征转换。
- 随机森林需要最小的特征预备和特征转换,它不需要神经网络和逻辑回归要求的标准化输入变量,也不需要聚类和风险评级转换为非单调变量。
- 随机森林相比其他算法拥有最好的开箱即用的性能。另一个基于树的方法,梯度提升决策树(GBT),可以达到类似的性能,但需要更多的参数调优。
- 随机森林输出特征的重要性体现在作为模型训练的副产品,这对于特征选择是非常有用的[2]。
- 随机森林与其他算法相比具有更好的过拟合(overfitting)容错性,并且处理大量的变量也不会有太多的过拟合[1],因为过拟合可以通过更多的决策树来削弱。此外,变量的选择和减少也不像其他算法那么重要。
下图是随机森林与其竞争对手的对比情况:

训练算法
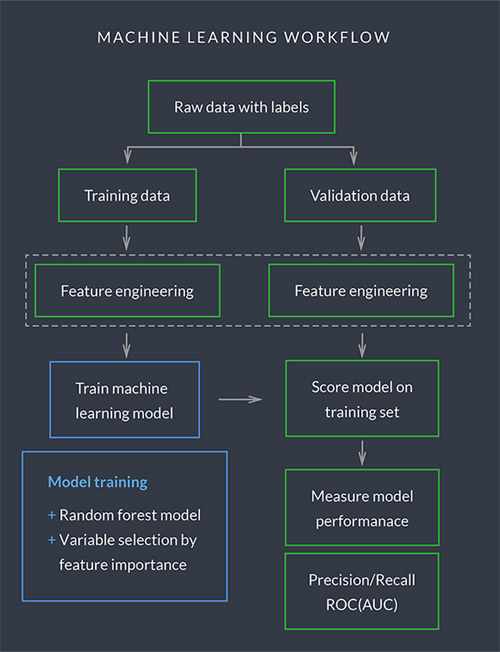
我们的机器学习流程遵循一个标准程序,包括数据抽取、数据清洗、特征推导、特征工程和转换、特征选择、模型训练和模型性能评价:
洞察
经过大量的训练,我们的随机森林算法对于shell selling的识别已经成为现实,并且积极地阻止欺诈。当然我们还需要大量的工作去选择、训练和部署该算法,但是它已经使得我们的风险流程更加健壮,且有能力使用更少的人工来检查抓住更多的欺诈。在同一欺诈召回率,这一模型的精度是不断调整和优化规则的2 - 3倍。
使用这种算法,除了得到明显的好处以外,我们对于数据和建模过程中使用的方法也有了更多的理解:
- 通过特征选择的过程,我们发现对这种欺诈行为最有预测力的特征是速度型的变量。这些包括用户的交易量、设备、真正的IP和信用卡。我们还发现,设备ID、银行账户和信用卡等账户相关特性都是很有用的,如多个账户登录到一个设备,以及多重提款到一个银行账户。
- 风险等级的分类变量,如电子邮件域,应用程序ID、用户的国家,以及一天中的时间风险评级,也证明了高度预测性。
- 数字足迹诸如浏览器语言、操作系统字体、屏幕分辨率、用户代理、flash版本等对于反欺诈是有点用的。稍微有更多预测性的是在人们隐藏他们的数字足迹过程当中,例如VPN隧道或虚拟机和TOR的使用。
- 我们还发现模型性能迅速恶化。这真的不是一个惊喜——骗子不断改变他们的方法来避免检测,所以即使是最好的模型,如果不改变也终将过时。但是我们非常惊讶这发生的速度有多快。对shell selling而言,在模型训练后仅仅第一个月精度便下降一半。因此, 经常刷新模型来保持高检测精度对于欺诈检测的成功是至关重要的。
- 不幸的是,频繁刷新暴露出他们自己的问题。虽然刷新模型尽可能经常是理想的,但是在使用最近的事务数据来训练模型时必须格外小心。欺诈标签可以需要一个月成熟,所以事实上使用最近的数据也会污染模型。和我们最初的假设不同,利用最新数据在线学习并不会总能得到最好的结果。
- 随机森林是一个生产高性能模型的优异的机器学习算法,然而,它通常被用来作为一个黑盒方法。这是一个问题,因为我们并不是试图要完全削减人类的全部过程,而且很有可能无法做到即使我们愿意。人类分析师总是希望得到原因代码,告诉他们为什么事情被标记之后来引导他们的案件审查。但随机森林,就其本身而言,不能随时提供原因代码。解释模型数据是困难的,而且还可能涉及挖掘“森林”的结构,这可以显著提高评分的时间。实际上,为了应对这个问题,WePay的数据科学团队发明了一种新的私有方法可以从随机森林算生成原因代码,我们为这种方法申请了临时专利。
结论
风险管理技术是WePay的核心。风险管理不仅仅是技术,它还体现了人类和技术无缝合作的伙伴关系。它在很大程度上仍然是人类不得不思考的方式,骗子可以攻击一个支付系统,编写规则来阻止它们,而且还是一个经验丰富的专业人员,当它下跌到 “明显欺诈”和“显然合法” 之间的灰色地带时,它必须像经常处理的那样,做出判断是否阻止交易。
这就是为什么我们如此兴奋于机器学习和人工智能。我们并非试图取代人类,只是希望机器智能更加聪明更好地工作,而我们可以集中人类智慧关注其他的大难题。
引文
[1] Machine Learning, October 2001, Volume 45, Issue 1, pp 5-32
[2] Robin Genuer, Jean-Michel Poggi, Christine Tuleau-Malot. Variable selection using Random Forests. Pattern Recognition Letters, Elsevier, 2010, 31 (14), pp.2225-2236.
Jon Xavier对本文亦有贡献。
原文链接: How we’re using machine learning to fight shell selling (翻译/王辉 编辑/周建丁)
第七届中国云计算大会将于6月3日-5日在北京国家会议中心举办。目前主会演讲嘉宾名单和议题方向已经公布,众多中国科学院/中国工程院院士、BAT云技术领军人、三大运营商云计算负责人、中国银联执行副总裁、青云联合创始人等嘉宾届时都将带来精彩演讲。欢迎大家访问【 大会官网】,了解更多详情。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

