用字节码解释try、catch、finally、i++、++i的执行结果
❝
扫描下方二维码或者微信搜索公众号 菜鸟飞呀飞
,即可关注微信公众号,阅读更多 Spring源码分析
、 Java并发编程
、 Netty源码系列
、 MySQL工作原理
和 JVM专题系列
文章。

2018 年那会,我来酷划面试的时候,被问到了一道题,如下:
public int increment(){
int i = 0;
try{
return i++;
}catch (Exception e){
return i;
}finally {
System.out.println(i);
i++;
}
}
复制代码问题是:
-
该方法的返回值是多少?( 「 答案是:0 」 )
-
是否会打印 i 的值?如果打印,打印出来的是多少?( 「 答案是:会打印,打印的是 1 」 )
题目很简单,第 2 问几乎都能答出来,但第 1 问,相信很多人看到后第一感觉是不确定: 「 到底是 0 还是 1? 」
实际上,这是一类题,网上有很多和这道题类似的面试题,很多变种,如果靠背答案去死记硬背,很容易搞混。如果要从根本上弄明白这类题,就得从字节码和虚拟机栈的角度去解释了(事实上,我觉得能被问到这类题,最终的答案都是其次,面试官最终想考察的是求职者对 JVM 字节码部分的掌握程度)。
接下来,将从字节码的角度来解释这道面试题的答案。
在正式解释之前,先介绍一部分涉及到的基础知识,熟悉的同学,可以直接略过。
虚拟机栈
JVM 虚拟机是 「 基于操作数栈而不是基于寄存器 」 来执行的,每个线程都拥有一块私有的内存空间,这块内存空间被称作为虚拟机栈,虚拟机栈由一个个栈帧组成,每个方法对应一个栈帧。一个方法的调用过程,就对应一个栈帧的入栈和出栈。
每个栈帧的结构又可以细分为 「 局部变量表、操作数栈、动态链接、返回地址、其他附加信息 」 。今天主要介绍一下局部变量表和操作数栈。
局部变量表
局部变量表就是用来存放方法的参数、方法内部定义的局部变量等信息,局部变量表的容量以变量槽为最小存储单元,对于 byte、boolean、short、int、char、float、reference(引用类型)、returnAddress 类型的变量或者参数,只占用一个 slot,对于 long、double 类型的数据,占用 2 个 slot。
对于实例方法(未使用 static 修饰),局部变量表中索引为 0 的槽位存放的是 this 变量(这也是为什么在实例方法中能使用 this 关键字的原因),对于类方法(使用 static 修饰),局部变量表中则没有存放 this。方法的参数和内部定义的变量,则按照在代码中出现的先后顺序依次存储在局部变量表中。
需要说明的是,局部变量中的变量槽是可以重用的。什么意思呢?如果一个变量被定义在方法内部的一个代码块中,那么当代码块的语句执行结束后,这个变量所占用的变量槽是可以被后面的变量所重复利用的。例如如下示例:
public void slot(){
{
int a = 1;
}
int b = 0;
}
复制代码在上面的示例中,a 变量所处的变量槽是可以被 b 重复使用的,该示例代码中,局部比变量表的大小为 2,局部变量表索引为 0 的地方存储的是 this 变量,索引为 1 的地方存储的是变量 a,当 a 所处的代码块结束后,索引为 1 的槽位存储的就是变量 b 了。
局部变量表的大小,在方法的编译时期就被确定了,并且被存储在方法的 Code 属性的 locals 数据项中(Code 指的是方法被编译成字节码文件后,用来描述方法的一个数据项)。
操作数栈
操作数栈是一个 「 先进后出 」 的栈结构,在方法的执行过程中,会使用字节码指令对数据进行加减乘除等操作,这些数据都是先被加载进操作数栈后(入栈)再进行操作的,最后再通过字节码指令写入到局部变量表中(出栈)。
操作数栈的大小也是在编译时期就确定下来的,操作数栈的大小被存储在方法的 Code 属性的 stack 数据项中。
字节码解释
知道了局部变量表和操作数栈的基础知识后,下面我们来看下文章开头的面试题如何使用字节码来解释。
