Kubernetes 联网方案比较
【编者的话】本文比较了几种 Kubernetes 联网方案,包括 Flannel (aws-vpc | host-gw | vxlan) 和 IPvlan 。目前建议选择 flannel + host-gw 方案,没有特别依赖,性能也够用。一旦 flannel 支持 IPvlan (有自动化设置工具了),且 Linux 内核版本比较新,就可以采用 IPvlan 方案。
Kubernetes 要求集群包含的每一个容器都拥有一个独立、可路由的 IP 地址。IP 地址的分配是由第三方联网解决方案负责, Kubernetes 自己不管。
本研究的目标是找出一个适合 Kubernetes 的最佳联网方案:延迟最低、吞吐最高、设置最容易。我们选择延迟敏感的网络负载,试图衡量在网络负载相对较高时请求占比与延迟的对应关系。我们尤其关注网络负载是最大负载的 30-50% 时联网方案的性能表现,因为我们觉得这是一个尚未超出最大负载系统的最常见负载范围。
联网方案
Docker --net=host
这项测试的结果是一个标杆,代表可能达到的最佳性能,其他方案的测试结果将分别与之比较,评判优劣。
--net=host 是指容器继承宿主机的 IP 地址,不包含任何网络隔离。
与其他实现网络隔离的联网模式相比, Docker --net=host 模式的性能更好,所以我们选择这种模式作为标杆。
Flannel
Flannel 是由 CoreOS 维护的一个虚拟网络方案。这个方案经过精心测试,完全可用于生产环境,它也是最容易设置的。
使用 flannel ,添加一台新机器到集群时, flannel 做了三件事:
- 使用 etcd 为新增机器分配一个子网
- 在宿主机上创建一个 虚拟桥接接口 (名为 docker0 的桥接器)
- 设置一个网络转发 后端
-
