Java 8 知识归纳(一)—— 流 与 Lambda
Stream API 和 Collection API 的行为差不多,但 Collection API 主要为了 访问和存储数据 ,而 Stream API 主要用于描述对 数据的计算 。
经典的 Java 程序只能利用单核进行计算,流提供了多核处理数据的能力。但前提是传递给 Stream API 的方法不会 互动 (即有可变的共享对象)时,才能多核工作。
三、Lambda
Lambda表达式由 参数列表 、 箭头 和 主体 组成:

四、函数式接口
函数式接口指只定义一个抽象方法的接口
注:哪怕有再多默认方法,只要接口中只定义了 一个抽象方法 ,它仍然是函数式接口。
Lambda允许你直接以内联的形式为函数式接口的抽象方法提供实现,并把其作为函数式接口的实例。
FunctionalInterface 注解
@FunctionalInterface 用于表示该接口为函数式接口。如果它不是函数式接口的话,编译器将返回一个提示原因的错误。
注: @FunctionalInterface 不是必需的,但最好为函数式接口都标注 @FunctionalInterface .
函数描述符
函数式接口的 抽象方法的基本签名 本质上就是 Lambda 表达式的签名。 Java8 将这种抽象方法叫作 函数描述符 。
Runnable 接口的 run 方法即不接受任何参数也不返回,其函数描述符为: () -> void 。 该函数描述符代表了函数列表为空且返回void的函数。
Scala 、 Kotlin 等语言在其类型系统中提供 显式的类型注释 来描述函数的类型(即函数类型)
| 函数接口 | 函数描述符 | 基本类型特化 |
|---|---|---|
Predicate<T> |
T -> boolean | IntPredicate LongPredicate , DoublePredicate |
Consumer<T> |
T -> void | IntConsumer , LongConsumer , DoubleConsumer |
Function<T,R> |
T -> R | IntFunction , IntToDoubleFunction , IntToLongFunction , LongFunction , LongToDoubleFunction , LongToIntFunction , DoubleFunction , ToIntFunction , ToDoubleFunction , ToLongFunction |
Supplier<T> |
() -> T | BooleanSupplier , IntSupplier , LongSupplier , DoubleSupplier |
五、方法引用
方法引用可以把现有方法像 Lambda 一样传递。
方法引用主要分三类:
- 指向 静态方法 的方法引用。(例如
Integer的parseInt方法,写作Integer::parseInt) - 指向 任意类型实例方法 的方法引用.(例如
String的length,写作String::length)- 适用于对象作为
Lambda表达式的一个参数。
- 适用于对象作为
- 指向现存对象或表达式实例方法的方法引用
- 适用于调用现存外部对象的方法。
- 适用于内部的私有方法。
注:构造函数、数组构造函数以及父类调用的方法引用形式比较特殊:
利用 类名 和 关键字 new 来生成构造方法的方法引用。
-
对于默认构造函数,可以使用
Supplier签名。Supplier<Apple> c1 = Apple::new; //等价于: Supplier<Apple> c1 = () -> new Apple(); 复制代码
-
对于存在参数的构造方法,可根据参数情况寻找适合的函数式接口的签名。
Function<Integer,Apple> c2 = Apple::new; //等价于: Function<Integer,Apple> c2 = (weight) -> new Apple(weight); 复制代码
六、流
从支持数据处理操作的源生成的元素序列 —— 流
流允许以声明性方式处理数据集合。还可以透明地并行处理,无须写任何多线程代码。
注:
- 流只遍历一次。遍历完后,流被消费了,需要重新从原始数据源那里再次获取一个新的流进行遍历。
- 只有触发终端操作,中间操作才会被执行。
- 中间操作一般都可以合并起来,在终端操作中一次性全部处理。
筛选
-
filter方法:接受一个 谓词 (一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。//输出结果:[1, 3, 0] List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6); numbers.stream() //筛选只小于4的元素 .filter(i -> i < 4) .collect(Collectors.toList()); 复制代码 -
distinct方法:依据流所生成元素的hashCode和equals方法,返回一个元素各异的流。(即返回一个没有重复元素的流)//输出结果为:[2,4] List<Integer> numbers = Arrays.asList(1,2,1,3,3,2,4); numbers.stream() .filter(i -> i % 2 == 0) //一共存在3个元素符合filter筛选,而这其中存在重复的2。distinct()只会返回2和4 .distinct() .collect(Collectors.toList()); 复制代码
