分布式一致性论文阅读阶段性小结
这个月阅读集中在分布式一致性和存储方面。
首先是 Paxos 系列论文:
-
《Paxos Made Simple》 ,循循渐进地讲解 paxos 解决的问题、逐步增强的约束条件(P1、P2、P2a – P2c)等,P1 保证至少有一个值被接受, P2 保证只有一个被选中的值被所有 process 接受。然后介绍两阶段的步骤:
- Phase 1.
- (a) A proposer selects a proposal number n and sends a prepare request with number n to a majority of acceptors. * (b) If an acceptor receives a prepare request with number n greater than that of any prepare request to which it has already responded, then it responds to the request with a promise not to accept any more proposals numbered less than n and with the highest-numbered pro- posal (if any) that it has accepted .
- Phase 2.
- (a) If the proposer receives a response to its prepare requests (numbered n) from a majority of acceptors, then it sends an accept request to each of those acceptors for a proposal numbered n with a value v, where v is the value of the highest-numbered proposal among the responses, or is any value if the responses reported no proposals . * (b) If an acceptor receives an accept request for a proposal numbered n, it accepts the proposal unless it has already responded to a prepare request having a number greater than n.
- Phase 1.
加粗的两句话就是 paxos 的核心,一个是 acceptor 的承诺,一个是 proposer 的选择。达成一致的值之后,接下来论文讨论了其他 process 学习机制和 liveness 问题,paxos 无法解决活锁问题,但是实际应用中这个问题可以通过选举一个唯一的 proposer 来避免。接下来谈到实现,说明一个 Replication State Machine 的实现问题,着重讨论了 leader failure 情况下的『空洞』问题,通过引入 no-op commands 来减少服务中断时间。但是这篇论文没有明确提到 multi paxos 的介绍,这就需要继续阅读其他论文和博客来理解。
-
《Paxos Made live》 。这篇论文是 Google 发表的,讨论了 paxos 的工程实践,也就是 chubby 这个众所周知的分布式服务的实现,可以结合 《The Chubby lock service for loosely-coupled distributed systems》 一起看。实际应用中的难点,比如 master 租约实现、group membership 变化、Snapshot 加快复制和恢复以及实际应用中遇到的故障、测试等问题,特别是最后的测试部分。非常值得一读。 《The Chubby lock service for loosely-coupled distributed systems》 更多介绍了 Chubby 服务本身的设计决策,为什么是分布式锁服务,为什么是粗粒度的锁,为什么是目录文件模式,事件通知、多机房部署以及应用碰到的使用问题等等。
-
Paxos Made Practical 。这篇论文更详细地讨论了 State Machine 的实现,甚至还带上了 C语言的伪代码,定义了 prosper 、 acceptor 以及 SM 本身需要实现的接口和通讯协议,更重要的是讨论了 membership change 的问题,通过引入 view 视图的概念,介绍了 view-change 协议来解决成员变动问题(可能是故障或者上下线新成员),按我的理解,这个过程也是 paxos 的应用。最后介绍了可能的优化手段。
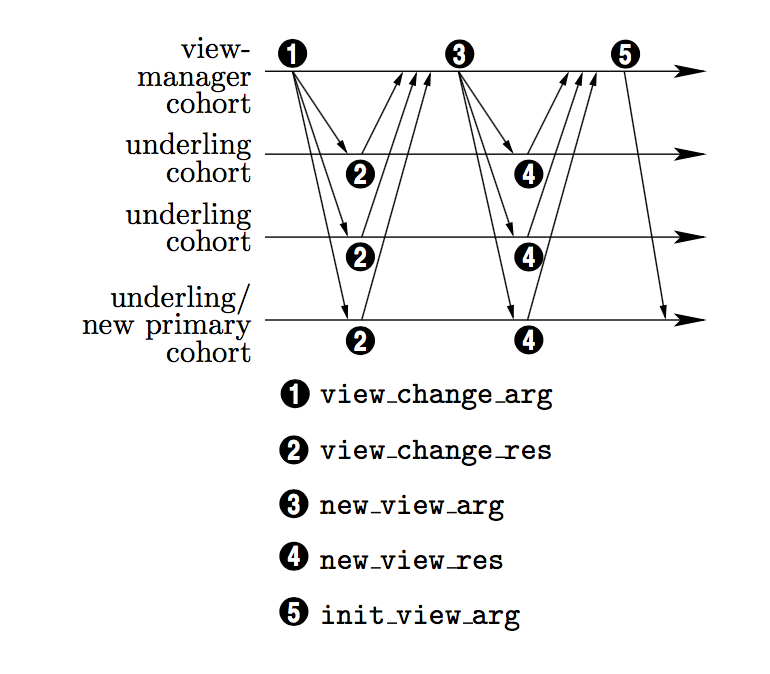 (view change 协议)
(view change 协议)
- Paxos 我还着重推荐阅读微信后端团队写的 系列博客 ,包括他们开源的 phxpaxos 实现,基本上将所有问题都讨论到了,并且通俗易懂。
其次,一致性方面另一块就是 Raft 算法,按照 Google Chubby 论文里的说法,
Indeed, all working protocols for asynchronous consensus we have so far encountered have Paxos at their core.