aws-vpc: 在 Amazon AWS 实例表中注册新增机器子网。该实例表最多支持 50 项记录,这意味着,如果你使用 flannel + aws-vpc 方案,集群最多只能包含 50 台机器,集群也只能运行在 AWS 云平台。 -
host-gw: 通过远程机器 IP ,创建到子网的 IP 路由。这要求运行 flannel 的不同主机在二层直接互通。 - `vxlan`: 创建一个虚拟的 [VXLAN 接口](https://en.wikipedia.org/wiki/Virtual_Extensible_LAN)。
-
由于 flannel 使用桥接接口转发网络包,从一个容器发往另一个容器的网络包将历经两个网络栈。
IPVlan
IPvlan 是 Linux 内核中的一个驱动,有了它,无需使用桥接接口,就可以创建拥有唯一 IP 地址的虚拟网络接口。
使用 IPvlan 为容器分配一个 IP 地址,需要下列步骤:
- 创建一个不包含任何网络接口的容器;
- 在默认的网络命名空间中创建一个 ipvlan 接口;
- 把新建的 ipvlan 接口转移到容器的网络命名空间。
IPvlan 是一个相对较新的解决方案,现在还没有能完成上述过程的自动化工具。如果集群的机器和容器比较多,部署 IPvlan 的难度不小,不容易设置。
不过, IPvlan 不需要使用桥接接口,网络包从网卡直接转发到虚拟网络接口,我们预期它的性能应该好于 flannel 。
负载测试场景
对每一种方案,执行下列步骤:
- 在两台物理机器上设置联网 ;
- 在一台物理机的一个容器中运行 tcpkali ,以恒定速度发送请求;
- 在另一台物理机的一个容器中运行 Nginx ,收到请求后,返回一个固定大小的文件给请求方;
- 记录系统度量和 tcpkali 结果。
