深度探索JFR - 3. 各种Event详细说明与JVM调优策略(3)
3. 虚拟机相关 Event
3.3. JIT即时编译相关
JIT 即时编译可能会遇到编译后的代码缓存占满,或者因为空间有限或者代码设计问题,导致某些关键方法需要重编译导致性能问题,以及因为代码块过大导致编译失败从而性能有问题,这些问题我们可以通过 JFR 中相关的 Event 进行查询。 JFR 对于 Java 开发可以完全替换 JVM 编译日志 。
额外讲解:JIT 相关的知识
首先,这里简单介绍下 JIT 相关的知识(这里我推荐看 O'Rerilly 上面的 Java Performance 第二版的第四章: Working with the JIT Compiler ):
首先什么是 JIT: 当 Java 被编译为字节码形式的 class 文件之后,他可以在任意的 JVM 运行。这里说的编译,主要是指 前端编译器 。但是 class 文件里面的字节码并不能直接运行,而是要通过 后端编译器 在程序运行期间,将字节码转变成机器码,这样电脑才能执行你的代码。
Java Code Cache 是啥: 如果 Java 每次都需要即时编译成机器码,再执行,效率太慢了。那么是不是对于某些热点代码,编译后的机器码,缓存起来,这样下次就不用重新即时编译了,多快乐。Java Code Cache 就是用来干这个的。但是编译后的机器码太大了,Java Code Cache 的空间是有限的,也不能将所有的代码都编译成机器码缓存起来。所以就需要一些优化与清理策略。
C1,C2 编译器与分层编译(Tiered Compilation)以及编译级别(Compilation Level): C1,C2 按照老概念来看,分别是客户端编译器和服务端编译器,随着 -server 的 Java 参数的消失,代表着 Java 程序本质上不再区分客户端服务端,所以目前所有的 Java 进程都是 C1,C2混合使用。
C1 编译器对代码做一些简单的优化并加入一些采样代码, C2 针对 C1 加入的代码的采样结果,做更多的分析(语法解析,逃逸分析,高级优化器等等),优化成为更好的代码。C1是一个简单快速的编译器,主要关注点在于局部优化,而放弃许多耗时较长的全局优化手段。C2 则是关注于耗时较长的全局优化手段。同时由于 Java Code Cache 是有限的,有些代码可能优化后被淘汰,需要重新编译,没必要对于每种代码都进行 C1 C2 的优化,那些执行次数少的代码,直接编译执行即可。
C1,C2是怎么配合的呢?从 Java 7 开始引入了分层编译的概念,目前已经是默认的即时编译方式。Java 代码一共有如下几层编译级别:
- level 0:代码直接解释执行
- level 1:通过 C1 编译器优化编译执行(不会加入采样代码,例如统计这段代码执行次数等等)
- level 2:通过 C1 编译器优化编译执行(加入非常轻量的采样代码)
- level 3:通过 C1 编译器优化编译执行(加入所有的采样代码)
- level 4:通过 C2 编译器优化编译执行(根据上一步采样代码的信息,决定如何优化)
一般情况下,热点代码都是经过 0 -> 3 -> 4 这个路径被优化的。但是也有例外情况:
- 当方法过于简单的时候(例如只有一行代码) ,C2 不能在 C1 的基础上更加优化,则走向 level 1,去掉了采样代码。
- 如果 C2 线程正忙(C2 线程任务队列满了) ,则走向 level 2,因为认为 C2 一段时间内不会恢复,level 3 采集的很多数据有时效性,现在采集也没意义,所以先走向 level 2 减少采集。之后过一段时间,重新变成 level 3,等待 C2 闲时,走向 level 4
- C1 忙,但是 C2 闲时 ,直接从 level 0 升级到 level 4。
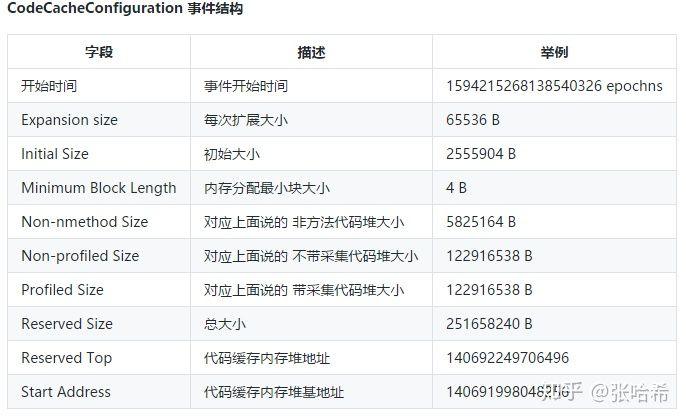
Java Code Cache 分块( Segmented Code Cache ): 从 Java 9 开始引入的 Code Cache 分块,主要解决之前把所有种类代码放一起,导致扫描的时候效率低下。例如之前说的有些代码经过 C1 优化,之后 C2 优化,这些代码最好分开存储。(C1 优化过得代码,C2 优化完之后,C1的要被清理掉)。
目前 Java Code Cache 分为 3 块:
- **非方法代码堆(non-method code heap):**这些是 JIT 编译器要用到的内存区域,例如编译器要用的缓存等等。他们会永远存在于 Code Cache 内。
- **带采样的代码堆(profiled code heap):**目前是经过 C1 编译器优化的代码,就是轻度优化,带采样代码的代码,存活时间比较短,因为 C1 优化的代码最终会被 C2 优化,或者退回 level 1 去掉采样。
- **不带采样的代码堆(non-profiled code heap):**包含不带采样的代码,已经完全优化好,并且长期存活的代码。
默认情况下,非方法代码堆包括 3MB 的来自于虚拟机的固定空间占用,以及随着编译线程个数上涨而上涨的空间占用。剩下的空间,带采样的代码堆与不带采样的代码堆评分,可以通过如下参数修改:
- -XX:NonProfiledCodeHeapSize: 不带采样的代码堆大小.
