高可用Hadoop平台-HBase集群搭建
1.概述
今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示:
- 基础软件的准备
- HBase介绍
- HBase集群搭建
- 单点问题验证
- 截图预览
那么,接下来我们开始今天的HBase集群搭建学习。
2.基础软件的准备
由于HBase的数据是存放在HDFS上的,所以我们在使用HBase时,确保Hadoop集群已搭建完成,并运行良好。若是为搭建Hadoop集群,请参考我写的《 配置高可用的Hadoop平台 》来完成Hadoop平台的搭建。另外,我们还需要准备好HBase的安装包,这里我所使用的HBase-1.0.1,Hadoop版本使用的是2.6.0,基础软件下载地址如下所示:
HBase安装包 《 下载地址 》
在准备好基础软件后,我们来介绍一下HBase的相关背景。
3.HBase介绍
在使用HBase的时候,我们需要清楚HBase是用来干什么的。HBase是一个分布式的、面向列的开源数据库,就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。它是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
接下来我们来看看HBase的使用场景,HBase有如下使用场景:
- 大数据量 (100s TB级数据) 且有快速随机访问的需求。
- 例如淘宝的交易历史记录。数据量巨大无容置疑,面向普通用户的请求必然要即时响应。
- 容量的优雅扩展。
- 大数据的驱使,动态扩展系统容量的必须的。例如:webPage DB。
- 业务场景简单,不需要关系数据库中很多特性(例如交叉列、交叉表,事务,连接等等)。
- 优化方面:合理设计rowkey。因为hbase的查询用rowkey是最高效的,也几乎的唯一生产环境可行的方式。所以把你的查询请求转换为查询rowkey的请求吧。
4.HBase集群搭建
在搭建HBase集群时,既然HBase拥有高可用特性,那么我们在搭建的时候要充分利用这个特性,下面给大家一个HBase的集群搭建架构图,如下图所示:

这里由于资源有限,我将HBase的RegionServer部署在3个DN节点上,HBase的HMaster服务部署在NNA和NNS节点,部署2个HMaster保证集群的高可用性,防止单点问题。下面我们开始配置HBase的相关配置,这里我使用的是独立的ZK,未使用HBase自带的ZK。
- hbase-env.sh
# The java implementation to use. Java 1.7+ required. export JAVA_HOME=/usr/java/jdk1.7 # Tell HBase whether it should manage it's own instance of Zookeeper or not. export HBASE_MANAGES_ZK=true
- hbase-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hbase.zookeeper.quorum</name> <value>dn1:2181,dn2:2181,dn3:2181</value> <description>The directory shared by RegionServers. </description> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/data/zk</value> <description>Property