测试的两个参数分别是每秒发送的请求数(requests per second, RPS)和静态文件的大小。前者的取值从 50,000 到 450,000 不等,后者主要分为 350B(100 字节的文件内容和 250 字节的文件头) 和 4KB 两类文件。
测试结果
-
IPvlan的延迟最低、吞吐量最高,Flannel + host-gw和flannel + aws-vpc方案的性能紧随其后,不过,在负载达到最大值时, 前者的测试结果更好; - 就跟预计的一样,在所有测试中,
Flannel + vxlan方案的测试结果都是最差的。不过,有一个例外,我们怀疑这种方案在 99.999% 这一项的糟糕结果是由软件缺陷造成的; - 返回的文件的大小是 4KB 还是 350B ,测试结果都差不多。有两点不同需要注意:
- 4KB 时,支持的最大负载(RPS)相对低得多,因为一个 10Gbps 网卡,只需 25kRPS 就达到最大负载了(250k * 4k = 10G);
- IPvlan 的吞吐量与
--net=host的吞吐量非常接近,即接近达到吞吐上限。
我们选择 flannel + host-gw 联网方案,因为它没有特别的依赖(例如, aws-vpc 只能运行在 AWS 平台, ipvlan 要求内核版本比较新),与 IPvlan 相比,更容易设置,性能也够用。 IPvlan 是我们的备选方案,一旦 flannel 支持 IPvlan ,我们就会切换到 IPvlan 方案。
虽然 aws-vpc 方案的性能略优于 host-gw ,但是用这种方案设置的集群最多只能包含 50 机器,也只能运行在 AWS 平台上,这是我们无法接受的。
50kRPS, 350B

当每秒发送 50,000 个请求,返回的静态文件大小为 350B 时,所有方案的性能表现都还可以。从中也能看出主要趋势: IPvlan 表现最好, aws-vpc 和 host-gw 紧随其后,而 vxlan 的表现最差。