- -XX:ProfiledCodeHeapSize: 带采样的代码堆大小.
- -XX:NonNMethodCodeHeapSize: 非方法代码堆大小.
- -XX:ReservedCodeCacheSize 以上三个加起来需要等于这个
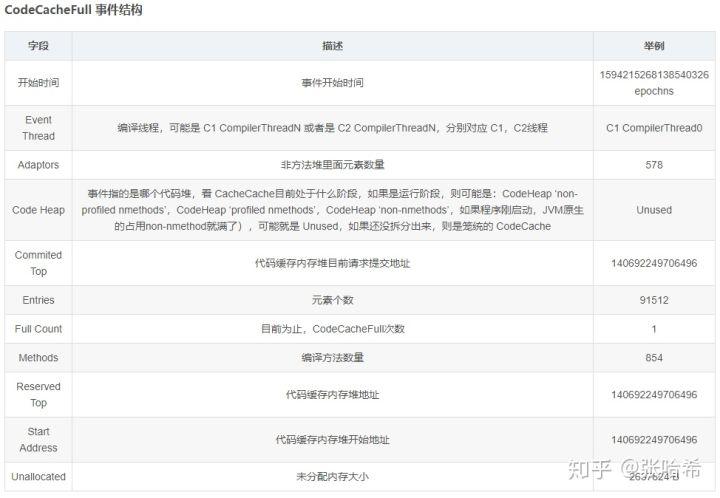
Code Cache Sweeper(代码缓存清理器): 随着 Java Code Cache 的分块处理,目前 Code Cache Sweeper 只用扫描 带采样的代码堆 和 非方法代码堆,并且可以分开并发扫描,看那些代码缓存可以回收。
Method Inline(方法内联): 通俗来讲,就是JVM在运行时优化编译好的代码,将 经常调用的方法从调用替换为方法体代码 ,减少调用。通常发生在 C1 编译器优化。举一个简单的例子:在编写Java的POJO object时候,经常会用到getter和setter,这是从学校里学java开始,我们就一直使用的设计模式,为了保证POJO类对象的域安全。但是我们是否考虑过,如果每次都用这个而外的方法修改,那么是否都会多一次方法栈寻址调用?这样对性能肯定是有影响的。幸好我们有Java Inline Method这个机制,参考下面的代码:
public class JitInlining {
public static void main(String args[]) {
Position position = new Position(25);
for (int i = 0; i < 1000000; ++i) {
int x = position.getX();
position.setX(x + 1);
}
System.out.println(position.getX());
}
}
class Position {
private int x;
public Position(int x) {
this.x = x;
}
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
}复制代码
加上jvm参数来看一下inline效果: -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
@ 19 com.test.Position::getX (5 bytes) accessor @ 27 com.test.Position::setX (6 bytes) accessor复制代码