流的切片
-
takeWhile方法:在第一个 不符合 要求的元素时停止处理。
//输出结果为:[1, 2, 3, 3]
//在初始列表中的数据已排序的情况下:
List<Integer> numbers = Arrays.asList(1,2,3,3,4,4,5,6);
numbers.stream()
//当发现第一个 i < 4 为 false 的元素时,则停止处理
.takeWhile(i -> i < 4)
.collect(Collectors.toList());
复制代码
-
dropWhile方法:在第一个 符合 要求的元素时停止处理,并返回所有剩余的元素。
//输出结果:[4, 4, 5, 6]
//在初始列表中的数据已排序(由高到低)的情况下:
List<Integer> numbers = Arrays.asList(1,2,3,3,4,4,5,6);
numbers.stream()
//当发现第一个i < 4 为 true 的元素时,则停止处理,并返回所有剩余的元素。
.dropWhile(i -> i < 4)
.collect(Collectors.toList());
复制代码
-
limit方法:返回一个不超过给定长度的流。- 如果流是有序的(如:源是
List),则按顺序返回前n个元素。 - 如果流是无序的(如:源是
set),则不会以任意顺序排序。 - 对于无限流,可以使用
limit将其变成有限流。
- 如果流是有序的(如:源是
//输出结果:[1, 3]
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
numbers.stream()
//筛选只小于4的元素
.filter(i -> i < 4)
//只返回前两个值
.limit(2)
.collect(Collectors.toList());
复制代码
-
shkip方法:返回一个扔掉前n个元素的流。- 如果流中元素不足
n个,则返回一个空流。
- 如果流中元素不足
//输出结果:[3, 0]
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
numbers.stream()
//筛选只小于4的元素
.filter(i -> i < 4)
//跳过第一个值
.skip(2)
.collect(Collectors.toList());
复制代码
映射
-
map方法:将流中的每一个元素映射成一个新的元素。
//输出结果:[6, 2, 4, 1]
List<String> languages = Arrays.asList("Kotlin","Go","Java","C");
languages.stream()
//将 字符串 转为 int
.map(String::length)
.collect(Collectors.toList());
复制代码
-
flatMap方法:把 一个流 中的 每一个值 转换成 另一个流 ,然后把 所有流 连接起来成一个流。- 简单说就是:把流中的 **元素(如:列表,数组)**化为新的流,或把流中的 元素 结合 **外部的列表 (数组) ** 化为新的流,再把新的流的元素整合到一个流中。
//输出结果:[K, o, t, l, i, n, G, J, a, v, C]
List<String> languages = Arrays.asList("Kotlin","Go","Java","C");
languages.stream()
.map(str -> str.split(""))
//Arrays::stream 将 str.split("") 返回的字符数组转换为流,再由 flatMap 统一将这些流合并成一个流.最终:Stream<String[]> 转换为 Stream<String>,
//flatMap 本质也是对流的元素进行转换(map也是对流的元素进行转换)。将流的元素转换为新的流,再将其整合进一个流中。
.flatMap(Arrays::stream) // 等价于:flatMap(strArray -> Arrays.stream(strArray))
.distinct()
.collect(Collectors.toList());
复制代码
练习:
1、返回所有对数
给定列表 [ 1,2,3 ] 和 列表 [ 3, 4 ] ,返回 [ (1,3) , (1,4) , (2,3) , (2,4) , (3,3) , (3,4) ]
//输出结果:[ (1,3) , (1,4) , (2,3) , (2,4) , (3,3) , (3,4) ]
List<Integer> numbers1 = Arrays.asList(1,2,3);
List<Integer> numbers2 = Arrays.asList(3,4);
List<int[]> pairs =
numbers1.stream()
//将其扁平化为一个流
.flatMap(i ->
numbers2.stream()
//将其转换为一个数组,并返回这个流
.map(j -> new int[]{i,j})
).collect(Collectors.toList());
复制代码
查找与匹配
-
anyMatch方法:检查流中是否 至少有一个 元素匹配给定的谓词。