首先我们将代码通过反编译工具进行反编译成我们能看的懂的字节码,反编译工具有 JDK 自带的 javap (命令行: 「 javap -verbose XXX.class 」 ),也可以使用 Idea 中的插件 jclasslib(强烈推荐,比较人性化,反编译结果更易于查看)。
反编译后,方法对应的字节码如下(为了节省篇幅,只展示出和本文相关的部分):
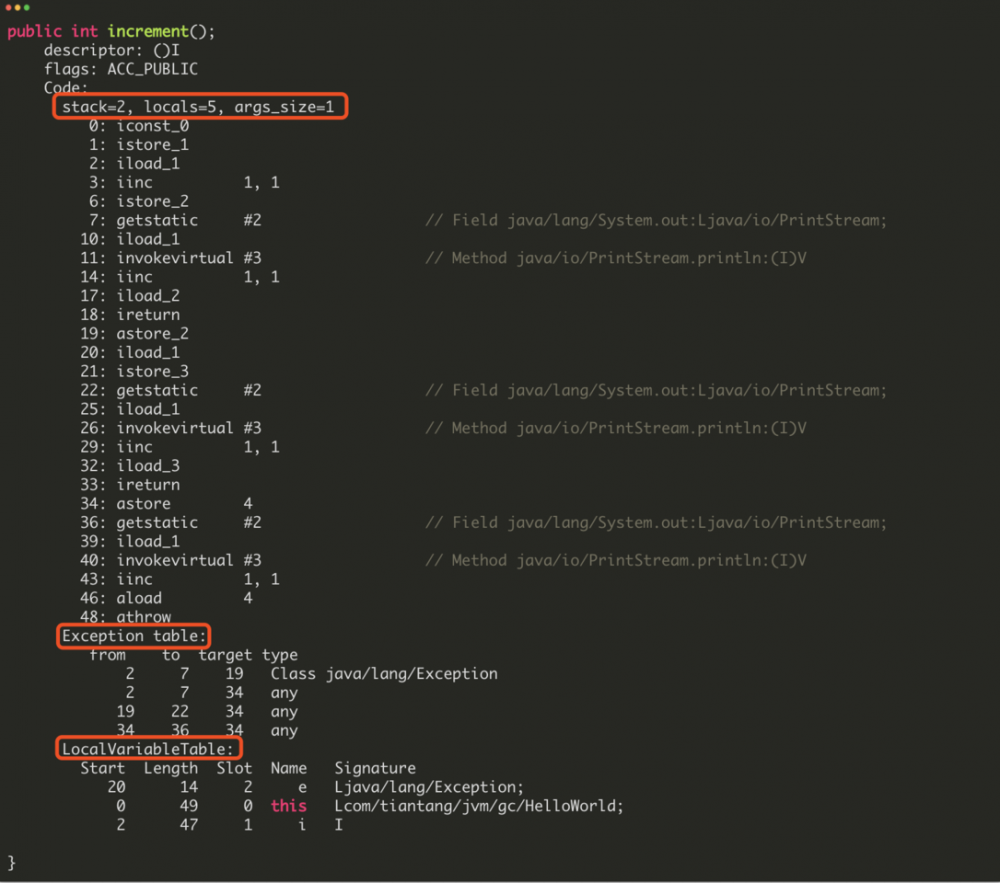
下面依次解释这些字节码的含义。
stack=2, locals=5, args_size=1
复制代码这一行表示的是操作数栈的大小为 2,局部变量表的大小为 5,参数的数量为 1(因为这是一个实例方法,所以 JVM 默认为每个方法传入一个 this 参数)。
再看下面这一行:
Exception table:
from to target type
2 7 19 Class java/lang/Exception
2 7 34 any
19 22 34 any
34 36 34 any
复制代码这一部分表示的是异常信息,当程序出现异常时,会按照这个异常表来执行程序。
该异常表的第一行表示的是如果在第 2-7 行出现了 「 java/lang/Exception 」 异常(这个异常就是我们在 catch 代码块中显示要捕获的异常),那么就跳转到 19 行开始执行。(注意:这里所说的行号,表示的字节码的行号,并不是我们在 Java 代码中行号)
如果 2-7 行出现了其他异常(超出了 java/lang/Exception 的范围),那么就会跳转到 34 行执行,这个 any 异常是编译器默认加上的。
如果在 19-22 行或者 34-36 行也出现了异常,那么也是跳转到 34 行执行。
LocalVariableTable:
Start Length Slot Name Signature
20 14 2 e Ljava/lang/Exception;
0 49 0 this Lcom/tiantang/jvm/gc/HelloWorld;
2 47 1 i I
复制代码这一部分信息描述的是局部变量中的信息,可以看到,槽位索引为 0 的地方存储的是 this,索引为 1 的地方存储的是变量 i,索引为 2 的地方存储的是异常信息 e。
而在前面我们看到的局部变量表的最大大小为 5,而这里只描述了 3 个变量,那还有 2 个变量是什么呢?别急,这一点放到后面再解释。
上面解释了一些基本信息,下面正式进入正题,下面依次解释每一行字节码的含义。
0: iconst_0
1: istore_1
2: iload_1
3: iinc 1, 1
6: istore_2
复制代码-
第 0 行表示使用字节码指令 iconst 从常量池中将数字 0 加载到操作数栈中;
-
第 1 行表示使用字节码指令 istore_1 将操作数栈顶的数据存储到局部变量表索引为 1 的槽位中,从前面的分析中,我们知道了索引为 1 的槽位就是变量 i,所以第 0 行和第 1 行字节码的作用就是:int i = 0。(istore_n 表示含义的是,将操作数栈顶的数据保存到局部变量槽位索引为 n 的变量上)
-
第 2 行字节码 iload_1 表示的是将局部变量表槽位索引为 1 的变量加载到操作数栈中,也就是将变量 i 的值加载到操作数栈顶,由于 i 的值为 0,因此执行完该行字节码之后,操作数栈顶的元素为 0。(iload_n 表示的含义是,将局部变量槽位索引为 n 的变量加载进操作数栈顶)
-
第 3 行字节码 「 iinc 1,1 」 表示的是将槽位索引为 1 的变量的值加 1(iinc 字节码后面的跟了两个数字,第一个数字表示的是槽位索引,第二个数字表示自增的值),因此这一行的意思就是将局部变量表中的变量 i 的值加 1,那么执行完这一行以后,局部变量中 i 的值为 1。
-
