新的 zero
安装
$ git clone https://github.com/liyanrui/zero.git $ cd zero $ autoreconf -i $ ./configure $ make $ cd po ; make update-po ; cd .. $ sudo make install名可名也,非恒名也
zero 是一个文式编程工具。它有两种工作模式,一种模式叫 day,另一种模式叫 night。这两种模式读取相同的文本,输出不同的内容——前者输出面向排版的源文档,后者输出程序源码。
zero 的输入文件称为 zero 元文档,其内容由排版标记文本与程序源码复合而成。例如下面这份 zero 元文档,由 ConTeXt 排版标记文本与 C 代码复合而成。
/starttext 下面我们用 C 语言写一个 Hello World 程序: @ hello.c 文件 # #include <stdioi.h> int main(void) { # 在屏幕上打印 "Hello world!" 字符串 @ return 0; } @ 可使用 C 标准库提供的 /type{printf} 函数在终端屏幕上显示文本,即: @ 在屏幕上打印 "Hello world!" 字符串 # print("Hello World!/n"); @ 编译这个程序的命令为: /starttyping $ gcc hello.c -o hello /stoptyping /stoptext假设将上述内容保存为 hello.zero 文件,使用 zero 的 night 模式可将 C 代码从这份文件中抽取出来:
$ zero --mode=night --entrance="hello.c 文件" --output=hello.c hello.zero或
$ zero -m night -e "hello.c 文件" -o hello.c hello.zero这两条命令等价,它们均可将 C 代码从 hello.zero 中抽取出来,输出至 hello.c 文件。然后使用 C 编译器可将 hello.c 编译为可执行文件:
$ gcc hello.c -o hello使用 day 模式可将 hello.zero 完全转换为 ConTeXt 排版源文件:
$ zero --mode=day --output=hello.tex hello.zero或
$ zero -m day -o hello.tex hello.zero使用 context 程序可将 hello.tex 『编译』为 hello.pdf:
$ context hello.texzero 不关心排版,所以可以用 TeX,Markdown 或 reStructuredText 等标记语言来负责排版方面的任务。
文档区与程序区
在 zero 元文档中,凡是形如
@ <文本>这样的文本区域称为 文档区 。
凡是形如:
@ <文本> # <文本>这样的文本区域称为 程序区 。
@ 称为 孔符 ,通过它,你可以出入文档区或程序区。 # 称为 栅符 ,用于文本区域定界。
孔符是文档区与程序区的领起符。为了消除歧义,需要约法三章:
-
若孔符是行首第一个非空字符,并且行尾无
/与栅符,那么孔符便是文档区的起始符; -
若孔符与栅符在同一行出现,且孔符之前与栅符之后皆为空白字符(空格符,指标符或换行符),此时定界符便是程序区的起始符;
-
若孔符与栅符之间含有多行文本,每行文本以
/结尾,且孔符之前与栅符之后皆为空白字符,此时定界符便是程序区的起始符。
若孔符领起一个程序区,便意味着在定义一个程序区——孔符与栅符之间的文本是这个程序区的名字。此外,zero 元文档如果是以文档区开始,那么这个文档区首部的孔符可省略。
程序区的引用
程序区可以引用其他程序区。例如,在程序区『 hello.c 文件 』内,引用了一个名为『 在屏幕上打印 "Hello world!" 字符串 』的程序区:
@ hello.c 文件 # #include <stdioi.h> int main(void) { # 在屏幕上打印 "Hello world!" 字符串 @ return 0; }与程序区名的形式相反,程序区的引用形式是由栅符领起被引用的程序区的名字,孔符作为结尾,并且栅符之前与孔符之后的字符只能是空白字符。
一个程序区被另一个程序区引用,而后者如果被 night 模式的 zero 访问,zero 会用前者的代码实体替换后者中的引用语句。例如,程序区『 在屏幕上打印 "Hello world!" 字符串 』:
@ 在屏幕上打印 "Hello world!" 字符串 # print("Hello World!/n"); @ 这个程序区被上面的 hello.c 文件 程序区引用了。当 night 模式的 zero 要提取 hello.c 文件 程序区中的代码时,即:
$ zero -m night -e "hello.c 文件" -o hello.c hello.zero zero 会用程序区『 在屏幕上打印 "Hello world!" 字符串 』中的文本替换程序区『 hello.c 文件 』中的『 # 在屏幕上打印 "Hello world!" 字符串 @ 』语句,结果为:
#include <stdioi.h> int main(void) { print("Hello World!/n"); return 0; }代码反向定位
zero 程序从其元文档中提取的程序源码,在编译或调试时,出错信息应该反向定位到 zero 元文档中,以便在 zero 元文档中对出错代码进行修改。当然,直接在提取出来的代码文件中修改也是可以的,但是这样容易导致 zero 元文档未能及时跟进,导致出错代码依然存在于 zero 元文档内。
C 语言为编译器提供了 #line 宏,它可以将当前文本行的某行行号映射为另外一个文件中的某行行号。要使得 zero 程序在提取 C 代码时自动生成基于 #line 宏语句的反向定位代码,需要使用 --backtrace 选项。例如:
