cache 的简单认识与思考
作者: tiankonguse | 更新日期:
之前对NOSQL的总结是:基本功能是key-value, 然后各自附加特殊功能. 现在简单的来认识一下cache.
背景
大家都知道NoSQL, 大多数都是 key-value 型的数据库.
有些内存型的数据库甚至可以当做远程cache来使用, 比如memcache, redis, 或者公司内部的TMEM等数据库.
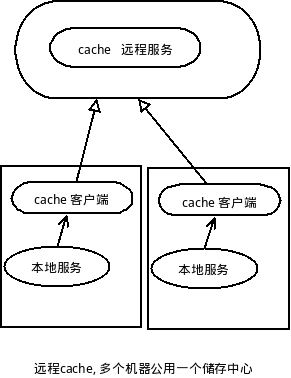
有时候,我们认为远程cache依旧太慢,毕竟一次网络操作来回至少几十毫秒, 加上网上不稳定等因素, 本地cache还是很有必要的.
目前,我使用的本地cache往往是开一个共享内存, 然后服务会开若干进程, 这些进程同时读写本地cache, 基本上解决了服务高访问量的问题.

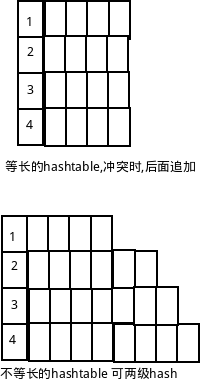
这个本地cache使用的是一个通用的cache库, 特点是使用hashtable实现, 缺点是key和value的长度是固定的.
固定的长度, 会导致几个问题.
- key和value 最大长度限制.
- 很浪费空间, 所有的value占用相同的空间. 我们的value及时只有很小的长度, 占用的空间依旧很大.
后来, 我遇到这么一个问题: 有大量的数据, value在短时间内只有一个值:0或者1.
看到这个, 大家第一个想到的应该是位压缩吧.
但是注意这里有两个问题: 1.我们不能把所有的key储存下来, 2.value只是在短时间内不变,过了时间就失效了.
其实, 这就是cache能够满足的事情, 只不过这个cache的value比较极端,只有几字节.
再后来,我又遇到一个问题:有大量的数据, value在短时间内非常大,有时候高大30K.
这个问题cache还是可以满足的, 只是这个cache的value又是另一个极端: value非常大.
针对这两个问题, 我们需要改造cache, 来分别适应两个极端情况.
小value极端
对于小value极端情况, 解决方案简单点: 初始化共享内存时动态指定value的长度即可.
当然储存的数据结构的参数也要调整一下, 目的是让key在hash的时候足够的分散, 毕竟我们的value长度可能还没有key的长度长.
当然我们也可以换一下数据结构, 使用hash list 或者 平衡树.不过一般情况下不要使用树这个数据结构吧, 实现复杂(正确性难以保证),复杂度还是log级别的(和hash相比,还是差一个数量级).
大value极端
对于大value极端情况, 我们就不能简单的增大value来解决问题了.
因为这个大value只是说明极端情况下, 有些value很大, 一般情况下, value还是中等大小的.
如果我们简单增大value, 将会浪费很大内存(内存还是很宝贵的).
PS:我第一次简单的增大value时,增大前占用共享内存是1.6G, 单纯的增大value值,没有减小节点数的时候, 机器瞬时死了,一查内存,申请了24G内存, 16G是虚拟内存,吓尿了.
面对上面的问题,我们目前的储存方式是不能解决的, 所以需要换一种储存方式.
最直接的想法就是key和value分开储存, 我们key的数据结构中只需要储存value的一些元信息即可.
这个时候,对于value的储存,很容易想到操作系统内存分配算法, 对,就是这个方法, 对value分页, 然后保存每一页的信息即可.
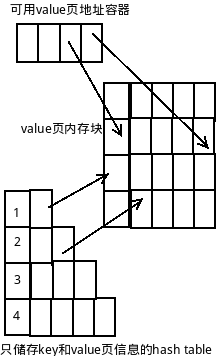
这个时候,再回过头看看这个储存方式, 可以支持任意大小的value值了, 对于小value, 浪费顶多不到一页的内存.当然, 代价是我们需要另外预留一片内存,来管理value的页块.
尾记
这种value极小, 极大, 一般的情况在我的一个服务中都遇到了, 起初是固定value值比较小, 对于大value,直接报写cache错误.后来增大value后, 写cache正常了, 但是cache的节点数讲了一个数量级:由30000变成2000, 根据监控, cache的利用率瞬时飙到80%.
目前比较偷懒的方法是把cache库改造拆分成三个库, 极小情况下使用极小value的cache库, 极大情况下使用极大value的cache库.
PS: 之前感觉共享内存很高大上, 看了源代码, 发现我们先得到共享内存的指针,然后, 共享内存也仅仅只是一片内存而已了,怎么干还是自己说了算.
PS: 关于共享内存加锁的问题, 不在该文章范围内, 故不许考虑多写加锁问题.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