//输出结果:true List<Integer> numbers = Arrays.asList(1,2,3,5,6,8); numbers.stream().anyMatch(i -> i > 3); 复制代码
-
allMatch检查谓词是否匹配所有元素。 -
allMatch方法:检查流中全部元素都 匹配 给定的谓词。
//输出结果:true List<Integer> numbers = Arrays.asList(1,2,3,5,6,8); numbers.stream().allMatch(i -> i < 10); 复制代码
-
noneMatch方法:检查流中全部元素都 不匹配 给定的谓词。( 与allMatch相对 )
//输出结果:true List<Integer> numbers = Arrays.asList(1,2,3,5,6,8); numbers.stream().noneMatch(i -> i > 10); 复制代码
-
findAny方法:返回当前流中的任意元素。
List<Apple> inventory = Arrays.asList(
new Apple(80,"green"),
new Apple(155, "green"),
new Apple(120, "red"));
Optional<Apple> apple = inventory.stream()
.filter(a -> a.getColor().equals("green"))
.findAny();
复制代码
-
findFirst方法:返回当前流中的第一个元素。
List<Apple> inventory = Arrays.asList(
new Apple(80,"green"),
new Apple(155, "green"),
new Apple(120, "red"));
Optional<Apple> apple = inventory.stream()
.filter(a -> a.getColor().equals("green"))
.findFirst();
复制代码
注:
1、 anyMatch 、 allMatch 和 noneMatch 都属于终端操作。
2、 anyMatch 、 allMatch 、 noneMatch 、 findFirst 和 findAny 不用处理整,只要找到一个元素,就可以得到结果了。
3、 findAny 和 findFirst 同时存在的原因是 并行 。 findAny 在并行流中限制较少。
归约
将流中所有元素反复结合起来,从而得到一个值的 查询 ,可以被归类为 归约操作 。(用函数式编程语言的术语来说,这称为 折叠 )
reduce方法:接收的 Lambda 将列表中的所有元素进行处理并归约成一个新值。
有初始值:
接收一个 初始值 和 一个 BinaryOperator<T> 将两个元素结合起来产生一个新值。
T reduce(T identity, BinaryOperator<T> accumulator); 复制代码
无初始值:
一个 BinaryOperator<T> 将两个元素结合起来产生一个新值。
Optional<T> reduce(BinaryOperator<T> accumulator); 复制代码
- 求和
//输出值:36
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
//使用带初始值的reduce方法
int sum = numbers.stream()
.reduce(0,Integer::sum);//等价于 reduce(0,(a,b) -> a + b)
//或使用无初始值的reduce方法
Optional<Integer> sumOptional = numbers.stream().reduce(Integer::sum);
复制代码
- 最大值
Optional<Integer> maxOptional = numbers.stream().reduce(Integer::max); 复制代码
- 最小值
Optional<Integer> minOptional = numbers.stream().reduce(Integer::min); 复制代码
数值流
原先的归约求和代码中, Integet::sum 暗含装箱和拆箱的成本。 Stream API 提供了 原始类型流特化 ,专门支持处理数值流的方法。 Java8 引入原始类型特化接口解决数值流拆箱与装箱的问题: IntStream 、 DoubleStream 和 LongStream ,分别将流中的元素特化为 int 、 long 和 double 。
- 映射到数值流
mapToInt 、 mapToDouble 和 mapToLong 用于将流转换为特化流:
//输出值:36
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
int sum = numbers.stream()
.mapToInt(Integer::intValue)
.sum();
复制代码
- 转换回对象流
当需要把原始流转换成一般流时(如:把 int 装箱回 Integer ),可以使用 boxed 。
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
//使用 IntStrean 特化流
IntStream intStream = numbers.stream()
.mapToInt(Integer::intValue);
