Netty--Bytebuf的深入分析
本文的思路是先学习JDK ByteBuffer ,然后再看看Netty的 Bytebuf 是如何解决这类问题的。
JDK ByteBuffer
关系与分类
JDK的 ByteBuffer 继承关系图如下:
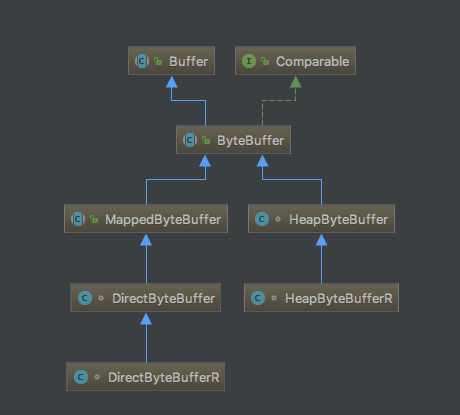
其中
- HeapByteBuffer :缓冲区分配在JVM堆中,由Java虚拟机回收,当网络通信时需要先拷贝到直接内存,然后再由操作系统操作。
- DirectByteBuffer :缓冲区分配在直接内存中,因此在网络请求时就可以避免来回内存间的拷贝,缺点是内存回收麻烦,其内部通过虚引用来控制内存,当该类被回收时(full gc),虚引用触发回收逻辑,使用
java.nio.DirectByteBuffer.Deallocator#run主动释放该区域内存。
设计思想
ByteBuffer 本质上是对 byte[] 数组的读取或者写入操作,在 ByteBuffer 中有以下四个数组指针标记,用于读写模式下数据的控制。
清单1:ByteBuffer数组指针
private int mark = -1; // 标记位置开始点,默认为--1也就是最开始。 private int position = 0; // 读取或写入的下一个位置,也就是当前操作的起始位置。 private int limit; // 写入模式下等于capacity,表示可写范围,读取模式下等于写入模式下的position,表示可读范围。 private int capacity; // 缓冲区容量,因为无法扩容,因此创建成功后不可变。
写操作
写入操作主要是 position 指针的变化,写入时不会主动扩容,因此有一定容量上线,这个在流式的tcp传输中很不好用。
清单2:ByteBuffer写入示例
@Test(expected = BufferOverflowException.class)
public void testBufWrite() {
// 1 需要主动分配,默认是分配在堆内存中
ByteBuffer buffer = ByteBuffer.allocate(33);
buffer.putLong(1L);
// capacity = 33 limit = 33 position=8
buffer.putLong(1L);
// capacity = 33 limit = 33 position=16
buffer.putLong(1L);
// capacity = 33 limit = 33 position=24
buffer.putLong(1L);
// capacity = 33 limit = 33 position=32
// 上面四个long已经占用32个byte,因此这里再次放入会直接抛异常
buffer.putLong(1L);
}
读操作
读操作是由写操作转换而来,也就是 flip() 方法的调用,该方法所做的事情是 limit=position,position=0,mark=-1 ,可以从下方代码更好的理解这个转换的意义。
清单3:ByteBuffer读取示例
@Test(expected = BufferUnderflowException.class)
public void testRead() {
// 1 需要主动分配,默认是分配在堆内存中
ByteBuffer buffer = ByteBuffer.allocate(33);
buffer.putLong(1L);
// capacity = 33 limit = 33 position=8
buffer.putLong(1L);
// capacity = 33 limit = 33 position=16
buffer.putLong(1L);
// capacity = 33 limit = 33 position=24
buffer.putLong(1L);
// capacity = 33 limit = 33 position=32
// 切换为读模式
buffer.flip();
// capacity = 33 limit = 32 position=0,此时最多可读32个字节
buffer.getLong();
// capacity = 33 limit = 32 position=8
// 再次切换
buffer.flip();
// capacity = 33 limit = 8 position=0
}
其他辅助操作
- rewind() :操作之后可重读或者重写,本质上是position指向0。
- clear() : 相当于再次初始化该buffer,position=0,limit=capacity,mark=-1
- compact() : 其与clear不同的是需要先把buf中未读的数据拷贝到数组前面,然后写入时不会覆盖未读数据。
- mark() : 标记位置
- reset() : 与mark相对应,可以让position指向mark
Netty ByteBuf
相比JDK的 ByteBuffer ,netty的 ByteBuf 主要是对其功能的一种增强。在使用JDK的 ByteBuffer 时会存在以下问题:
- 无法自动扩容,对于流式协议很不友好。
- 读写耦合在一起,需要主动切换,当其作为参数来回传递时会导致业务不清晰。
那么netty的增强主要是为了解决这些问题,具体解决策略下面慢慢分析。
如何自动扩容?
