数据科学家教你用数据模型来恋爱
男生和女生分别是来自不同星球的科学事实已经众所周知的了.男生们总是认为,女生们都是迷一样的生物,他们的情感状态浮动似乎是以秒单位在变化的,难以理解,更勿论预测了! 而女生们觉得男生都是没有感觉动物,完全不能理解什么叫感受-尽管已经告诉他们N次了!这种男女之间的根本差别,导致了他们之间的感情关系是受一种超级无敌复杂的系统所支配的.
不过,我们可以用一个叫 隐式马尔可夫(Hidden Markov Model) 的数学模型来分析这个系统.
决定性系统
首先我们来看看一种最简单的预测系统 – 决定性系统.
在这个系统中,如果我们知道我们目前所在的状态,那么我们也就能够毫无疑问地预测出下一个状态是什么. 比如一年四季的轮替就是一个决定性系统:每个季节的交替是完全可以预测的,如果现在是春天,那么下一个季节就一定会是夏天,冬天的前一个状态就一定是秋天等等.另外值得一提的是,冬天过后,下一个季节就又会回到春天,以此循环…
另外一个常见的决定系统,就是交通灯的轮换: 红灯过后就应该是绿灯. 绿灯过后就应该是黄灯,然后又回到红灯.
这种系统非常常见,人的一生大致也能看作是这种系统. 有婴儿,少年,成年,老年,然后死亡等几种状态. 不过不同的是,人的一生又不是完全遵循这种状态轮换的, 每个人都有那么丁点的可能性会跳过其中一个或者多个状态,直接到达死亡的状态…(更勿论Benjamin Buttons的情况了,呵呵).
讲到这里,聪明的男生或许已经能想到,我们的世界里最为精妙,最雷人的非决定性系统就是 — 你女朋友的情感状态!
对于大部分男生来说,精确地预测女朋友的下一种的情感状态基本上属于扯淡.
一个mm现在可能心情很好,可是下一秒却进入抓狂;她或许某个时刻处于悲伤,下个时刻却变得异常兴奋.在每个女生的情感状态里面,都有一种基于概率却又难以预测的本质,这种无序的本质直接导致无数男生直接蹲地画圈圈……
尽管看上去女生的情感状态似乎毫无预测性可言,经过一段长时间的观察,却能发现这种现象是有规律的! 于是小明,作为一名计算机科学家, 决定要系统地去分析他女朋友的情感不确定性, 挖掘出里面的规律!
于是乎,小明仔细地记录了半年来他女朋友小丽每天的喜怒哀乐变化状态, 并作了一张图表(Table1)来表示小丽的历史情感变化.
小明想知道, 有了这些数据,他能否从中得出知道, 如果小丽某天的情感状态是高兴, 那么第二天她更多的是保持好心情呢,还是更多地变得悲伤了.如此等等…
数据胜于雄辩, 小明从这半年的数据里面发现,当小丽高兴的时候,3/4的情况下第二天她仍然保持着好心情,只有1/4的情况小丽第二天心情会改变,比如变得气愤,悲伤等等(小明真TM走运!).小明继续分析其他各种情感状态变化情况,比如从高兴到悲伤, 悲伤到气愤, 高兴到气愤等所有的可能组合.很快小明就得到所有的组合变化数据,从中得知对于任意小丽的某天情感状态下,下一个最有可能的情感状态.
为了便于教学,我们假设小明只关心小丽的四种感情状态: 高兴 悲伤 气愤 还有 忧虑

- Table 1: 小丽的情绪状态变化表
在这个表格中, 每个数字代表了小丽情绪从某列转变到某行的概率. 比方说, 如果小丽某天的情绪是高兴,那么她将有0.1的概率下一天她会变得 悲伤 或者是 气愤, 有0.05的可能性转变为 忧虑. 每一行代表了从某种情绪转变到各种情绪的概率,因此每行的概率之和为 1.
同理,每一列代表了由各种情绪转变为该列所代表的情绪的概率,因此每列的概率总和也应该为1.
我们可以画一个状态图(图1)来表示表格1, 每个圆圈代表着一种心情状态, 每两种心情变化由一个有向弧,从当前的心情状态指向下一个心情状态表示,每个弧上均带有一个状态转换的概率.