Stream<Integer> stream = intStream.boxed();
复制代码
- 默认值
OptionalInt
Optional也相应的提供原始类型特化版本: OptionalInt 、 OptionalLong 和 OptionalDouble 。
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
//使用 OptionalInt 特化Optional
OptionalInt maxNumber = numbers.stream()
.mapToInt(Integer::intValue)
.max();
复制代码
数值范围
IntStream 和 LongStream 提供产生生成数值范围的静态方法: range 和 rangeClosed 。
range 方法生成半闭区间(左闭右开), rangeClosed 方法生成闭区间。
IntStream.range(1,100)
.filter(n -> n % 2 == 0)
.count();
复制代码
构建流
- 由值创建流
静态方法 Stream.of 接受任意数量的参数,显式创建一个流。
//显式创建字符串流
Stream<String> strStream =Stream.of("Java","Kotlin","Go");
复制代码
静态方法 Stream.empty 创建一个空流。
Stream<String> strStream =Stream.empty(); 复制代码
- 由数组创建流
静态方法 Arrays.stream 将数组创建为一个流。
int[] numbers = {2,3,5,6,7};
int sum = Arrays.stream(numbers).sum();
复制代码
- 由文件生成流
java.nio.file.Files 中很多静态方法会返回一个流,以便利用 Stream API 处理文件等 I/O 操作。
如: Files.lines 返回一个由指定文件中的各行构成的字符串流:
long uniqueWords = 0;
//流会自动关闭,不需要额外try-finally操作
try(Stream<String> lines =
Files.lines(Paths.get("data.text"), Charset.defaultCharset())){
//统计有多少不重复的单词。
uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" ")))
.distinct()
.count();
}catch (IOException e){}
复制代码
- 由函数生成流:创建无限流
Stream API 提供了两个静态方法来从函数生成流: Stream.iterate() 和 String.generate()
不同于从集合创建的流,这两个静态方法创建的流没有固定大小,称为 无限流 。
迭代:
iterate 方法接收一个接受 一个初始值 作为 流的第一个元素 。再接收 一个Lambda 依次应用在每一个产生的新值上。
Stream.iterate(0,n -> n + 2)
.limit(10)
.forEach(System.out::println);
复制代码
Java 9 对 iterate 方法进行增加,接受多一个谓词作为判断迭代调用何时终止。(谓词作为第二参数传入)
IntStream.iterate(0,n -> n < 100,n -> n + 2)
.forEach(System.out::println);
复制代码
当然,也可以使用 takeWhile 对流执行短路操作( takeWhile 函数 Java9 开始支持):
IntStream.iterate(0,n -> n + 2)
.takeWhile(n -> n < 100)
.forEach(System.out::println);
复制代码
生成:
generate 接受一个 Supplier<T> 类型的 Lambda 提供新值。
Stream.generate(Math::random)
.limit(5)
.forEach(System.out::println);
复制代码
七、用流收集数据
流支持两种类型的操作: 中间操作 和 末端操作 。
- 中间操作可以相互链接起来,将一个流转换为另一个流。中间操作不会消耗流,目的是建立一个流水线。
- 末端操作会消耗流,以产生一个最终结果。
归约和汇总
-
Collectors工厂类提供了很多 归约 的静态工厂方法。-
Collectors.counting()用于统计总和。
//求总和 long count = menu.stream().collect(Collections.counting()); 复制代码
-
Collectors.maxBy和Collectors.minBy用来计算流中的最大值和最小值。
//求最大值 Optional<Dish> mostCalorieDish = menu.stream().collect( Comparator.maxBy( Comparator.comparingInt(Dish::getCalories) ) ); 复制代码 -
-
同时
Collectors类专门为 汇总 提供了一些工厂方法。-
Collectors.summingInt、Collectors.summingLong和Collectors.summingDouble分别用于对int、long和double进行求和。
