在mac下使用python抓取数据
2015已经过去,这是2016的第一篇博文!
祝大家新年快乐!
但是我还有好多期末考试!
还没开始复习,唉,一把辛酸泪!
最近看了一遍彦祖的文章叫做
iOS程序员如何使用Python写网路爬虫
所以自己也想小试牛刀.于是便开始动手写,但初次接触,还是遇见了很多不懂的东西,于是爬文一个一个解决了,最终抓取了自己想要的东西
彦祖的这篇文章里Python代码格式有错,但是解释是没错的!所以我待会儿贴出我能正确运行的代码
彦祖的文章里说可以直接用类似于cocoapods的Python库管理工具pip进行安装我们解析网页所需要用的第三方库BeautifulSoup!
Mac确实是自带了Python.但是并没有安装pip,所以需要我们手动进行安装!
有人说可以使用命令:easy_install pip进行安装,但是我并没有安装成功!百思不得其解
于是爬文寻找其他方法: http://stackoverflow.com/questions/17271319/installing-pip-on-mac-os-x
原来是需要我的超级管理员权限...
至此,安装Pip成功
- 第二步:安装BeautifulSoup!
用彦祖的命令去运行,结果报错!提示我安装失败!(又忘了截图..)
没办法,就尝试手动安装BeautifulSoup,结果还是不行
后来我想是不是还是因为没有 管理员权限 的原因
于是尝试加上过后,就安装成功了
好了,开始写代码吧,但是我一个新人连该用什么来写Python代码都不知道!
又搜!(好低级的问题)=====>用记事本就行(真方便)( 保存为.py文件后,是用的xcode打开的)
于是敲了如下代码:
1 #!/usr/bin/python 2 #-*- coding: utf-8 -*- 3 #encoding=utf-8 4 5 import urllib2 6 import urllib 7 import os 8 from BeautifulSoup import BeautifulSoup 9 def getAllImageLink(): 10 html = urllib2.urlopen('http://www.dbmeinv.com').read() 11 soup = BeautifulSoup(html) 12 13 liResult = soup.findAll('li',attrs={"class":"span3"}) 14 15 for li in liResult: 16 imageEntityArray = li.findAll('img') 17 for image in imageEntityArray: 18 link = image.get('src') 19 imageName = image.get('title') 20 filesavepath = '/Users/WayneLiu_Mac/Desktop/meizi/%s.png' % imageName 21 urllib.urlretrieve(link,filesavepath) 22 print filesavepath 23 24 25 if __name__ == '__main__': 26 getAllImageLink() 获得了如下数据(彦祖好邪恶....):
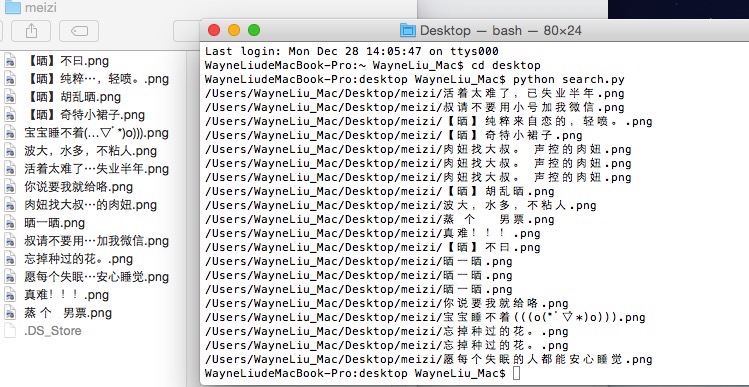
其实python真的很强大的,短短数几十行代码就可以实现这些功能!
闲来无事,又完善了一下代码,用以获得所有妹子的照片...
1 #!/usr/bin/python 2 #-*- coding: utf-8 -*- 3 #encoding=utf-8 4 5 import urllib2 6 import urllib 7 import os 8 import socket 9 from BeautifulSoup import BeautifulSoup 10 11 12 def getAllImageLink(): 13 xiayiye = True 14 page = '/?pager_offset=12' 15 while(1): 16 html = urllib2.urlopen('http://www.dbmeinv.com%s' % page).read() 17 soup = BeautifulSoup(html) 18 19 liResult = soup.findAll('li',attrs={"class":"span3"}) 20 nextResult = soup.findAll('li',attrs={"class":"next next_page"}) 21 22 23 for li in liResult: 24 imageEntityArray = li.findAll('img') 25 nameResult = li.findAll('span',attrs={"class":"starcount"}) 26 for name in nameResult: 27 nameTitle = name.get('topic-image-id') 28 29 for image in imageEntityArray: 30 link = image.get('src') 31 filesavepath = '/Users/WayneLiu_Mac/Desktop/meizi2/%s.jpg' % nameTitle 32 socket.setdefaulttimeout(30) 33 urllib.urlretrieve(link,filesavepath) 34 print filesavepath 35 36 for nextPage in nextResult: 37 aEntityArray = nextPage.findAll('a') 38 for a in aEntityArray: 39 nextTitle = a.get('title') 40 print nextTitle 41 page = a.get('href') 42 print page 43 if nextTitle.encode('utf-8') != "下一页": 44 xiayiye = False 45 print xiayiye 46 if xiayiye == False: 47 break 48 49 if __name__ == '__main__': 50 getAllImageLink() 呵呵哒...
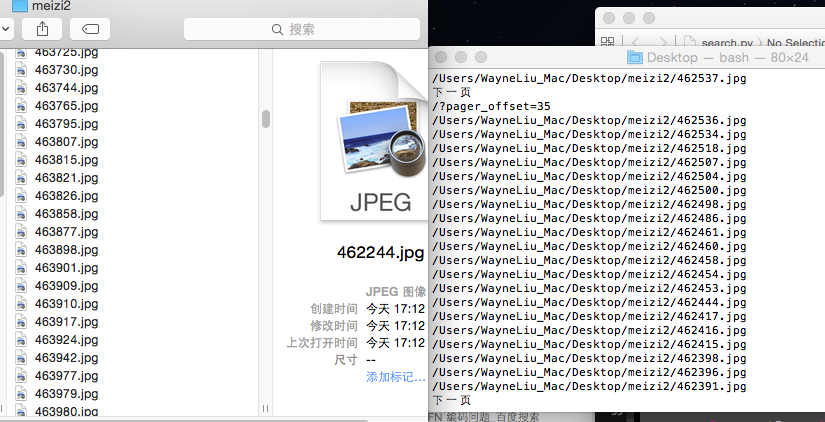
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