第 6 行字节码 istore_2 表示的是将操作数栈顶的元素保存到局部变量表槽位索引为 2 的变量中,此时操作数栈顶的值是 0(第 2 行字节码 iload_1 加载的结果),因此索引为 2 的槽位上的存储的值为 0。 「 记住这个地方,后面会用到 」 。注意:此时局部变量表索引为 2 的槽位并不是代表 Exception e,后面才会代表。
「 总结起来,第 0 - 6 行字节码的作用就是将变量 i 的值先赋值为 0,然后再累加,将其变为 1,同时还在索引为 2 的地方存储了一个元素,值为 0 」 。等价于我们代码中的:
int i = 0;
try {
i++;
// 还没有return
}
复制代码有人可能会奇怪,为什么字节码的行号一下子从第 3 行变成了第 6 行?这是因为字节码指令 iinc 可以拆分为 3 个步骤:iload、iadd、istore,这 3 个步骤的含义是:先将数据从局部变量表加载进操作数栈,然后将数据进行累加操作,最后再将操作数栈顶的数据存回局部变量,因此占据了 3 行。
接着继续往下看:
7: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
10: iload_1
11: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
14: iinc 1, 1
17: iload_2
18: ireturn
复制代码-
第 7 行字节码表示的是调用 System.out 获取到 PrintStream 对象,同样这一行可以细分为几个步骤,因此下一行字节码的行号直接变成了第 10 行;
-
第 10 行字节码 iload_1 表示将槽位索引为 1 的数据加载进操作数栈,也就是将 i 的值加载到操作数栈顶,此时 i 的值为 1;
-
第 11 行字节码表示调用 PrintStream 的 println()方法,打印操作数栈顶的元素,也就是打印出 1。因此第 7-11 行字节码的作用就是等价于:
System.out.println(i);
复制代码-
第 14 行字节码又是 「 iinc 1,1 」 ,前面已经介绍了,它的作用就是将局部变量表槽位索引为 1 的元素的值加 1,也就是将变量 i 的值加 1,那么 i 的值就变成了 2;
-
第 17 行字节码表示从局部变量表索引为 2 的槽位上,将数据加载进操作数栈,此时槽位上存储的值为 0( 「 文章前面已经强调过了为什么是 0 」 ),因此操作数栈顶此时的值就变为了 0。
-
第 18 行字节码 ireturn 表示的是方法结束,并将操作数栈顶的元素返回出去,此时栈顶元素值为 0,因此方法最终的返回值为 0。
到这里,如果方法正常执行,不出现任何异常,那么就结束了,并返回 0。为什么是返回 0 而不是 1 呢? 「 从字节码中我们看到了,在 i 进行 i++之前,先将 i 的旧值 0 保存到了局部变量表中,然后再对 i 进行自增操作,最后在方法返回之前,先将保存的旧值 0 加载进操作数栈栈顶,然后再通过 ireturn 指令将操作数栈顶的数据返回。 」
为什么会执行 finally 中的代码呢?从字节码层面看, 「 当 try 代码块中的代码 i++对应的字节码在执行完成后并没有立即出现 ireturn 指令,而是先出现了 finally 代码块中代码对应的字节码内容,然后才出现 ireturn 指令,这是编译器在编译阶段自动生成的,因此会执行 finally 块中的代码 」 。
面试题已经解释清楚了,我们再继续往下看看后面的字节码内容,再看看 catch 代码块的执行逻辑。
如果在字节码的第 2 到 7 行出现了异常,且异常类型为 「 java/lang/Exception 」 或者是其子类型,那么就会跳转到第 19 行字节码开始执行。
19: astore_2
20: iload_1
21: istore_3
22: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
25: iload_1
26: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
29: iinc 1, 1
32: iload_3
33: ireturn