150kRPS, 350B

150kRPS (约为最大 RPS 的 30% )时请求占比与延迟的对应关系,单位是 ms (毫秒)
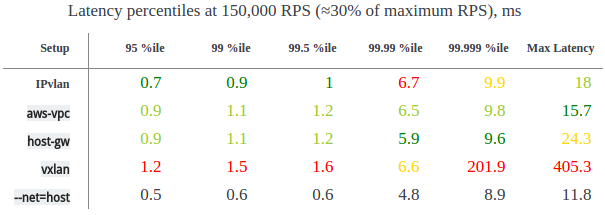
IPvlan 比 aws-vpc 和 host-gw 表现稍好,不过在请求占比 99.99% 这一项中,它的表现最差。总体上, host-gw 的表现略好于 aws-vpc 。
译者注:以 IPvlan 为例, 99.99% 对应的延迟取值是 6.7ms 。这意味着每秒有 150,000 * 99.99% 个请求的延迟不高于 6.7ms 。
250kRPS, 350B

这是生产环境中常见的负载,所以这个测试结果特别重要。
250kRPS (约为最大 RPS 的 50% )时请求占比与延迟的对应关系,单位是 ms (毫秒)
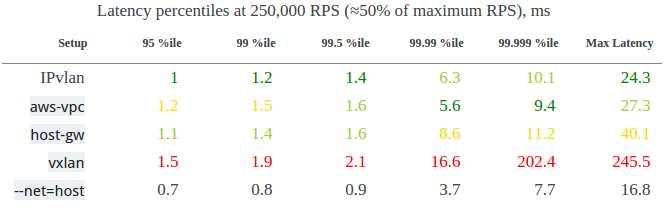
IPvlan 的表现最佳,但是 aws-vpc 在 99.99% 和 99.999% 两项的表现最好。而 host-gw 在 95% 和 99% 这两项的表现好过 aws-vpc 。
350kRPS, 350B

与上面 250krps, 350B 的测试结果差不多,但是在 99.5% 以后,延迟迅速增加,这意味着网络负载已经接近最大值。
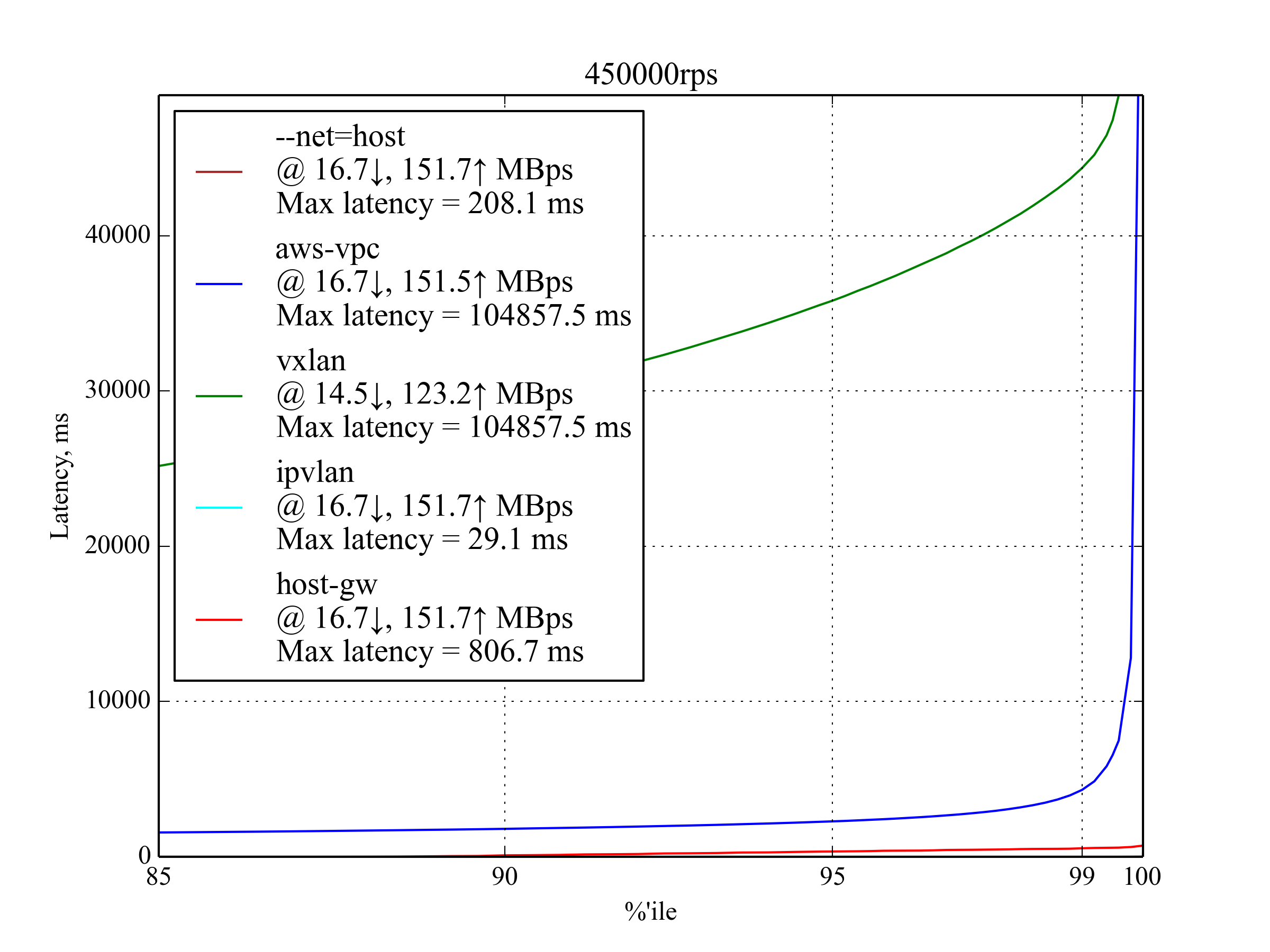
450kRPS, 350B
这是能产生有意义结果的最大 RPS 取值。
IPvlan 仍然表现最佳,与 --net=host 相比,延迟增加了大约 30% 。
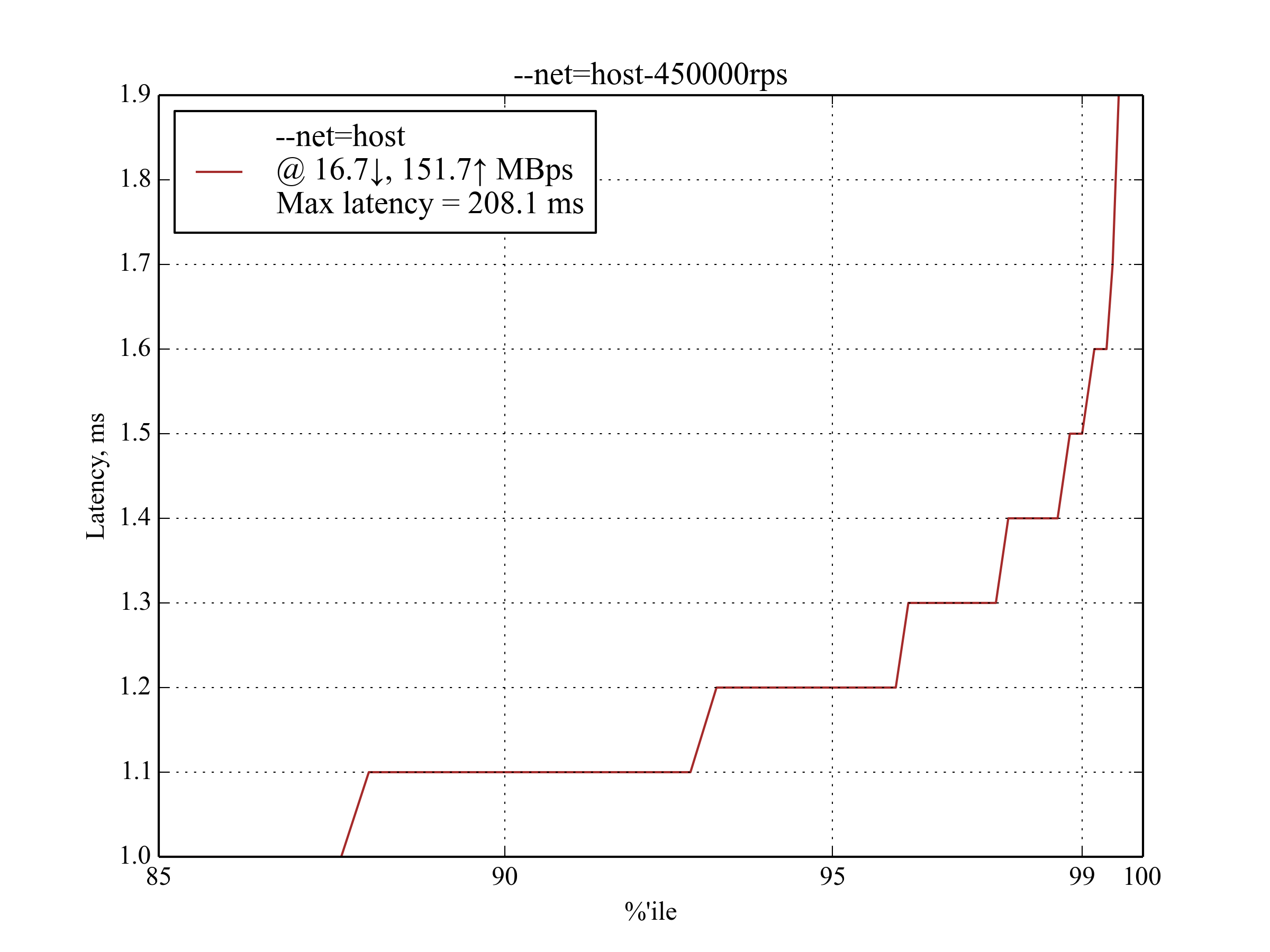