这个accessor代表jit识别这些方法是某个field的accessor(即getter或者setter),accessor是会被inline的。
OSR(On Stack Replacement): 一种在运行时替换正在运行的函数/方法的栈帧的技术。JIT 优化,一般在某一段代码被执行很多次之后,例如:
for (int i = 0; i < 10000; i ++) {
this.data++;
}复制代码
this.data++; 如果被编译器优化之后,这个循环还没执行完,则需要 OSR 机制,动态替换正在栈帧中待执行的代码。这样还没完成的循环,就可以用优化后的代码执行。
通常来看,应该把 所有的栈上替换执行代码 都叫做 OSR,但是 Java 中 只针对于编译器优化的代码替换原有代码称为 OSR ,对于去优化的替换(就是用原有代码替换优化过的代码),称为 Bailout
为什么会有这种 Bailout 的情况呢?代码优化可以分为(这里参考 大神的知乎回答 ):
- 从低优化向高优化迁移:为了平衡启动性能(刚开始要启动速度快,所以要初始开销小的执行模式)和顶峰性能(代码执行一段时间,对于热点代码,想要更快需要更优化的执行模式,即便优化需要较大开销)
- 从高优化向低优化迁移:有很多情况,这里仅举例:
- 高优化层级做了很激进的优化:例如假设某个类不会有别的子类、某个引用一定不是null、某个引用所指向的对象一定是某个具体类型,等),而这个激进的假设假如失效了的话,就必须退回到没有做这些优化的“安全”的低优化层级去继续执行。这个非常重要,有了这种 Bailout 机制的支持,JIT编译器就可以对代码做非常激进的优化,性能受正确性要求的约束会得到放松,因而对常见代码模式可以生成更快的代码。
- 高优化层级不便于 对代码做调试 ,如果某个方法之前已经被JIT优化编译了,而后来有调试器动态决定调试该方法,则让它从高优化层级退回到便于调试的低优化层级(例如解释器或者无优化的JIT编译版本的代码)去执行。
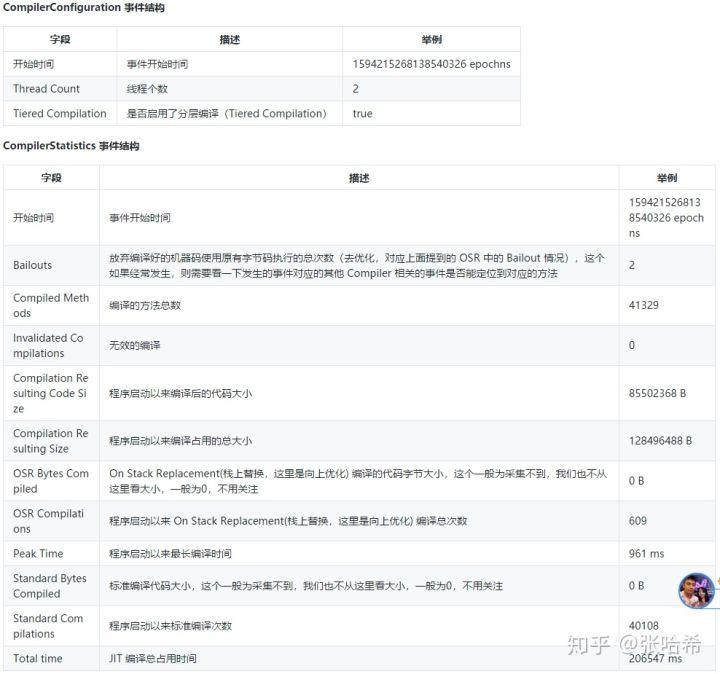
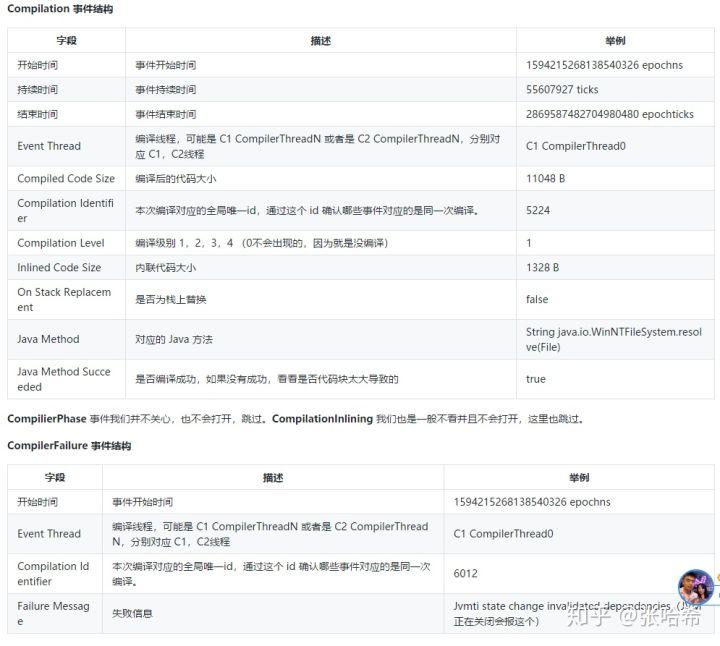
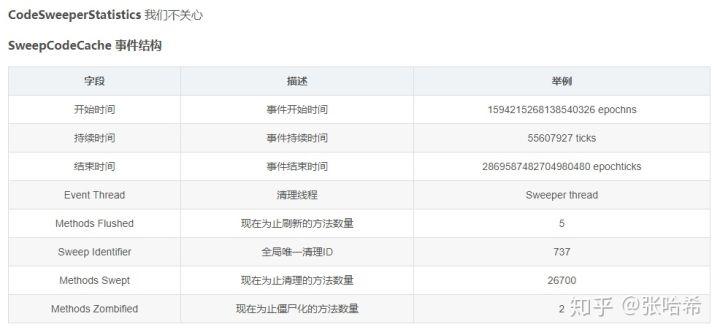
JIT即时编译相关的 Event 列表


正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