int sumValue = menu.stream().collect(summingInt(Dish::getCalories)); 复制代码
-
Collectors.averagingInt、Collectors.averagingLong和Collectors.averagingDouble分别用于对int、long和double进行求平均值。
double avgValue = menu.stream().stream().collect(averagingInt(Dish::getCalories)); 复制代码
-
-
Collectors.joining工厂方法会对流中每一个对象应用toString方法得到所有字符串连接成一个字符串。
String nameStr = menu.stream().map(Dish::getName).collect(joining()); 复制代码
分组
Collections 的 groupingBy() 方法会把流中的元素分成不同的组。

操作分组的元素
- 过滤
如果在 groupingBy() 之前,使用 filter() 对流进行过滤操作,可能会造成键的丢失。
例如:
存在以下Map: { FISH = [ prawns, salmon], OTHER = [french fries, rice ], MEAT = [pork , beef, chicken] }
但如果在使用 filter() 后,再 groupingBy() 可能对某些键在结果映射中完全消失:
{ OTHER = [french fries, rice ], MEAT = [pork , beef, chicken] }
为此, Collectors 类提供了 filtering() 静态工厂方法,它 接受一个谓词对每一个分组中的元素执行过滤操作 。最后不符合谓词条件的键将得到空的列表:
{ FISH = [], OTHER = [french fries, rice ], MEAT = [pork , beef, chicken] }
Map<Dish.Type,List<Dish>> caloricDishesByType = menu.stream()
.collect( groupingBy(Dish::getType),
filtering(dish -> dish.getCalories() > 500,toList()))
复制代码
注:
使用重载的 groupingBy() 方法 和 filtering() 方法 :先分组再过滤;
先使用 filter() ,再使用 groupingBy() 方法:先过滤再分组。
- 映射
Collectors 提供 mapping 静态工厂方法,接受一个映射函数和另外一个 Collectors 函数作为参数。映射函数将分组中的元素进行转换,作为参数的 Collectors 函数会收集对每个元素执行该映射函数的结果。
Map<Dish.Type,List<String>> dishNamesByType = menu.stream().collect(
groupingBy(
Dish::getType,
mapping(
//将元素转换为其名字
Dish::getName,
//用于收集该组进行完映射的元素
Collectors.toList()
)
)
)
复制代码
Collectors 工具类也提供了 flatMapping ,跟 flatMap 类似的功能。
多级分组
同时 Collectors 工具类也提供了可以嵌套分组的 groupingBy() ,用于进行多级分组
注:
可以理解为在进行完第一次分组后,再对每一组元素进行再次分组。
groupingBy(f) ( f 是分类函数 ) 实际上是 groupingBy(f,toList()) 的简便写法。
Map<Dish.Type,Map<CaloricLevel,List<Dish>>> dishesByTypeCaloricLevel =
menu.stream().collect(
groupingBy(
Dish::getType,
groupingBy(dish -> {
if(dish.getCalories() <= 400)
return CaloricLevel.DIET;
else if(dish.getCalories() <= 700)
return CaloricLevel.NORMAL;
else
return CaloricLevel.FAT;
})
)
);
复制代码
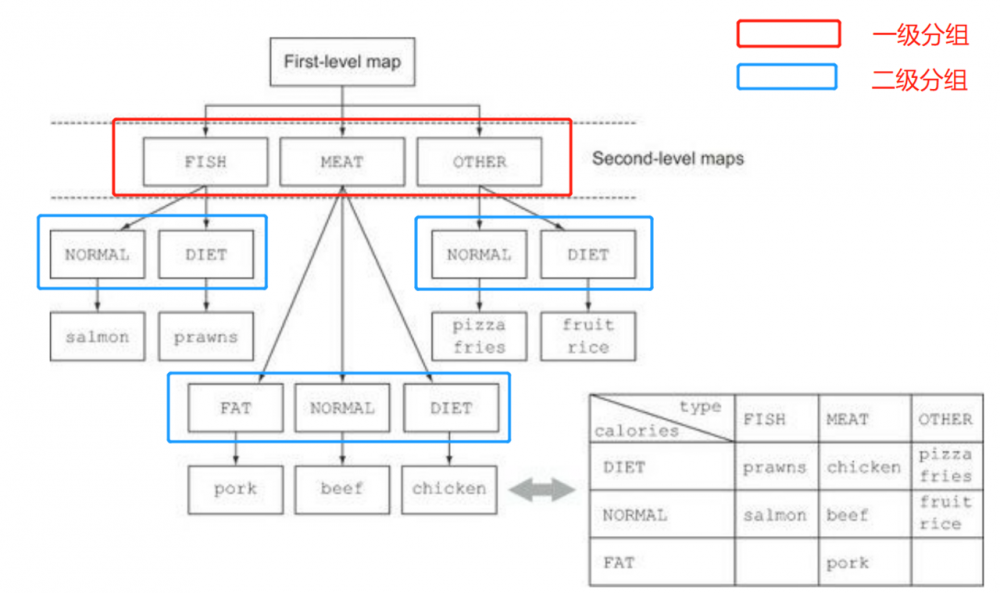
按子组收集数据
groupingBy() 的第二个收集器可以是任何类型。例如可以使用 counting() 收集器作为它的第二个参数,统计分组的数量:
Map<Dish.TYPE,Long> typesCount = menu.stream().collect( groupingBy(Dish::getType,counting()) ); 复制代码
得到以下的map: { MEAT = 3 , FISH = 2 , OTHER = 4 }
Map<Dish.Type,Dish> mostCaloricByType =
menu.stream().collect(
groupingBy(Dish::getTpye,
collectingAndThen(
//maxBy返回的是Optional类型对象
maxBy(comparingInt(Dish::getCalories)),
//当找到最大值后,会执行get操作。