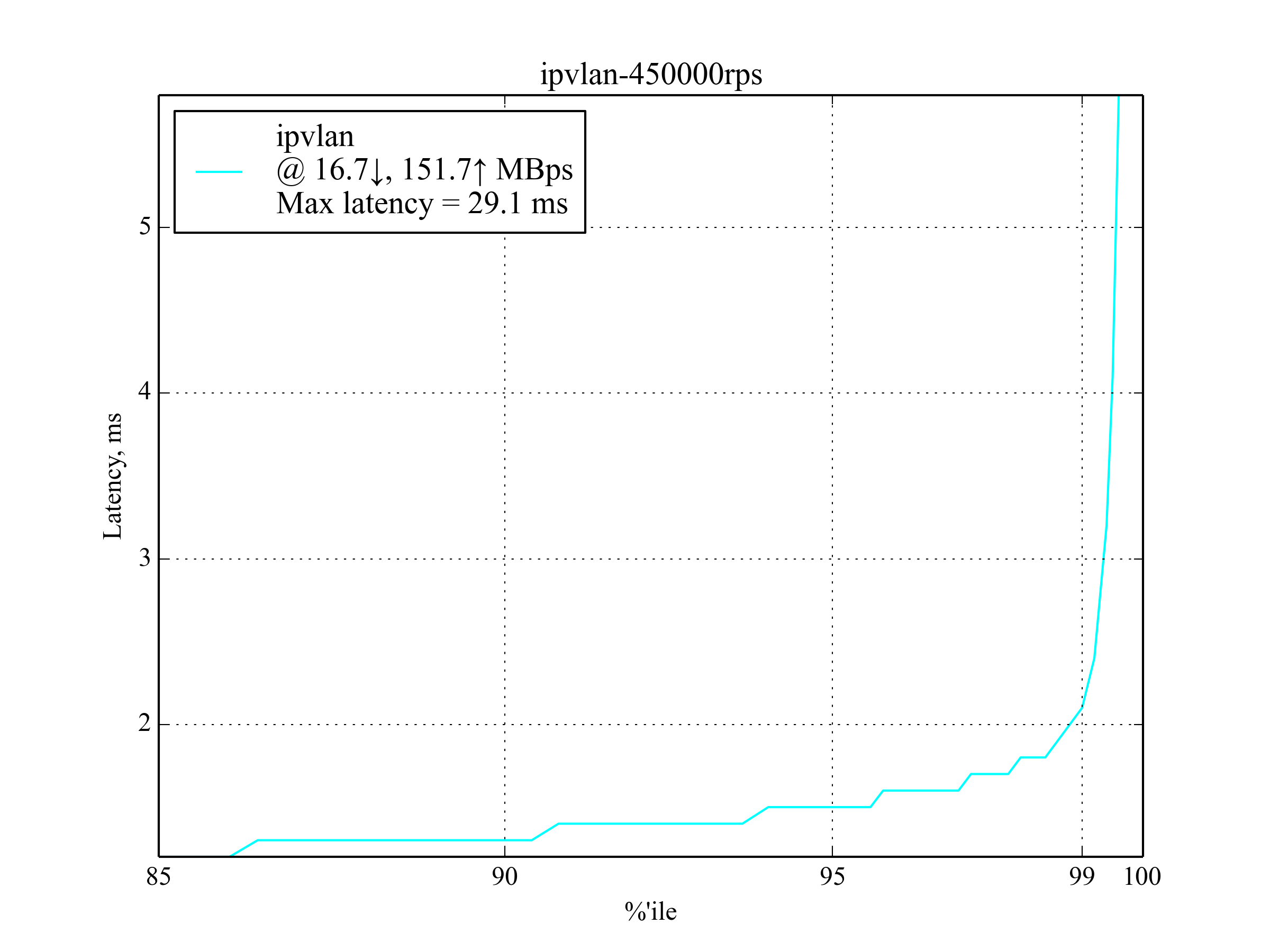
有意思的是, host-gw 的表现远超 aws-vpc 。
500kRPS, 350B
当每秒请求数达到 500,000 个时,只有 IPvlan 方案还能正常工作,甚至比 --net=host 还好!不过,此时的延迟非常高,完全不适合延迟敏感型应用。

50kRPS, 4KB
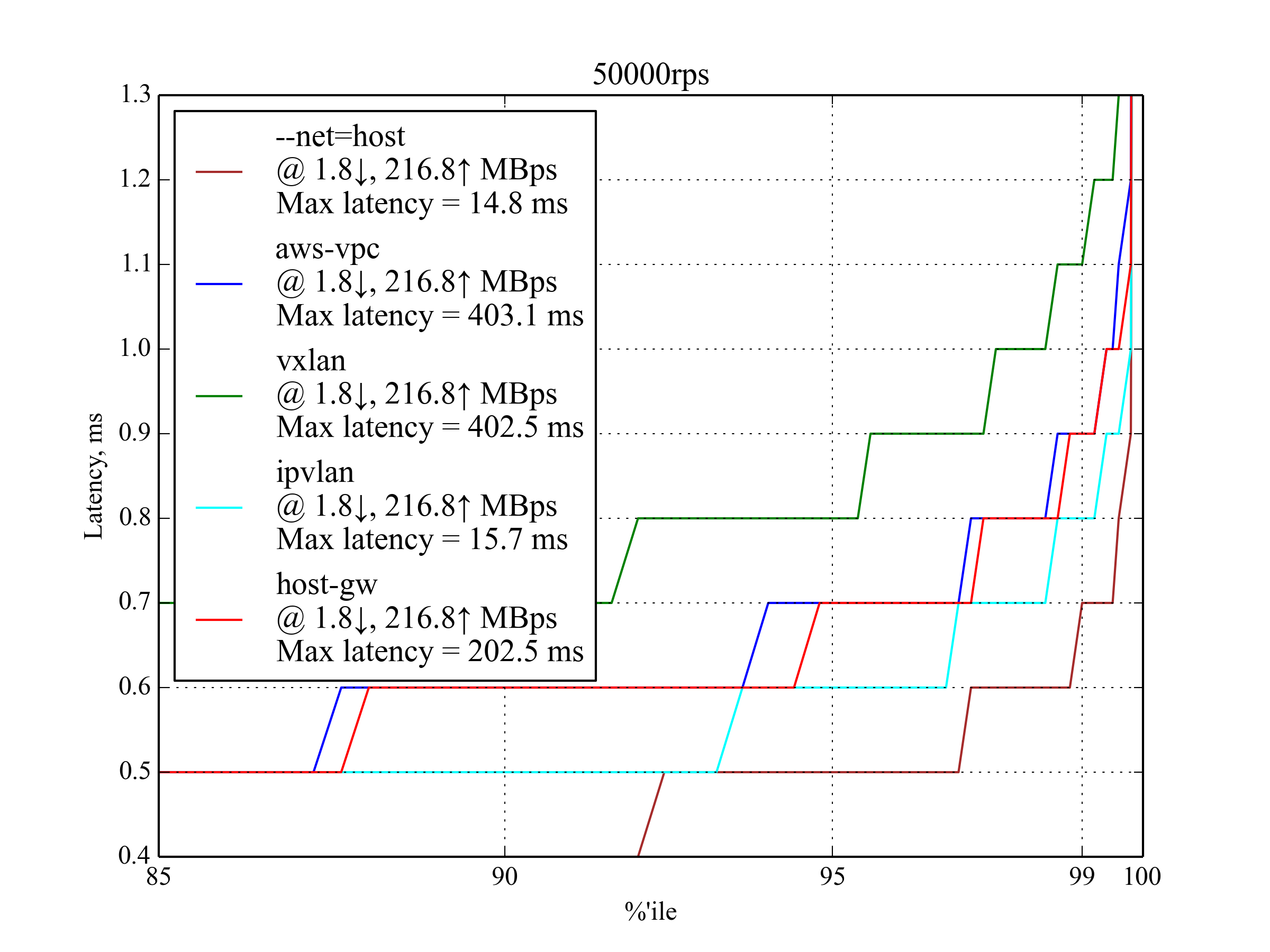
返回的文件更大,因此占用的网络带宽也更高。这项测试的结果与 50krps, 350B 的测试结果差不多。
50kRPS (约为最大 RPS 的 20% )时请求占比与延迟的对应关系,单位是 ms (毫秒)

150kRPS, 4KB

host-gw 在 99.999% 这一项的表现出人意料地差,低于此比例的表现还是不错的。
150kRPS (约为最大 RPS 的 60% )时请求占比与延迟的对应关系,单位是 ms (毫秒)

250kRPS, 4KB
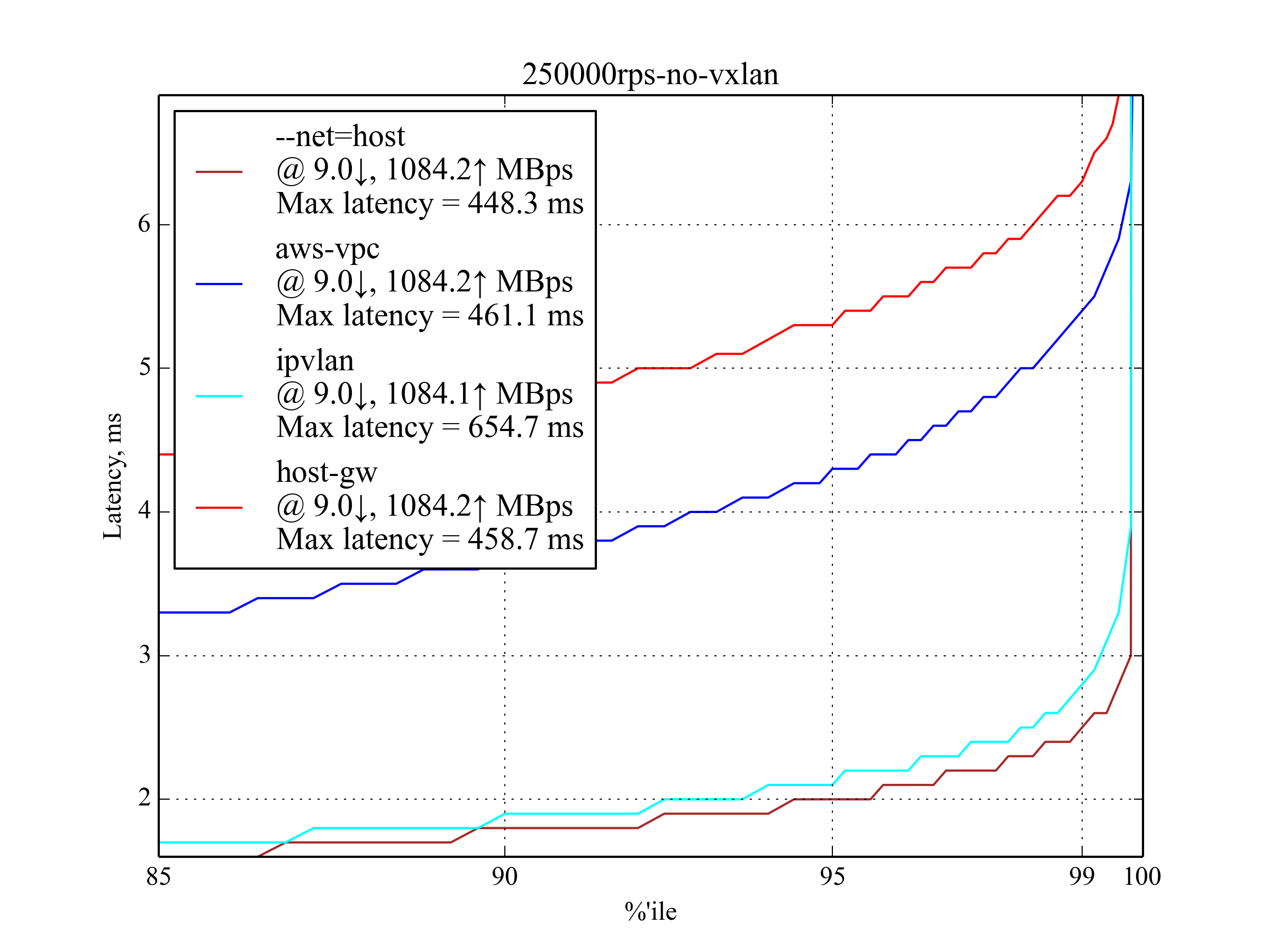
这是响应文件大小为 4KB 时允许的最大 RPS 。 aws-vpc 表现远远好于 host-gw ,跟响应文件大小为 350B 时的测试结果非常不同。
vxlan 又一次被排除在外(译注:延迟太高了),上图中根本就没画。
测试环境
背景
要想理解这篇文章,重现测试环境,你必须熟悉有关高性能的基础知识。
下列文章非常有用:
- CloudFlare 博客文章: 如何做到每秒接收 100 万个网络包
- CloudFlare 博客文章: 10Gbps 以太网如何做到低延迟
- Linux 内核文档: Linux 网络栈中的扩展技术
机器
- 两个 Amazon AWS EC2 的 c4.8xlarge 实例 ,操作系统是 CentOS 7 。
