MongoDB和数据流:实现一个MongoDB Kafka消费者
作者:Andrew Morgan
译者:仲培艺,关注数据库领域,纠错、寻求报道或者投稿请致邮:zhongpy@csdn.net。
数据流
在当前的数据领域,单独一个系统无法支撑所有的请求。想要分析数据,则需要来源多样的海量信息数据。
同时,我们迫不及待地渴求着答案;如果洞悉一切所需的时间超过了数十毫秒,信息就失去了价值——类似于高频交易、欺诈侦测和推荐引擎这一类应用程序,更是经不起这样的等待消耗。这通常要求在流入的数据被存入数据库之前,就对其进行分析。对数据丢失的零容忍和更多挑战的出现,无疑使其更为棘手。
Kafka和数据流侧重于从多元fire-hose中获取大量数据并将其分输至需要这些数据的系统——通过筛选、聚合和分析的方法。
这篇博文介绍了Apache Kafka,并举例分析了如何将MongoDB用作流式数据的源(生产者)或目标(消费者)。关于这一主题, 数据流和Kafka & MongoDB 白皮书提供了更为完备的研究。
Apache Kafka
Kafka提供了一个灵活、可扩展且可靠的方法,用以在一个或多个生产者与消费者之间进行事件数据流交流。事件例子包括:
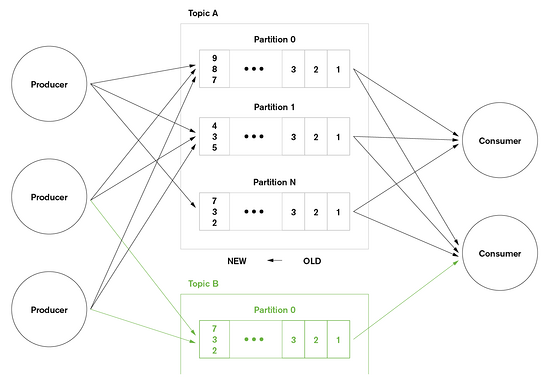
Kafka事件流被归纳为几个主题。每个生产者选择一个主题来发送指定事件,而消费者则根据所需主题来提取事件。例如,一个财经应用可以根据一个标题来提取关于纽约证券交易所(NYSE)股票交易事件;若为求交易机会,则可根据另一个标题来提取公司财务报告。
Kafka中的标题被进一步细分为支持扩展的分区。每一个Kafka节点(代理)负责接收、存储并传递来自指定主题一个或多个分区的事件。按照这个方法,一个主题的处理和存储可以线性扩展覆盖多个代理。也可以通过相似的方法来扩展一个应用——让多个消费者根据一个指定标题来提取时间,每一个事件都来源自独立分区。
Kafka消费者MongoDB——Java示例
为了使MongoDB成为一个Kafka消费者,必须要保证所接收的信息在存入数据库之前,已被转换成BSON文档。此处,事件是代表JSON文档的字符串。而字符串则被转换成Java对象,故而便于Java开发者应用;这些对象随后被转换为BSON文档。
完成源码Maven配置,会发现测试数据更低,但仍有一些重点;从主循环开始,依据Kafka主题接收并处理事件信息。
Fish class包括隐藏对象转换成BSON文档路径的辅助方法:
在实际应用中,有关信息的接收还有更多事情有待解决——这些信息和MongoDB参考数据读数相结合,然后通过发布到附加主题,沿着流水线操作并传递信息。此处,最后一步是通过mongo shell来确认数据已存入数据库:
MongoDB Kafka消费者的完整Java代码
商业对象——Fish.java
MongoDB的Kafka消费者——MongoDBSimpleConsumer.java
注意此处的消费者用Kafka Simple Consumer API写入——还有一个相对不那么复杂的Kafka High Level Consumer API——包括管理offsets。Simple API加强了对应用的控制,但代价是写附加码。
Maven Dependencies – pom.xml
测试数据——Fish.json下面是一个Kafka中插入测试数据的样例:
为了进行simple testing,可以用 kafka-console-producer.sh 指令将数据插入clusterdb-topic1主题。
下面的步骤
想要进一步了解数据流以及MongoDB是如何适应的(包括Apache Kafka和其竞争互补技术在内的这些内容),可以读数据流和Kafka & MongoDB白皮书。
关于作者——Andrew Morgan
Andrew,MongoDB主要产品营销经理,曾在Oracle工作超过六年,在那里他负责产品管理,主管High Availability。可以通过邮箱 @andrewmorgan 或者他的博客( clusterdb.com )评论与他取得联系。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