$ zero --backtrace --mode=night --entrance="hello.c 文件" --output=hello.c hello.zero 或 $ zero -b -m night -e "hello.c 文件" -o hello.c hello.zero代码提取结果 hello.c 文件的内容如下:
#line 9 "hello.zero" #include <stdioi.h> int main(void) { #line 20 "hello.zero" print("Hello World!/n"); #line 13 "hello.zero" return 0; }这样,若 hello.c 文件中某处代码出错,那么 C 编译器会将出错的代码行定位到 hello.zero 文件中的相应文本行。
除了 C/C++ 之外,其他语言没有 #line 这样的反向定位功能,或者虽然有这种功能,但是采用了另一种语法。对于这些情况,只需对 zero 产生的 C 式反向定位信息作进一步处理即可。
棱镜:程序区文本的排版
由于 zero 元文档中的文档区的内容自身就是采用某种标记式排版语言来写的,在生成程序文档的排版元文档时,文档区部分不需要做特殊处理,只有程序区名的排版格式因所用排版语言而异。
对于任意一个程序区 $X$,从它的视角来看,它所包含的各个程序区名处于以下三种状态:
-
本体:$X$ 的定义的首部
-
引用:$X$ 引用的程序区
-
逆引用:引用了 $X$ 的程序区
前两个状态在 zero 元文档中是可见的。例如,上文示例中的程序区:
@ hello.c 文件 # #include <stdio.h> int main(void) { # 在屏幕上打印 "Hello world!" 字符串 @ return 0; }zero 的 day 模式将其处理为:
@ hello.c 文件 # #include <stdio.h> int main(void) { # 在屏幕上打印 "Hello world!" 字符串 @ return 0; } 其中,程序区名『 hello.c 文件 』处于本体状态,而程序区名『 在屏幕上打印 "Hello world!" 字符串 』则处于引用状态。
程序区名的逆引用状态是由 zero 隐式生成的。例如,上文示例中的程序区:
@ 在屏幕上打印 "Hello world!" 字符串 # print("Hello World!/n");经 zero 的 day 模式的处理,变为:
@ 在屏幕上打印 "Hello world!" 字符串 # print("Hello World!/n"); => @ hello.c 文件 # 程序区名『 hello.c 文件 』是 zero 自动生成的,表征程序区『 在屏幕上打印 "Hello world!" 字符串 』被程序区『 hello.c 文件 』引用。
zero 默认的 day 模式,只对程序区名进行处理,而对程序区中的代码原样输出。不过,zero 可以将程序区文本输出至一个临时的文本文件,然后通过某个外部程序对程序区文本进行格式化处理。目前,zero 项目提供两个程序 mkd 与 ctxmkiv 用于处理含有 C 代码的程序区,前者可输出 Markdown 排版格式文本,后者输出 ConTeXt MkIV 排版格式文本。程序区文本,经过 mkd 或 ctxmkiv 这样的程序处理后,可以产生比 zero 元文档更丰富的排版格式。这一过程类似于阳光透过棱镜发生了色散,所以 mkd 与 ctxmkiv 这样的程序被称为棱镜。
对于示例文件 hello.zero,若采用 ctxmkiv 棱镜程序来处理它的程序区排版,可使用以下命令:
$ zero --mode=day --prism=ctxmkiv --output=hello.tex hello.zero或
$ zero -m day -p ctxmkiv -o hello.tex hello.zeromkd 棱镜主要工作是对程序区文本进行了渲染,并为处于引用与逆引用状态的程序区名设置了超级链接。若将对上文示例改写为 Markdown 格式:
下面我们用 C 语言写一个 Hello World 程序: @ hello.c 文件 # #include <stdioi.h> int main(void) { # 在屏幕上打印 "Hello world!" 字符串 @ return 0; } @ 可使用 C 标准库提供的 `printf` 函数在终端屏幕上显示文本,即: @ 在屏幕上打印 "Hello world!" 字符串 # print("Hello World!/n"); @ 编译这个程序的命令为: $ gcc hello.c -o hello然后使用 mkd 棱镜对其进行处理,即:
$ zero -m day -p mkd -o hello.markdown hello.zero则其中两个程序区会被处理为:
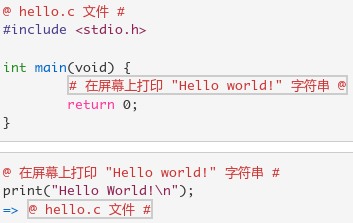
图中灰色矩形框内的文本含超级链接,可以跳转到相应的程序区首部。
示例
完成 zero 之后,我试着用它写了一个 k 均值聚类程序。这个程序的 zero 元文档以及 ConTeXt 排版结果可从以下地址下载:
-
km.zero: http://rca.is-programmer.com/user_files/rca/File/programming/km.zero
-
km.pdf: http://rca.is-programmer.com/user_files/rca/File/programming/km.pdf
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