- 两台机器都开启了 增强联网 。
- 每台机器包含 2 个处理器( NUMA 架构),每个处理器有 9 核,每核 2 个超线程。也就是说,每台机器能有效地运行 36 个线程。
- 每台机器有一块 10Gbps 网卡, 60GB 内存。
- 为了支持增强联网和 IPvlan ,我们安装了 Linux 内核 4.3.0 和 Intel 的 ixdbevf 驱动。
设置
现代网卡都提供了经由多 中断 线的 RSS(Receive Side Scaling, 接收端扩展) 功能。 EC2 的虚拟环境只提供两个中断线,我们测试了几种 RSS 和 RPS(Receive Packet Steering,接收包控制)配置,最后选择下列配置,其中有一部分参考了 Linux 内核文档的建议:
译者注: RSS 和 RPS 的作用都是把网络包直接交给特定的 CPU 核处理,前者需要网卡硬件支持,后者是纯软件实现。
IRQ
每台机器有两个 NUMA 节点(处理器)。设置每个 NUMA 节点的第一个 CPU 核专门处理网卡中断。
首先调用 lscpu ,列出处理器与 NUMA 节点的对应关系:
$ lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-8,18-26
NUMA node1 CPU(s): 9-17,27-35
由此可见,要设定第 0 号和第 9 号 CPU 核处理网卡中断,即把 0 和 9 写入 /proc/irq/<num>/smp_affinity_list ,其中 <num> 是中断号,可以通过调用 grep eth0 /proc/interrupts 获得,例如:
$ echo 0 > /proc/irq/265/smp_affinity_list