复制代码-
第 19 行的字节码指令 astore_2 表示将操作数栈顶的数据保存到局部变量表索引为 2 的槽位上,此时操作数栈顶的数据就是异常信息 e。注意,这里又出现了槽位索引为 2,还记得前面在代码正常执行过程中,也使用到了槽位 2,前面是将 i 的旧值保存到槽位 2 上,此时是将异常信息保存到槽位 2 上,从这一点看, 「 又再次验证了局部变量表上的槽位是可以重用的结论 」 。
-
第 20 行字节码就是将槽位索引为 1 的变量值加载进操作数栈顶,即 i 的值加载进操作数栈顶;
-
第 21 行字节码就是将操作数栈顶的值保存到槽位索引为 3 的地方;
-
「 第 22-29 行字节码对应的又是 finally 语句块中的内容,和前面一样 」 ,就不解释了;
-
第 32 行字节码就是将槽位索引为 3 的数据加载进操作数栈顶;
-
第 33 行就是将操作数栈顶的数据返回,方法结束。
总结起来就是,如果出现了类型为 「 java/lang/Exception 」 或者是其子类型的异常,那么就会先保存下 i 的值,然后再执行 finally 代码块的中代码,最后再返回操作数栈顶的值,也就是 i 的旧值。
如果在字节码的 2-7 行、或者 19-22 行、或者 34-36 行出现了异常,也就是说出现了超出了 「 java/lang/Exception 」 类型的异常、或者在 catch、finally 代码块中又出现了了异常、或者在处理异常时又出现了异常,那么就会接着往下执行如下字节码:
34: astore 4
36: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
39: iload_1
40: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
43: iinc 1, 1
46: aload 4
48: athrow
复制代码-
第 34 行字节码的意思是,将异常信息保存到局部变量索引为 4 的槽位上;
-
「 第 36-43 行字节码又是 finally 代码块中的内容 」 ;
-
第 46 行字节码的含义是,将局部变量表索引为 4 的数据加载进操作数栈顶,也就是将第 34 行保存的异常信息取出来;
-
第 48 行字节码的意思就是,将操作数栈顶的异常信息抛出,当前方法结束。
「总结来看,对于本文示例中,如果出现了 catch 代码块中无法捕获的异常,那么依旧会执行 finally 代码块中的内容,最后再将异常信息抛出,方法结束」。
本文花了一部分内容介绍了局部变量表和操作数栈,这两者是程序在执行过程中必不可少的内存结构,所有变量数据的变化以及字节码指令的操作对象,都离不开局部变量表和操作数栈。
本文花了很大的篇幅去介绍一道简单的面试题的答案,最终从字节码的角度解释了为什么返回值是 0,为什么 finally 语句块中的内容会被执行?
这是因为在执行 i++操作之前,先保存了 i 的旧值到局部变量的一个槽位中,然后再对 i 执行自增操作,最后将保存的旧值返回,即使在 finally 代码块中,对 i 的值进行了修改,也不会改变返回值。
而在 Java 代码的编译时期,编译器会将 finally 代码块中的代码所对应的字节码内容添加到 try、catch 以及其他异常处理的字节码内容中,因此无论方法是正常执行,还是出现能捕获的异常,亦或是无法捕获的异常,都会执行 finally 语句块中的代码。
掌握了 i++的原理,那么如果将题目换成++i,相信各位读者,在看过对应的字节码以后,应该就能明白返回值又是多少了。
public int increment() {
int i = 0;
try {
return ++i;
} catch (Exception e) {
return i;
} finally {
System.out.println(i);
i++;
}
}
复制代码
正文到此结束
热门推荐








相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

