聊聊原子操作类AtomicInteger
什么需要AtomicInteger原子操作类?
对于Java中的运算操作,例如自增或自减,若没有进行额外的同步操作,在多线程环境下就是线程不安全的。num++解析为num=num+1,明显,这个操作不具备原子性,多线程并发共享这个变量时必然会出现问题。测试代码如下:public class AtomicIntegerTest {
private static final int THREADS_CONUT = 20;
public static int count = 0;
public static void increase() {
count++;
}
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_CONUT];
for (int i = 0; i < THREADS_CONUT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(count);
}
}要是换成volatile修饰count变量呢?
顺带说下volatile关键字很重要的两个特性:- 保证变量在线程间可见,对volatile变量所有的写操作都能立即反应到其他线程中,换句话说,volatile变量在各个线程中是一致的(得益于java内存模型—"先行发生原则");
- 禁止指令的重排序优化;
public class AtomicIntegerTest {
private static final int THREADS_CONUT = 20;
public static volatile int count = 0;
public static void increase() {
count++;
}
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_CONUT];
for (int i = 0; i < THREADS_CONUT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(count);
}
}用了AtomicInteger类后会变成什么样子呢?
把上面的代码改造成AtomicInteger原子类型,先看看效果import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerTest {
private static final int THREADS_CONUT = 20;
public static AtomicInteger count = new AtomicInteger(0);
public static void increase() {
count.incrementAndGet();
}
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_CONUT];
for (int i = 0; i < THREADS_CONUT; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(count);
}
}非阻塞同步
同步:多线程并发访问共享数据时,保证共享数据再同一时刻只被一个或一些线程使用。 我们知道,阻塞同步和非阻塞同步都是实现线程安全的两个保障手段,非阻塞同步对于阻塞同步而言主要解决了阻塞同步中线程阻塞和唤醒带来的性能问题,那什么叫做非阻塞同步呢?在并发环境下,某个线程对共享变量先进行操作,如果没有其他线程争用共享数据那操作就成功;如果存在数据的争用冲突,那就才去补偿措施,比如不断的重试机制,直到成功为止,因为这种乐观的并发策略不需要把线程挂起,也就把这种同步操作称为非阻塞同步(操作和冲突检测具备原子性)。在硬件指令集的发展驱动下,使得 "操作和冲突检测" 这种看起来需要多次操作的行为只需要一条处理器指令便可以完成,这些指令中就包括非常著名的CAS指令(Compare-And-Swap比较并交换)。《深入理解Java虚拟机第二版.周志明》第十三章中这样描述关于CAS机制: 所以再返回来看AtomicInteger.incrementAndGet()方法,它的时间也比较简单
所以再返回来看AtomicInteger.incrementAndGet()方法,它的时间也比较简单
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}/**
* Atomically sets the value to the given updated value
* if the current value {@code ==} the expected value.
*
* @param expect the expected value
* @param update the new value
* @return true if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}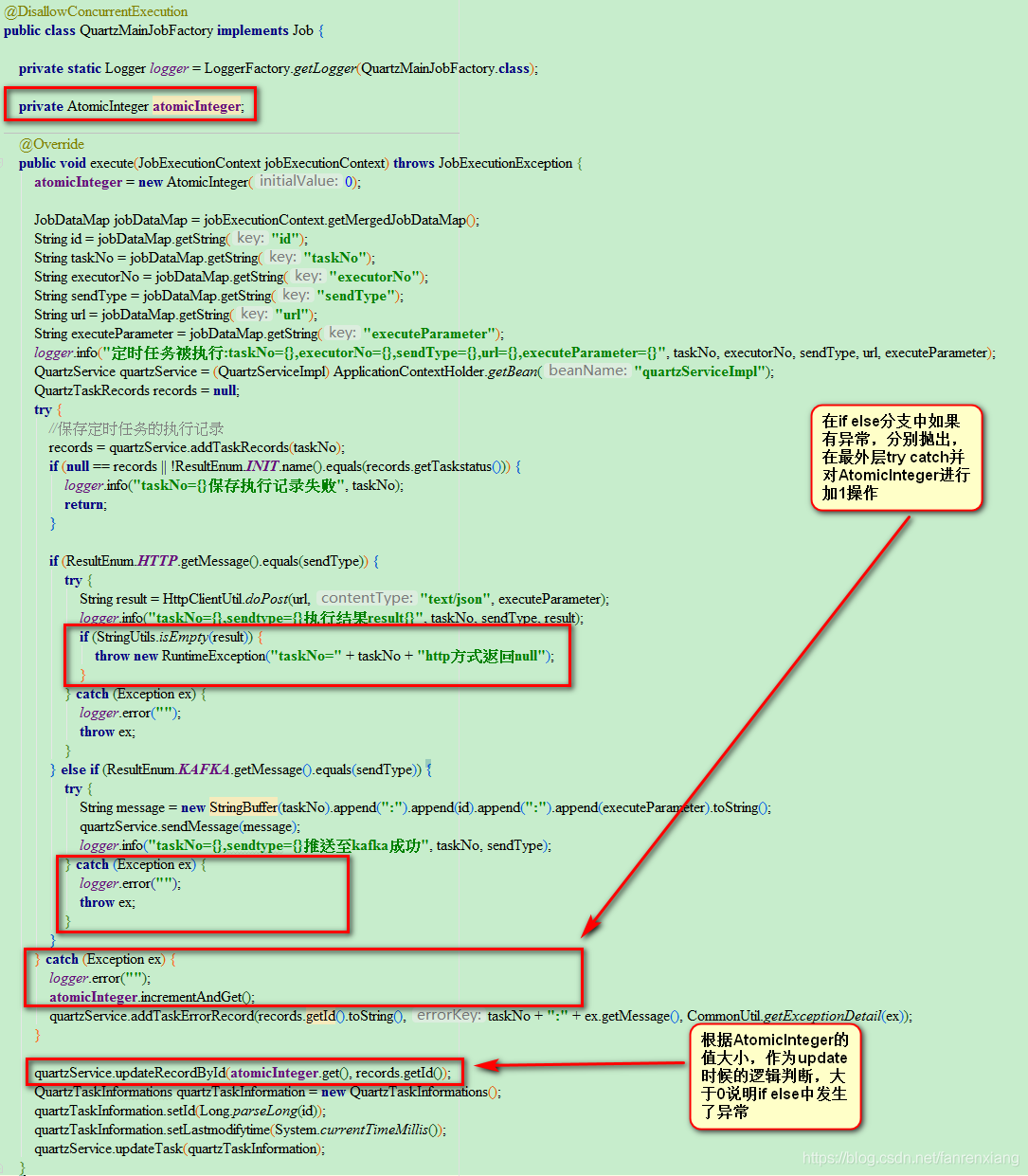
补充如下内容:
原子类相比于普通的锁,粒度更细、效率更高(除了高度竞争的情况下) 如果对于上面的示例代码中使用了thread.yield()之类的方法不清晰的,可以直接看下面的代码压测:public class AtomicIntegerTest implements Runnable {
static AtomicInteger atomicInteger = new AtomicInteger(0);
static int commonInteger = 0;
public void addAtomicInteger() {
atomicInteger.getAndIncrement();
}
public void addCommonInteger() {
commonInteger++;
}
@Override
public void run() {
//可以调大10000看效果更明显
for (int i = 0; i < 10000; i++) {
addAtomicInteger();
addCommonInteger();
}
}
public static void main(String[] args) throws InterruptedException {
