【微信分享】QingCloud周小四:Spark学习简谈
8月6日20:30,CSDN Spark微信用户群进行第六次讨论。在分享中, QingCloud 周小四从云计算给大数据带来的价值开始,为Spark的学习提出了一些指导意见,并分享了实践过程中的一些性能调优细节。
周小四 :2014年10月加入青云,主要负责数据服务的开发,当下已经实现了ZooKeeper、Kafka,Spark。之前,周小四在高德(阿里)做过半年大规模监控系统。在早期,周小四曾在IBM Tivoli工作了4年,美国学习工作了7年。
下为实录整理
其实算不上spark核心技术分享,在青云,我主要负责在云上把这些大数据平台提供给大家。所以今天主要想和大家聊聊两个部分:首先,云计算和大数据;其次,Spark初学者需要注意的一些事情。相信很多朋友还只是处在迈上Spark的道路上,艰难的技术道路上需要同行的陪伴,在这里就分享一些我们在Spark路上的一些心得。
云计算之于大数据
时下,相信很多人已经相信大数据基础平台运行在云上是大势所趋。如果目前还有人用物理机跑大数据,那么肯定需要再思考一些。谈到云上跑大数据,很多人会存在稳定性和性能问题担忧,其实这些都是不存在的。如果IaaS层足够好,平台设计周密,那些都不是问题。同时,云计算带来的好处是无法忽视的。我想了个最直白的比如,如果抗战时期有飞机大炮而不是小米加步枪的话,那么根本用不了8年。
这个比喻到云服务和物理机比喻也就是,如果在物理机上部署大数据平台,时间开销最起码按小时或者天计,如果部署几个节点的话可能还可以忍受,但是如果部署上百个节点肯定会令人疯狂。但是,如果到了云上,1到2分钟就可以完成一个集群的部署,同时还具备了可伸缩和自动伸缩的特性。
基于云的大数据平台实践
在云上做大数据平台,首先要充分利用云的特点。举个Hadoop副本因子的例子,大家都知道默认值是3个,但是在云上又该如何设置副本因子数量?
在Hadoop当初设计第3副本因子的时候,考虑的是2个副本所在的机架出问题,而把第3个副本放在另外机架上。但是到了云上,你根本不会清楚副本的存放在哪个机架上,因此这第3个副本意义就不大了,而去掉这个多余的副本大家都知道意味什么——节省三分之一空间,同时性能得到提升。
去掉一个副本后,带来的稳定性和高可用问题将由IaaS的实时副本保障。现在,基本上所有SaaS都提供了实时副本,而区别就在于谁的实时副本在出现灾难时自动恢复得快。
再举一个Spark主节点高可用问题的例子,这个当时研究的时候其实存在着很大的差异,官方文档推荐的方案是用Zookeeper管理多个主节点,但是故障切换时间是1到2分钟,完全无法接受。如果是这样的话,我会用替换主节点的方案,因为重建一个虚机的时间是几秒钟,加上Spark系统恢复不到1分钟,总共加起来也就是1分钟左右。好处也是显而易见,节省了3个zookeeper节点和至少1个Spark主节点。其实在云上做大数据平台有不少细节值得思考,跟物理机部署有很多的不同。
谈Spark的学习与实践
谈到Spark,其优势应该广为人知,这里不会多加叙述。但是,需要提醒的是,Spark比MapReduce快不仅是在内存计算上,它设计精妙之处是DAG。DAG是基于全局最优,而MapReduce只着眼于局部,因此即使是硬盘Spark也会快很多。其次,Spark设计并不是去替换 Hadoop,因为Spark没有存储,很多时候它需要和HDFS一起工作。
