腾讯蓝鲸数据平台之告警系统
以下是我参与蓝鲸数据平台的建设过程中的一些心得体会,关于整个蓝鲸平台的更多内容,请见
http://mp.weixin.qq.com/s%3F__ ... ecac0
很多人在搞ELK,很多人也在搞STORM。更多人在用传统的Nagios,Zabbix等监控工具。Jason Dixon在2012就意识到这些工具的问题是每个人都想做到大而全,实际上我们更需要的是一对小二精的组件拼装成一个个性化的解决方案。推荐大家去看一下他的演讲视频: https://speakerdeck.com/obfusc ... in...

这是Jason Dixon所构想一个组件图。他认为不同的开源方案应该专注于提供好这些组件。
Caskey Dickson 也有同样的设想,并且提出目前的很多组件仍然是缺乏好的提供者的(比如海量metric存储和任意维度聚合): https://www.usenix.org/confere ... oring
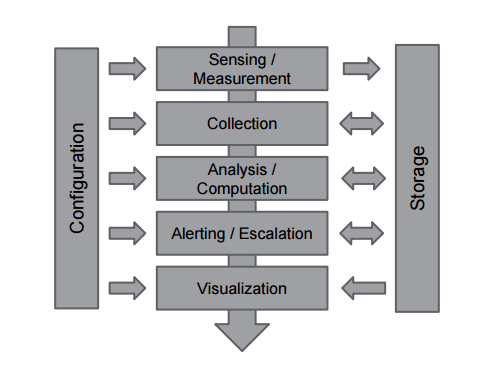
这是他在ppt里画的一个组件图,并且评价了一下主流的开源组件。
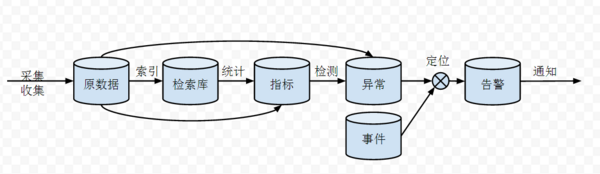
受到前辈们的影响,这个是我厂的一个告警平台的数据流图。下面按照顺序解释一下这个流程图中的各种组件:
- 采集/收集:数据可能来自于业务的db,可能来自于日志文件,可能是由业务程序内置上报的。通过各种手段采集收集到“原数据库”里。什么是“原数据库”?比如kafka队列。比如logstash上报前把数据汇总到的redis数据库。“原数据库”的存在是为了把分散的数据汇总到一处,方便后续的处理。
- 索引:索引主要是为了日志存在的。为了让日志可以检索,需要把日志数据进行切分,提取出字段和关键字录入到“检索库”里。这就是著名的ELK最擅长的事情。Logstash负责索引操作,Elasticsearch充当检索库的角色。
- 统计:指标库最常见的就是给每个ip存放一份cpu使用率的时间序列。对于这种情况,原数据采集了之后直接录入指标库就行了。另外一种比如是nginx的access
log,采集到之后需要经过统计才能得出某某url在5分钟内被访问了xx次的数据。统计最简单的形式比如statsd,复杂的可以用storm写自定义的流式计算任务,更复杂的甚至涉及机器学习,比如summo
logic。指标库一般使用的是opentsdb等时间序列数据库,但是我强烈推荐Elasticsearch: http://taowen.gitbooks.io/tsdb/content/ - 异常检测:传统的告警就是比对一个静态的阈值。对于错误率,访问延迟等指标用静态阈值确实是没有问题的。但是对于5分钟内的收入,访问人数等综合的业务指标很难用静态阈值去做检测异常。复杂的异常检测会利用曲线的时间周期性,和相关曲线之间的相关性去定义动态的阈值。etsy的skyline是开源组件里比较著名的一个。
- 告警:告警和异常检测是两个过程。不是每个异常都值得通知运维跟进处理(起码可以做一个频率收敛),也不是把原始异常以xx小于xx这样的形式告诉给运维就可以了(可以把告警相关的故障一起通知了)。这里个从异常到告警的过程需要做到确认这个异常是一个值得通知的告警,并且能够做一个初步的故障定位。最简单的定位的手段是就把其他部门的告警(比如网络部门的网络质量告警,安全部门的DDoS告警),以及流程单据(发布单)做为事件纳入事件库。通过查询事件库定位原因。
在这样的一个提下下,很多零散的工具做的事情被整合在了一起:
- 拨测:定时curl一下某个url,有问题就告警。这个是走 原数据=>直接录入为异常=>告警
- 日志集中检索:ELK的经典用法。走 原数据=>检索库
- 日志告警:5分钟Error大于xxx次告警。走 原数据=>实时统计出指标=>检测异常=>告警
- 指标告警:cpu使用率大于xxx告警。走 原数据=>录入到指标库=>检测异常=>告警
把不同的告警和监控策略整合到同一个数据管线的好处是简化了整体的架构,剔除了重复的模块(比如上报和原数据汇总等模块)。而且有利于各司其职,专业化纵深发展。目前开源组件还比较缺乏的有这么几块:
- 指标库需要海量存储海量聚合能力,开源的有 Druid.io Elasticsearch Crate.io 等
- 异常检测,缺乏真正实用的。算法其实不用很复杂
- 故障定位和收敛,缺乏真正实用的。Flapjack的实现太简单了,Riemann又太小众了
- 实时统计,缺乏成熟的解决方案。Storm就是一个底层的执行引擎,而Spark还缺少时间窗口等抽象。
- 日志自动分类,还没有开源工具可以做到 summo logic 那样的效果
- 自定义曲线和仪表盘:类似kibana的工具还是太少
我厂的监控告警平台当然是把这些都实现了。很多创业公司(比如刚冒出来的jut.io)也整合出了不错的完全解决方案。但是更多的小厂还是在用Nagios和Zabbix等传统的工具,再加上个ELK看日志。开源社区在方面还是大有可为的。说实话,这个东西卖钱不好卖。更多的公司还是会选择拿开源工具自己搭一个凑合用的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