无论是哪种 Buf ,其底层都是维护着一个 byte[] 数组,因此自动扩容操作则需要在写入时判断剩余容量是否足矣写入,不足则主动去扩容(数组的拷贝),然后再次写入,类似 ArrayList 的扩容逻辑。
清单4:ByteBuf写入扩容
@Override
public ByteBuf writeLong(long value) {
// 写入前确保容量充足,充足则写入
ensureWritable0(8);
_setLong(writerIndex, value);
writerIndex += 8;
return this;
}
从分配策略来看主要有两种,对于堆内存则是数组拷贝。
清单4:ByteBuf堆内存扩容策略
@Override
protected void memoryCopy(byte[] src, int srcOffset, byte[] dst, int dstOffset, int length) {
if (length == 0) {
return;
}
System.arraycopy(src, srcOffset, dst, dstOffset, length);
}
对于直接内存扩容,原理也类似,这里是获取到两个buf的直接内存地址,然后使用 Unsafe 提供的拷贝方法拷贝指定字节的数据。
清单5:ByteBuf直接内存扩容策略
@Override
protected void memoryCopy(ByteBuffer src, int srcOffset, ByteBuffer dst, int dstOffset, int length) {
if (length == 0) {
return;
}
if (HAS_UNSAFE) {
PlatformDependent.copyMemory(
PlatformDependent.directBufferAddress(src) + srcOffset,
PlatformDependent.directBufferAddress(dst) + dstOffset, length);
} else {
// We must duplicate the NIO buffers because they may be accessed by other Netty buffers.
src = src.duplicate();
dst = dst.duplicate();
src.position(srcOffset).limit(srcOffset + length);
dst.position(dstOffset);
dst.put(src);
}
}
一般提供自动扩容逻辑必然要提供收缩逻辑,不然无限的扩下去最终只是浪费内存,举个例子,一个流数据进来,使用 ByteBuf 边读边写,那么在这个过程中也不断扩容,读写指针全部往后移动,如果一直扩容下去,最终这个byte[]数组则会非常庞大,因此环中思路已经读过的数组区域是不是可以释放掉呢?
Netty的 ByteBuf 提供了 discardReadBytes() 方法,该方法释放的原理是把未读取的内容移动到 byte[] 数组开头,以此来达到内存复用的逻辑。要注意数组的移动也会产生相当的消耗,尤其是读写指针中间有相当大段的内容时。
如何解决读写耦合?
JDK的 ByteBuffer 难以使用的本质原因是其内部的数组指针承担多个角色,不符合单一职责原则,比如 limit 在写入时等于 capacity ,在读取时则等于写入的 position ,而每次切换 position 都要清零,那么因为这一层逻辑存在导致对外很具有迷惑性,那么本质原因就是承担了多个角色的职责。(个人理解)
那么Netty的解决思路就是分离这种职责,在Netty的 ByteBuf 中主要有以下数组指针
清单6:ByteBuf数组指针
int readerIndex; // 当前读到的位置 int writerIndex; // 当前写入到的位置 private int markedReaderIndex; // 用于标记 mark private int markedWriterIndex; // 用于标记 mark private int maxCapacity; // 扩容上限
其本质上是把 limit 与 position 所承担责任进行了简化与分离。
写操作
写操作一方面需要考虑自动扩容,一方面会更改写指针的位置。
清单7:ByteBuf写操作指针变化
@Test
public void testWrite() {
// 分配个10byte的容量
ByteBuf buf = Unpooled.buffer(10);
// array[]=10 readerIndex=0 writerIndex=0
buf.writeLong(1L);
// readerIndex=0 writerIndex=8
buf.writeLong(1L);
// array[]=64 readerIndex=0 writerIndex=16
buf.writeLong(1L);
// array[]=64 readerIndex=0 writerIndex=24
buf.writeLong(1L);
// array[]=64 readerIndex=0 writerIndex=32
}
读操作
读操作只会更改读指针,当读指针与写指针相遇时,证明已经读完。
清单8:ByteBuf读操作指针变化
@Test(expected = IndexOutOfBoundsException.class)
public void testRead() {
// 分配个10byte的容量
ByteBuf buf = Unpooled.buffer(10);
// array[]=10 readerIndex=0 writerIndex=0
buf.writeLong(1L);
// readerIndex=0 writerIndex=8
buf.writeLong(1L);
// array[]=64 readerIndex=0 writerIndex=16
buf.writeLong(1L);
// array[]=64 readerIndex=0 writerIndex=24
buf.readLong();
// array[]=64 readerIndex=8 writerIndex=24
buf.readLong();
// array[]=64 readerIndex=16 writerIndex=24
buf.readLong();
// array[]=64 readerIndex=24 writerIndex=24
// 已经读完,再次读取则会抛异常
buf.readLong();
}
如何实现零拷贝?