那么,剩下的就是要尽量避免shuffle和存什么样的数据格式到HDFS,这些都有讲究。其实,如果只是使用Spark并不难,但是调优却要耗费大量精力。基于Spark的应用程序开发与传统应用程序开发有着很大的区别——传统情况下,即使没有好的数据结构和算法也能写出work的东西,然而在Spark上却是完全行不通的,不是out of memory就是heartbeat timeout。在这种情况下,如果只是一味扩容其实并不可取,开发者首先需要搞清楚的是问题究竟出在哪儿。
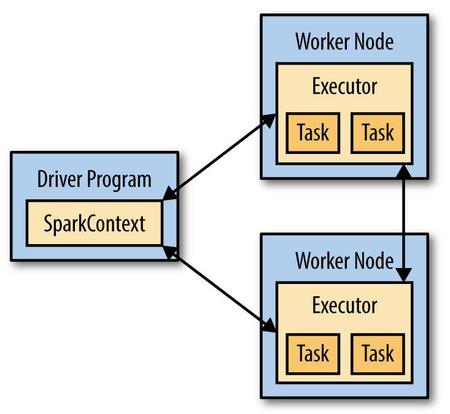
与Hadoop一样,Spark使用了一个Master/Slave架构,初学者需要注意的是driver和master可以是不同的节点,并且要理解压力都是在哪些节点上。学习它最好的方法就是云计算,加spark shell,如果有人喜欢python,建议用IPython,它的tab功能你会很喜欢的,下面看一张图片。
那个4040 driver提供的信息非常好,它能帮助查到很多问题。虽然不说是每一项,至少大部分需要理解是什么意思。在研究这个的时候,我发现它的lazy fashion用到极致,比如你persist一个RDD的时候,如果调用first,会发现只有一个partition被persist了,虽然RDD实际数据有很多partition。非常有意思。
还有就是内存的设置代表什么意思。Spark worker memory是节点能提供worker的最大内存,在申请executor内存的时候不能超过这个,超过这个值这个节点就不可用。
val executorMemory = conf.getOption("spark.executor.memory") .orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY"))) .orElse(Option(System.getenv("SPARK_MEM")).map(warnSparkMem)) .map(Utils.memoryStringToMb) .getOrElse(512) 这段代码表示了设置executor memory的优先级,前面的设置如果都没有,那么就是默认的512M,大家在设置的时候注意这个就行了。
最少限度shuffle
shuffle尽量避免,虽然不可能完全消除。举几个例子。这两段代码得出的结果是一样的,但是性能差别非常大。
sc.textFile("hdfs://…") .flatMap(lambda line: line.split()) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b) sc.textFile("hdfs://…") .flatMap(lambda line: line.split()) .map(lambda word: (word, 1)) .groupByKey() .map(lambda (w, counts): (w, sum(counts))) 区别就在于一个reduceByKey,一个是groupByKey,下面就通过两张图来了解一下。
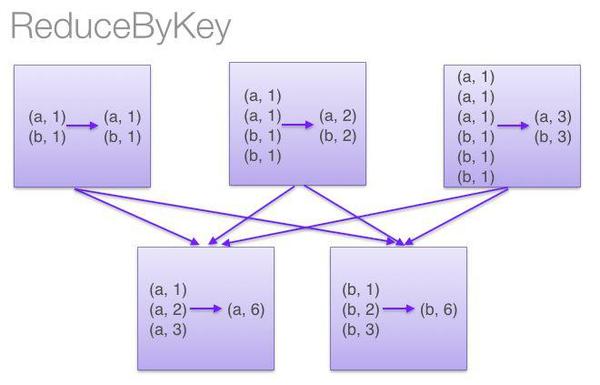
图片来自网络
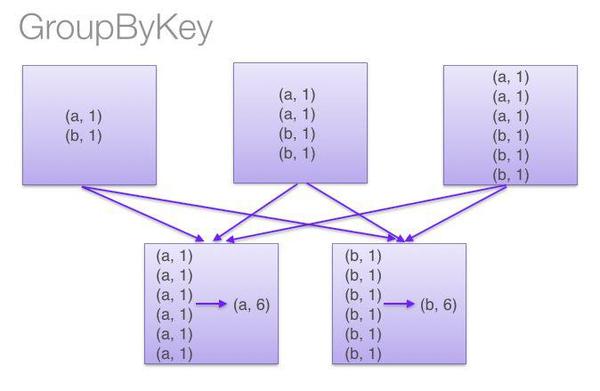
图片来自网络
再举一个,背景是这样的,一个很庞大的用户库(userid, userinfo),然后是一个每5分钟用户用点击的事件,我们需要找出这些用户点击的有哪些是这个用户不感兴趣或者感兴趣的。这个时候如果你是简单的val joined = userData.join(events)一下的话,结果就是这样的。