from ZooKeeper config zoo.cfg. The directory where the snapshot is stored. </description> </property> <property> <name>hbase.rootdir</name> <value>hdfs://cluster1/hbase</value> <description>The directory shared by RegionServers. </description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> <description>The mode the cluster will be in. Possible values are false: standalone and pseudo-distributed setups with managed Zookeeper true: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh) </description> </property> </configuration>
- regionservers
dn1 dn2 dn3 5.单点问题验证
在配置完成集群后,我们开始启动集群,需要注意的时,在启动集群之前确保各个节点之间的时间是同步的,或者时间差不能太大,若时间差太大,会导致HBase启动失败。下面我们在NNA节点输入启动命令,命令内容如下所示:
[hadoop@nna ~]$ start-hbase.sh 然后,我们在NNS节点上在启动一个HMaster进程,启动命令如下所示:
[hadoop@nns ~]$ hbase-daemon.sh start master 然后,我们在各个节点输入jps命令查看相关启动进程,各个节点分布的进程如下表所示:
| 节点 | 进程 |
| NNA | HMaster |
| NNS | HMaster |
| DN1 | RegionServer |
| DN2 | RegionServer |
| DN3 | RegionServer |
截图如下所示:
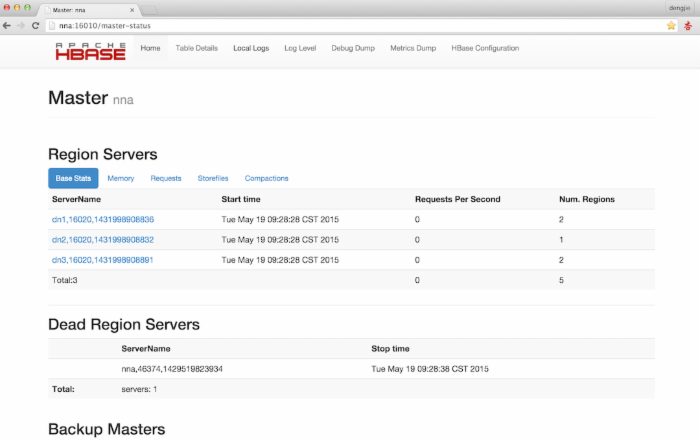
HBase的Web管理界面,默认端口是16010,这里我先启动的是NNA的HMaster,所提NNA节点HMaster对外提供服务,截图如下所示:
下面我kill掉NNA节点的HMaster进程,命令如下所示:
[hadoop@nna ~]$ kill -9 2542
然后,我们在查看相应的服务,由于我们使用了ZK,它会选择一个主服务出来,即NNS节点对外提供HMaster服务,截图如下所示:
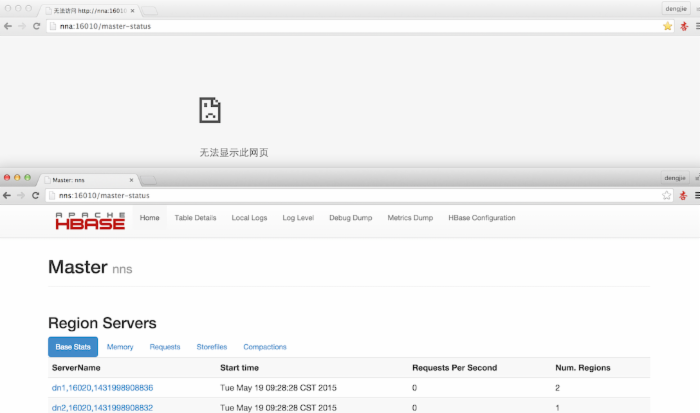
通过验证,HBase的高可用性正常,避免存在单点问题。
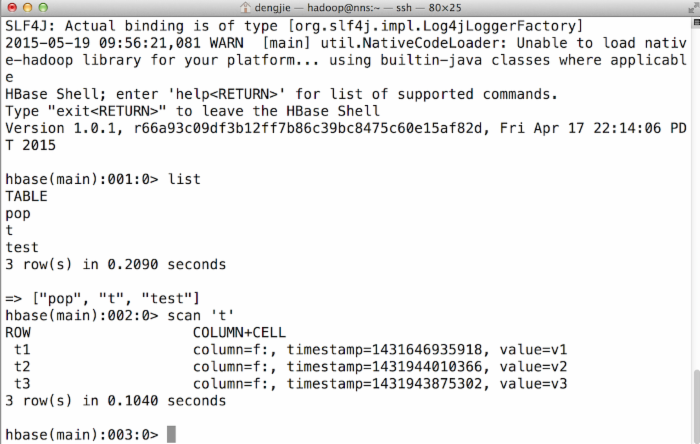
6.截图预览
下面给出HBase数据库的截图预览,如下图所示:
7.总结
这里需要注意的是,在搭建HBase集群的时候需要保证Hadoop平台运行正常,各个节点的时间差不能相差太大,最后时间能够同步。否则会导致HBase的启动失败。另外,如果在启动HBase集群时,提示不能解析HDFS路径,这里将Hadoop的core-site.xml和hdfs-site.xml文件复制到HBase的conf文件目录下即可。
8.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