- Figure 1: 小丽的情绪状态变化图
有了这个图表,小明就可以非常直观地看得到小丽最有可能的下个心情会是如何. 她会很有可能变得悲伤吗?(准备好鲜花巧克力),还是更有可能是气愤?(赶紧闪开!) 每天小明只需要看看哪个弧指向的心情概率最大就可以了.
这个过程,同学们,就是有名的 “马尔可夫过程” (Markov process)
不过需要注意的是, 马尔可夫过程有一些假设的前提. 在我们的例子里面, 预测下一天小丽的心情, 我们只依赖当天小丽的心情,而没有去考虑更先前她的心情. 很明显这种假设下的模型是远不够精确的. 很多时候,随着日子一天一天的过去,女生一般会变得越来越体谅.经常女生生气了几天后,气就会慢慢消了. 比方说如果小丽已经生气了3天了,那么她第二天变得高兴起来的可能性,在多数情况下,要比她只生气了一天而第二天变得高兴的可能性要高. 马尔可夫过程并没有考虑这个, 用行话讲, 就是马尔可夫模型忽略远距离历史效应 ( long range dependency).
我很佩服各位能坚持读到这里, 不过,还没完呢, 我仍然没有说,隐式马尔可夫模型 (Hidden Markov Model)是什么呢! 诸位如果已经有点头昏脑涨,请就此打住,以免大脑过热死机!
隐式马尔可夫模型 – Hidden Markov Model, or HMM for short.
有些时候,我们无法直接观测一个事物的状态. 比方说, 有些女生是很能隐瞒自己的情感而不流露出来的! 他们可能天天面带微笑但不代表他们就天天高兴. 因此我们必须要有窍门, 去依赖某些我们能够直接观察到的东西.
话说回来我们的主人公小明, 自从被小丽发现他这种近乎变态的科学分析行为后,变得非常善于隐藏自己的心情,导致某天小明错误估计了小丽的心情!在误以为那天小丽会心情好的情况下,小明告诉小丽自己不小心摔坏了她心爱的iPod…,小明没想到其实那天小丽正因为前一天错过了商场名牌打折扣的活动而异常气愤… 一场血雨腥风过后,两个人最终分手了.
不过很快小明凭着自身的英俊高大潇洒,很快又交上了另外一个女朋友 – 小玲. 鉴于小明意识到,女生表面的情感流露非常不可靠, 小明决定要另寻他径, 继续预测女朋友的心情! (作为一个数据科学家,小明的确有着不怕碰壁的精神!)
小明每个月都帮小玲付信用卡的费用(真不明白,有这样的男朋友,小玲有什么理由不高兴啊!), 因此小明每天都可以通过Online banking知道小玲每天都买了什么东西. 小明突然灵机一动: “没准我能通过观测她的购物规律,推导预测出小玲的心情!”.听起来有点匪夷所思,不过这个过程,的的确确是可以使用叫作隐式马尔可夫的数学模型来表示并分析的.
由于我们需要预测的变量 – 心情状态 是无法直接观测的,是隐藏 (Hidden) 起来的.因此这种模型才叫隐式马尔可夫模型.
在一次和小玲的好朋友们一起吃饭的时候, 小明得知了以下重要的信息:”小玲高兴的时候经常去买一大堆新衣服”, “那天小玲一个人去超市买了一堆吃的,一定是有什么心事了(忧虑)”, “你千万不要惹小玲生气阿,不然她会刷爆你的信用卡的!”, “小玲好几次伤心难过的时候,一整天都宅在家里看杂志.”. 知道了这些信息,小明扩展了他原先一直采用的马尔可夫模型, 为每种隐藏的状态(心情)赋予了新的可观测状态(Observables),这些可观测状态为:
1./t大部分(>50%)花费是Fashion商场(O1)
2./t大部分(>50%)花费在超市(O2)
3./tOh my God! 一天刷了5000元以上!!! (O3)
4./tOh yeah! 这一天她都没花钱(O4)
为图简便,我们假设小玲和小明的ex小丽,有着同样的实际心情转换概率(图1).