Optional::get
)
)
);
复制代码
如果 menu 中没有某一类型的 Dish ,该类型不会对应一个 Optional.empty() 值,而且根本不会在 Map 的键中。所以转换函数 Optional::get 的操作是安全的。
分区
Collectors 工具类提供 partitionedMenu() 静态工厂函数来实现分区,分区是分组的 特殊情况 。由谓词作为分类函数,这意味着得到的分组 Map 的键类型是 Boolean ,最多分为 true 和 false 两组。
//将得到以下结果:
Map<Boolean,List<Dish>> partitionedMenu =
menu.stream().collect(
//分区函数
partitioningBy(
//分期的标准
Dish::isVegetarian
)
)
复制代码
同时 partitionedMenu() 也和 groupingBy() 类似,可以进行二级分区。
收集器接口
public interface Collector<T, A, R> {
//创建一个空的累加器
Supplier<A> supplier();
//将元素添加到结果容器
BiConsumer<A, T> accumulator();
//合并两个结果(定义了对流的各个子部分进行并行处理时,各个子部分归约所得的累加器如何合并)
BinaryOperator<A> combiner();
//对结果容器应用最终转换
Function<A, R> finisher();
//定义收集器的行为
Set<Characteristics> characteristics();
}
复制代码
泛型的定义如下:
T 表示流中要手机的项目的泛型。
A 表示累加器的类型。(累加器是收集过程中用于累积部分结果的对象)
R 表示收集操作得到的对象的类型。
以 ToListCollector 为例
public class ToListCollector<T> implements Collector<T, List<T>, List<T>> {
public ToListCollector() {}
//创建ArrayList对象作为累加器
public Supplier<List<T>> supplier() {
return ArrayList::new;
}
//利用add函数将流中的元素添加到列表中
public BiConsumer<List<T>, T> accumulator() {
return List::add;
}
//两个累加器(即两个ArrayList对象)进行相加
public BinaryOperator<List<T>> combiner() {
return (list, list2) -> {
list.addAll(list2);
return list;
};
}
//累加器进行最终的转换
public Function<List<T>, List<T>> finisher() {
//Function.identity()表示给什么返回什么,也就是不进行转换
//恒等
return Function.identity();
}
//定义收集器的行为
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH, Characteristics.CONCURRENT));
}
}
复制代码
Characteristics的三个枚举:
- UNORDERED —— 归约结果不受流中项目的遍历和累积顺序的影响。
- CONCURRENT—— accumulator 函数可以从多个线程同时调用,且该收集器可以并行归约流。(仅仅只是数据源无序时才会并行处理)
- IDENTITY_FINISH—— 表明完成器方法返回的函数是一个恒等函数,可以跳过。累加器对象会直接用作归约过程的最终结果。这也意味着,将累加器A不加检查的转换为结果R是安全的。
进行自定义收集,而不去实现 Collector
对于 IDENTITY_FINISH 的收集操作, Stream 重载的 collect 方法接受三个函数—— supplier 、 accumulator 和 combiner 。该 collect 方法创建的收集器的 Characteristics 永远是 Characteristics.IDENTITY_FINISH 和 Characteristics.CONCURRENT
List<Dish> dishes = menu.stream().collect(
//创建累加容器
ArrayList::new,
//将流元素添加到累加容器中
List::add,
//合并累加容器
List::addAll
);
复制代码
八、并行数据处理与性能
- 对顺序流调用
parallel()方法并不意味着流本身有任何实际的变化,它仅仅在 内部设置了一个boolean标志 ,表示你想让调用parallel()之后的所有操作都并行执行。对并行流调用sequential方法就可以把它变成顺序流。 - 并行流默认的线程数量等于你处理器的核数。
使用并行流时,考虑以下因素:
- 留意自动装箱和拆箱。(应尽量将其转为原始类型流)
- 对于较小数据量,无需使用并行流。
- 考虑流背后的数据结构是否容易分解。
- 部分操作本身在并行流上的性能比顺序流差。如:
limit和findFirst - 考虑合并 步骤的代价是大是小。
- 考虑操作流水线的总操作成本。当单个元素通过流水线的成本较高时,使用并行流比较好。