但是 Raft 真的好理解多了,我读的是 《In Search of an Understandable Consensus Algorithm》 ,论文写到这么详细的步骤,你不想理解都难。毕竟 Raft 号称就是一个 Understandable Consensus Algorithm。无论从任何角度,都推荐阅读这一篇论文。
首先能理解 paxos 的一些难点,其次是了解 Raft 的实现,加深对 Etcd 等系统的理解。这篇论文还有一个 250 多页的加强版 《CONSENSUS: BRIDGING THEORY AND PRACTICE》 ,教你一行一行写出一个 Raft 实现,我还没有学习,有兴趣可以自行了解。Raft 通过明确引入 leader(其实 multi paxos 引申出来也有,但是没有这么明确的表述)来负责 client 交互和日志复制,将整个算法过程非常清晰地表达出来。Raft 的算法正确性的核心在于保证 Leader Completeness ,选举算法选出来的 leader 一定是包含了所有 committed entries 的,这是因为所有 committed entries 一定会在多数派至少一个成员里存在,所以设计的选举算法一定能选出来这么一个成员作为 leader。多数派 accept 应该说是一致性算法正确性的最重要的保证。
最后,我还读了 《Building Consistent Transactions with Inconsistent Replication》 ,包括作者的 演讲 ,作者也开放了 源码 。Google Spanner 基本是将 paxos 算法应用到了极致,但是毕竟不是所有公司都是这么财大气粗搞得起 TrueTime API,架得起全球机房,控制或者承受得了事务延时。这篇论文提出了另一个思路,论文介绍的算法分为两个层次: IR 和基于其他上的 TAPIR。前者就是 Inconsistent Replication,它将操作分为两类:
- inconsistent: 可以任意顺序执行,成功执行的操作将持久化,支持 failover。
- consensus:同样可以任意顺序执行并持久化 failover,但是会返回一个唯一的一致(consensus)结果。
IR 的调用图:
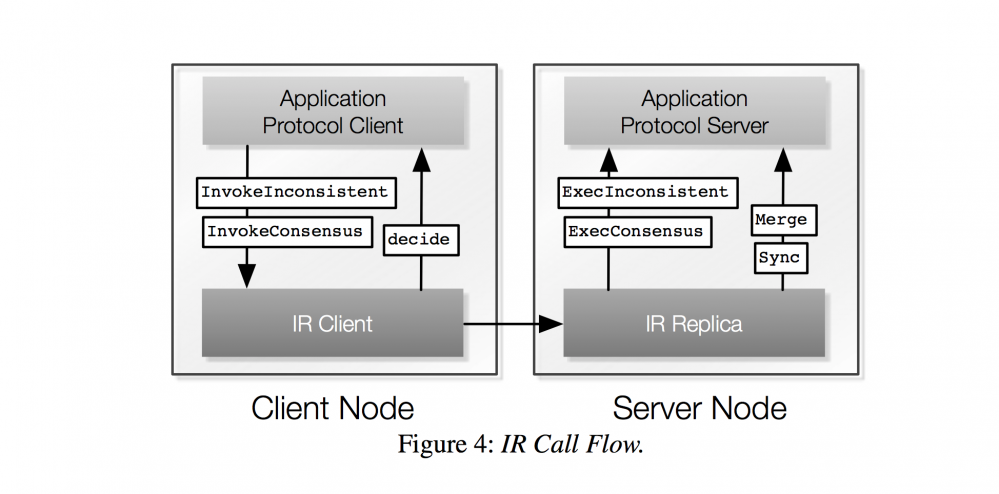
可见他需要服务端和客户端共同参与,对于 consensus 操作,如果 replicas 之间有冲突,会在客户端引入一个 decide 过程来决定使用哪一个值,相应地,在服务端为了解决 master 和 replicas 的不一致问题,引入了 sync/merge 过程来解决冲突,master 运行 merge 过程来解决 consensus 操作的副本冲突,而所有节点运行 sync 过程来同步 master 记录。关于 sync/master 的描述看原文:
"Some replicas may miss operations or need to reconcile their state if the consensus result chosen by the application (i.e., transaction) protocol does not match their result. To ensure that IR replicas eventually converge, they periodically synchronize. Similar to eventual consistency, IR relies on the application (i.e., transaction) protocol to reconcile inconsistent replicas. On synchronization, a single IR node first upcalls into the application protocol with Merge, which takes records from inconsistent replicas and merges them into a master record of successful operations and consensus results. Then, IR upcalls into the application (i.e., transaction) protocol with Sync at each replica. Sync takes the master record and reconciles application (i.e., transaction) protocol state to make the replica consistent with the chosen consensus results."