在这里会发现大量的数据移动,但是如果你先:
al userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...") .partitionBy(new HashPartitioner(100)) // Create 100 partitions .persist() 加个partitionBy,那个效果就变成下面这样,先把大数据集RDD分区好并persist起来,以后就只移动小数据集了。当然你也可以试试broadcast变量:
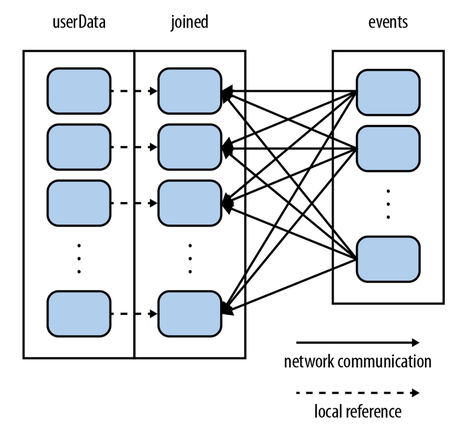
这样的例子实在太多,我也是在做压力测试的刚开始被OOM、heartbeat timeout搞得头疼,我想初学者一样会犯很多这样的错误的,中心意思是要尽可能少移动数据,所以driver上那个4040监控很有用,你shuffle read/write大小。另外不要轻易对大RDD做collect之类的操作,你的Driver很容易OOM。如果重用RDD的话要cache,这个用过spark都知道这个道理。给cache内存大小有一个参数设置的,它默认是总worker内存的0.6,这个可以调,你如果调到0,那cache会不成功,你也可以cache到硬盘,这个很多人知道,就不多说了。
QA(部分)
Q:你们目前数据仓库都是构建在Spark上吗?在使用SparkSQL的时候有没有碰到过什么问题?
周小四: 数据仓库我们还在规划中,使用SparkSQL还没有遇到问题。我们提供的是原生的Spark,所以遇到问题那肯定是Spark本身有bug了。
Q: 青云上的大数据存储推荐用户下端用块、文件,还是对象存储?是否必须要HDFS,HDFS副本数设置的是几?
周小四: 没限制只能用HDFS,Spark提供纯计算引擎,数据可以来自对象存储,也可以来自kafka的流数据,也可以来自任何Hadoop支持的数据源,这个是Spark的功能。HDFS我们默认设为2,这个已经讲过道理了,但是用户是可以自己调的。
Q:青云的云是用的OpenStack么? 可以做私有云么?
周小四: 不是,青云是自己开发的调度系统,已经说过了,激进点说,我们认为OpenStack没前途,也许我们错了,但是目前青云的调度系统是得到公有云的验证的。
(私有云)当然做了,不知道大家有没有看新闻,我们已经和招行,中行签私有云订单了。还有不少家正在POC阶段,名单现在不方便透露。
Q:那个例子中,用户库和事件应该都算是关系型数据库,用数据库来操作是否比HDFS更高效?一般架构是什么?Spark+Hive?
周小四: 那个例子只是说明一个问题,数据库的join也存在这个问题呀。如果拿大表去join一个小表,挪动大表的数据到小表也不可取。
HDFS下是块存储?HDFS是文件系统,它是把大文件分割成block的,说到这儿忘了分享怎么存数据到HDFS了,这个有讲究的,简单说就是要存splittable,能块compressed的格式,XML显然就不行。
参与方式
1. 微信群2已超过100人,请扫下方二维码,工作人员会邀请进入。

2. 加入CSDN Spark技术交流QQ群,群号:213683328。
3. CSDN高端微信群,采取受邀加入方式,请加微信号“zhongyineng”,带上你的BIO。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