流的数据源和可分解性:
| 源 | 可分解性 |
|---|---|
ArrayList |
差 |
LinkedList |
差 |
IntStream.range |
极佳 |
Stream.iterate |
差 |
HashSet |
好 |
TreeSet |
好 |
九、 Collection API 的增强功能
Arrays.asList() 创建一个固定大小的列表,列表的元素可以更新,但不可以增加或删除。
Java 9引入以下工厂方法:
-
List.of——创建一个只读列表,不可set、add等操作。 -
Set.of—— 创建一个只读的Set集合。 -
Map.of—— 接受的列表中,以键值交替的方式创建map的元素。、- 当创建Map的键值对过多时,可以使用
map.ofEntries()和Map.entry()创建map.
import static java.util.Map.entry; Map<String,Integer> ageOfFriends = Map.ofEntries( entry("Raphael",30), entry("Olivia",25), entry("Thibaut",26) ); 复制代码 - 当创建Map的键值对过多时,可以使用
重载与变参
在 Java API 中, List.of 包含多个重载版本:
static <E> List<E> of(E e1); static <E> List<E> of(E e1, E e2); 复制代码
而不提供变参版本是因为需要额外的分配一个数组,这个数组被封装于列表中。使用变参版本的方法,就要负担分配数组、初始化以及最后进行垃圾回收的开销。(如果元素数量超过10个,实际调用的还是变参方法。)、
使用 List 、 Set 和 Map
-
removeIf()—— 移除集合中匹配指定谓词的元素。(该方法由Collection接口提供默认方法,List和Set都可用)-
//Collection.java //Predicate(谓词)的函数描述符是:(T) -> boolean default boolean removeIf(Predicate<? super E> filter) 复制代码
-
当使用for-each遍历列表,进行移除操作时,会导致
ConcurrentModificationException.因为遍历使用的迭代器对象和集合对象的状态同步。我们只能显示调用迭代器对象(Iterator对象)的remove方法。因此Java8提供removeIf方法,安全简便的删除符合谓词的元素。
-
-
replaceAll()—— 使用一个函数替换List或Map中的元素。(该方法由List接口提供默认方法)-
//List.java //UnaryOperator的函数描述符是:(T) -> T default void replaceAll(UnaryOperator<E> operator) 复制代码
-
该函数只是在列表内部进行同类型的转换,并没有创建新的列表。也就是说初始为
List<String>,函数执行完还是List<String>. -
//Map.java // BiFunction的函数描述符是:(K,V) -> V default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) 复制代码
-
-
sort()—— 对列表自身进行排序。(该方法由List接口提供默认方法)-
//List.java //Comparator的函数描述符是:(T,T) -> boolean default void sort(Comparator<? super E> c) 复制代码
-
-
forEach()—— List 和 Set,甚至是Map在Java8中都支持forEach方法。而遍历提供的便捷,特别是Map的遍历。-
//Iterable.java //Consumer(消费者)的函数描述符是:(T) -> void default void forEach(Consumer<? super T> action) //Map.java //BiConsumer(二元消费者)的函数描述符是:(T,U) -> void default void forEach(BiConsumer<? super K, ? super V> action) 复制代码
-
-
Entry.comparingByValue()和Entry.comparingByKey()—— 对Map的值或键进行排序。 -
Map.compute—— 使用指定的键计算新的值,并将其存储到Map中,并返回新值。。(指定一个key,再提供一个BiFunction,依据 key 和 旧值 ,计算新值。如果新值为null,则不会加入到Map中并将旧值移除。)-
//BiFunction的函数描述符是:(K,V) -> V default V compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) 复制代码
-
-
Map.computeIfAbsent—— 如果指定的键没有对应的值(没有该键或者该键对应的值是空),使用该键计算新的值,并添加到Map中(如果新值为null,则不会加入到Map中并将旧值移除。),并返回新值。-
//Function的函数描述符是:(K) -> V default V computeIfAbsent(K key,Function<? super K, ? extends V> mappingFunction) 复制代码