小明通过归类统计小玲过往的信用卡帐单(天啊,怎么这么多!),发现了如表2所示的每天心情与每天信用卡消费之间的关系:
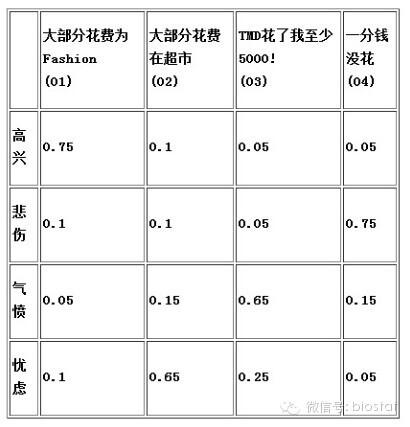
- Table 2: 小玲的每天情绪状态与当天信用卡花费的关系概率表
我要加一句的是, 由于概率的归一性(各种可能性之和为1), 我们为了不降低本文的娱乐搞笑性, 规定如果某天小玲大部分的花费是Fashion或者是在超市,那么她的花费不可能超过5000, 这样我们才有各行的 O1+O2+O3+O4 =1.
也就是说,当小玲高兴的时候, 小明发现80%的情况下那些天小玲基本都买性感小衣衣了(:Q), 也有那么10%的情况下大部分买吃的了, 令小明郁闷的是,居然小玲高兴了,还有那么5%的情况,刷了他5000+ ;最后剩下5%的情况小玲可能因为太高兴而顾不上消费了(小明暗笑:”对对,就是那次,她心情特好, we BEEP all day, it was the best we ever had!” )
自此, 小玲心情的隐式马尔可夫模型就出来了(图2).

- Figure2: 小玲的隐式马尔可夫模型
有了这个模型,我们就可以回答这个问题:
“如果我知道了小玲的信用卡花费规律,我能否找出她最有可能的心情变化序列是什么?”
具体一点吧, 某次小玲到外地出差了一个星期, 小明每天打电话给她问她今天开心嘛? 小玲都说 “开心”…但实际呢?
小明自言自语说, 哼你不告诉我, 我就只好算算了! 小明Login到了小玲信用卡网站,打开statement,统计了一下,发现小玲这一个星期的消费规律是:”O2 O1 O4 O2 O3 O1 O4” (对应着消费序列 穿的, 吃的, 没刷, 吃的, 刷爆, 穿的, 没刷 )
有了这个消费序列和图2的模型, 有办法找出小玲这7天最有可能的心情序列是什么吗?
信不信由你, Viterbi search algorithm (维特比搜索算法)就是用来计算出HMM模型中给定观测序列O(消费规律), 对应的最有可能的隐藏状态序列(心情变化). 关于Viterbi的原理和实现已经超出本文的讲解范围了,有兴趣的同学可以去Wiki或者动手Google一下. 简单来说Viterbi属于动态规划 (Dynamic programming) 算法的一种,用来比较高效地计算出一个转移矩阵及其观测矩阵(分别对应我们的Table1 和 Table2)制约下的最大可能的隐藏状态转移序列 -如果我们事先知道观测序列的话.
根据以上的转移矩阵(table 1})和观测矩阵(table 2), 建立起HMM模型并采用Viterbi算法(HMM还需要添加一个状态起始概率来表示每种状态作为起始状态的可能性,由于小明没有办法知>道这个数字,因此只能作最简单的假设 – 假设他们都是均匀分布的(uniformly distributed),所以每种状态的起始>概率均为1/4).
可以知道,对应以上观察序列,小玲那七天最为可能的情绪序列为:
忧虑 悲伤 悲伤 忧虑 气愤 高兴 悲伤
概率为 p=1.4×10^-5
看来小玲这次出差压力不小啊!
呜呼! 至此整个Hidden Markov Model就介绍完了.
当然,中间仍然有很多细节我是直接忽略了. 而且在现实使用当中,HMM模型中的规模要大得多,无论是隐藏的状态数目,还是可观测的状态数目,都超过千计. HMM 及其相关算法被大量广泛使用在各行各业.在计算机信息学中, 大量语音识别, 中文分词,中文拼音汉字转换系统采用的都是隐式马尔可夫模型.
转自:医学统计分析;
作者:Tom Yeh;
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