当读取数据需要在应用态与内核态相互转换,涉及到操作系统的上下文切换,数据来回拷贝等不必要的损耗,所谓的零拷贝技术则是避免这些问题,直接在内核态中完成数据的转移,避免了上下文切换。这是操作系统层面的零拷贝。
对于Netty来说,其零拷贝不太一样,Netty所定义的零拷贝实际上侧重点都是在用户态,他的零拷贝更加偏向数据操作时不会产生复制,而是直接引用数据,本质上是底层 byte[] 数组的复用。
Netty 的 Zero-copy 体现在如下几个个方面:
- Netty 提供了 CompositeByteBuf 类, 它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝.
- 通过 wrap 操作, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作.
- ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝.
- 通过 FileRegion 包装的FileChannel.tranferTo 实现文件传输, 可以直接将文件缓冲区的数据发送到目标 Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题.
另外值得一提的是 CompositeByteBuf 这个类,该类运用了组合设计模式,当两个Buf想要合并时直接组合在一起,这种设计相当值得学习,更多分析可以参考我另一篇博文: 设计模式–组合模式的思考
如何高效的内存释放?
ByteBuf 在I/O中是一个经常被用到的角色,假设分配的堆内存,那么就依赖JVM的垃圾回收算法回收,假设分配在直接内存,则回收方式为full gc,那么纯依赖full gc释放的方式肯定不可取,在JDK的 ByteBuffer 实现当中还依赖虚引用,当对象被回收时触发虚引用的逻辑,清理相关内存。在Netty的 ByteBuf 中则是通过引用计数方式来实现内存回收。
Netty的 ByteBuf 实现了 io.netty.util.ReferenceCounted 接口,该接口主要提供了以下方法
清单9:引用计数接口
public interface ReferenceCounted {
int refCnt();
/**
* 引用数增加
*/
ReferenceCounted retain();
/**
* 引用数减少
*/
boolean release();
}
那么随之关联的问题就有很多了。
1. 引用数什么时候增加?
当 ByteBuf 被创建时, refCnt 默认为1,代表被引用,当该 ByteBuf 被copy或者slice时,其本质底层都是统一数组,因此会调用 retain() 方法,让引用数自增。
2. 引用数什么时候释放?
ByteBuf 是在Handler中来回传递的,在 InBound Message 中,Netty会在链中添加一个 TailContext ,该类会主动调用 release() 方法释放掉内存。在 OutBound Message ,Netty会在链中添加一个 HeadContext ,该类同样会调用 release() 方法释放掉内存。
最后按照Netty的规则,当引用数归0时,内存则会被回收。
3. 被主动释放前对象已经被gc回收
在直接内存分配的话,那么对象本身是在堆内存分配,那么就会出现对象被回收,但是直接内存中没有被回收的情况,那么此时就属于内存泄漏了,这个时候除了依赖full gc之外,Netty还实现了一套内存检测机制。
Netty的内存检测默认从buf中抽取1%的数据进行跟踪,如果发生泄漏将会打出日志警告,具体原理可以看参考链接中的分析,这里不过多的深入。
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