-
该方法对于值需要初始化时有用。比如向
Map<K,List<V>>添加一个元素( 初始化对应的ArrayList,并返回该值):map.computeIfAbsent("daqi", name -> new ArrayList<>()) .add("Java8") 复制代码
-
-
Map.computeIfPresent—— 如果指定的键在Map中存在,依据该键和旧值计算该键的新值,并将其添加到Map中。(如果新值为null,则不会加入到Map中,并将旧值移除。)-
//BiFunction的函数描述符是:(K,V) -> V default V computeIfPresent(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) 复制代码
-
-
Map.remove—— 重载版本的remove可以删除Map中某个键对应某个特定值的映射对。(即Key和Value都匹对上,才从Map中移除)-
default boolean remove(Object key, Object value) 复制代码
-
-
Map.replace—— 重载版本的replace可以仅在原有键对应某个特定的值时才进行替换。(即Key和Value都匹对上,才从Map中替换)-
default V replace(K key, V value) 复制代码
-
-
Map.merge—— 如果指定的键在Map中存在,依据该键和旧值计算该键的新值,并将其添加到Map中; 如果指定的键在Map中不存在,依据指定的value作为Key的值,并将其添加到Map中。-
//BiFunction的函数描述符:(V,V) -> V default V merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction) 复制代码
-
该函数可用于
Map的合并,或用于将Collector转换成Map.Map<String,Integer> language1 = new HashMap<>(); language1.put("Java",8); language1.put("Kotlin",1); Map<String,Integer> language2 = new HashMap<>(); language2.put("Java",11); language2.put("Go",1); //合并Map language1.forEach((key,value) -> { //Map的value可null,merge函数不允许value为null if (value != null) language2.merge(key,value,Integer::sum); }); 复制代码 -
static class Score{ private int score; private int studentId; private String studentName; public Score(int studentId, String studentName,int score) { this.score = score; this.studentId = studentId; this.studentName = studentName; } //get和set方法 } //Collector转换为Map(用途:统计) List<Score> languageList = new ArrayList<>(); languageList.add(new Score(1,"Java",80)); languageList.add(new Score(2,"Kotlin",90)); languageList.add(new Score(2,"Java",85)); languageList.add(new Score(1,"Kotlin",70)); Map<String,Integer> language3 = new HashMap<>(); //Collectors.toMap(Function<? super T, ? extends K>,Function<? super T, ? extends U>,BinaryOperator<U>)内部也是通过Map.merge()实现的。 languageList.stream().collect(Collectors.toMap(Score::getStudentId,Score::getScore,Integer::sum)); 复制代码
-
十、 重构
正文到此结束
- 本文标签: Word map Collection Apple 构造方法 key entity tar 函数式编程 Menu HashMap 遍历 HashSet 编译 final 删除 安全 IO 注释 静态方法 Collections src 处理器 IDE 本质 Java 9 stream java 参数 http cat NIO 代码 equals 实例 https dist scala 数据 id App lambda list 统计 线程 ORM 多线程 ArrayList DOM ip 同步 ACE UI 垃圾回收 CTO 限流 value core find Action API LinkedList parse rand tab consumer
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