$ echo 9 > /proc/irq/266/smp_affinity_list
RPS
我们测试了几种 RPS 组合。为了降低延迟,我们只用 CPU 核 1-8 和 10-17 处理中断。不像 IRQ 有可以直接设置的 smp_affinity_list 属性,得用位掩码设定 由哪些 CPU 核处理网络包(参见脚注 1 ):
$ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-0/rps_cpus
$ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-1/rps_cpus
XPS(Transmit Packet Steering, 传送包控制)
第一个处理器的 CPU 核(包括超线程,即 0-8, 18-26 )专门处理传输队列 tx0 ,第二个处理器的 CPU 核(9-17, 27-35)专门处理传输队列 tx1 (参见脚注 2 ):
$ echo "00000000,07fc01ff" > /sys/class/net/eth0/queues/tx-0/xps_cpus
$ echo "0000000f,f803fe00" > /sys/class/net/eth0/queues/tx-1/xps_cpus
RFS(Receive Flow Steering,接收流控制)
我们计划使用 60k 永久连接,官方建议把 RFS 设为与之最接近的 2 的次幂:
$ echo 65536 > /proc/sys/net/core/rps_sock_flow_entries
$ echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt
$ echo 32768 > /sys/class/net/eth0/queues/rx-1/rps_flow_cnt