AtomicIntegerTest atomicIntegerTest = new AtomicIntegerTest();
Thread thread1 = new Thread(atomicIntegerTest);
Thread thread2 = new Thread(atomicIntegerTest);
thread1.start();
thread2.start();
//join()方法是为了让main主线程等待thread1、thread2两个子线程执行完毕
thread1.join();
thread2.join();
System.out.println("AtomicInteger add result = " + atomicInteger.get());
System.out.println("CommonInteger add result = " + commonInteger);
}
} 如何把普通变量升级为原子变量?主要是AtomicIntegerFieldUpdater<T>类,参考如下代码:
如何把普通变量升级为原子变量?主要是AtomicIntegerFieldUpdater<T>类,参考如下代码:
/**
* @description 将普通变量升级为原子变量
**/
public class AtomicIntegerFieldUpdaterTest implements Runnable {
static Goods phone;
static Goods computer;
AtomicIntegerFieldUpdater<Goods> atomicIntegerFieldUpdater =
AtomicIntegerFieldUpdater.newUpdater(Goods.class, "price");
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
phone.price++;
atomicIntegerFieldUpdater.getAndIncrement(computer);
}
}
static class Goods {
//商品定价
volatile int price;
}
public static void main(String[] args) throws InterruptedException {
phone = new Goods();
computer = new Goods();
AtomicIntegerFieldUpdaterTest atomicIntegerFieldUpdaterTest = new AtomicIntegerFieldUpdaterTest();
Thread thread1 = new Thread(atomicIntegerFieldUpdaterTest);
Thread thread2 = new Thread(atomicIntegerFieldUpdaterTest);
thread1.start();
thread2.start();
//join()方法是为了让main主线程等待thread1、thread2两个子线程执行完毕
thread1.join();
thread2.join();
System.out.println("CommonInteger price = " + phone.price);
System.out.println("AtomicInteger price = " + computer.price);
}
}/**
* @description 压测AtomicLong的原子操作性能
**/
public class AtomicLongTest implements Runnable {
private static AtomicLong atomicLong = new AtomicLong(0);
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
atomicLong.incrementAndGet();
}
}
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(30);
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
es.submit(new AtomicLongTest());
}
es.shutdown();
//保证任务全部执行完
while (!es.isTerminated()) { }
long end = System.currentTimeMillis();
System.out.println("AtomicLong add 耗时=" + (end - start));
System.out.println("AtomicLong add result=" + atomicLong.get());
}
}/**
* @description 压测LongAdder的原子操作性能
**/
public class LongAdderTest implements Runnable {
private static LongAdder longAdder = new LongAdder();
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
longAdder.increment();
}
}
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(30);
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
es.submit(new LongAdderTest());
}
es.shutdown();
//保证任务全部执行完
while (!es.isTerminated()) {
}
long end = System.currentTimeMillis();
System.out.println("LongAdder add 耗时=" + (end - start));
System.out.println("LongAdder add result=" + longAdder.sum());
}
}正文到此结束
- 本文标签: AtomicInteger
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