为了保证正确性,IR 对上层应用层协议有特殊的要求:
- Invariant checks must be performed pairwise.也就是要求任意两个 consensus 操作,其中一个至少对另一个是可见的。不然无法检测是否冲突。
- Application protocols must be able to change consensus operation results.对于已经达成一致的结果,还要允许是可以被修改的,merge 过程会修改原来认为的一致的结果,这是不一致复制必然带来的问题。
- 性能原则 1:Application protocols should not expect operations to execute in the same order. 对于顺序不要有任何假设。
- 性能原则 2:Application protocols should use cheaper inconsistent operations whenever possible rather than consensus operations. 尽量用 inconsistent 操作。比如在 TAPIR 里只有 prepare 是 consensus 类型操作。
正因为对于应用层协议有这么多的限制,因此论文提出了 TAPIR 这个算法来解决事务的 linearizable ordering 问题。TAPIR 的具体算法请阅读论文吧,这里不再复述。大体的思路就是客户端参与事务的冲突检测(OCC validation checks),Leader 执行IR 的 merge 过程,对于还没有committed 的事务(可能 abort ,也可能来不及提交),重新跑一遍 OCC 检测冲突,根据结果来决定最终是提交还是回滚。
对于复制和恢复的描述:
TAPIR’s sync function runs at the other replicas to reconcile TAPIR state with the master records, correcting missed operations or consensus results where the replica did not agree with the group. It simply applies operations and consensus results to the replica’s state: it logs aborts and commits, and prepares uncommitted transactions where the group responded PREPARE-OK.
传统两阶段提交, Google spanner 之类的思路:
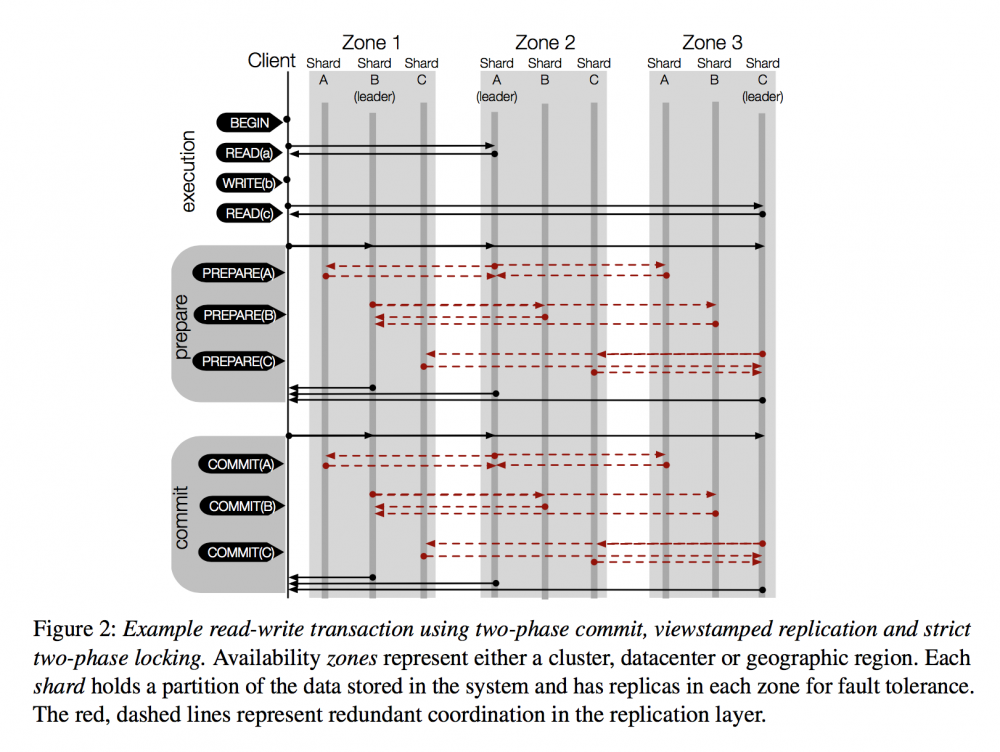
TAPIR 的流程:

关于 TAPIR 的解读推荐两篇博客: Building Consistent Transactions with Inconsistent Replication 和 Paper review: Building Consistent Transactions with Inconsistent Replication (SOSP’15) 。 TAPIR 的源码只包含了 normal case 的处理,恢复之类的过程都是没有的,对于 recovery 的一些疑问,可以参考 A FEW WORDS ABOUT INCONSISTENT REPLICATION (IR) ,同样也是我的疑问,这在实际工程中是非常重要的部分,但是论文却是匆匆带过。
最近还回顾了不少分布式存储的论文, GFS、BigTable、Dynamo 等,改天再做个总结吧。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