Nginx
Ngnix 使用 18 个工作进程,每个进程对应一个专门的 CPU 核(0-17),这是通过 worker_cpu_affinity 选项设定的:
workers 18;
worker_cpu_affinity 1 10 100 1000 10000 ...;
Tcpkali
Tcpkali 本身不支持与特定的 CPU 核绑定。我们用 taskset 执行 tcpkali ,设置调度器,使得线程很少会被从一个 CPU 核调整到另外一个 CPU 核执行:
$ echo 10000000 > /proc/sys/kernel/sched_migration_cost_ns
$ taskset -ac 0-17 tcpkali --threads 18 ...
上面的设置使得中断负载更均匀地分布在 CPU 核上。在同等延迟下,与其他设置相比,这种设置的吞吐量更高。
第 0 号和第 9 号CPU 核只处理网卡中断,不收发网络包。但是它们仍然是最忙碌的 CPU 核:
还使用 Red Hat 的 tuned ,开启网络延迟画像。
为了把 nf_conntrack 的影响降到最小, 添加了 NOTRACK 规则 。
为了支持更多的 tcp 连接,用 sysctl 调整下列参数:
fs.file-max = 1024000
net.ipv4.ip_local_port_range = "2000 65535"
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_slow_start_after_idle = 0
net.ipv4.tcp_low_latency = 1
脚注
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

