在 IBM ODM Decision Server Insights 中给热实体降温
在大容量事件处理系统中,比如 IBM® Operational Decision Manager (ODM) 中的 Decision Server Insights,被数千个事件引用的实体实例被称为 “热实体”。热实体会减缓处理速度,成为系统内唯一的事件使用者。这种情况会导致整个多处理网格等待一个线程的完成。
本教程旨在帮助 Decision Server Insights 架构师和开发人员构建没有热实体的解决方案。了解导致热实体的原因和避免它们的技巧。
在大部分入站事件传送到少量热实体时,事件处理系统就会出现问题。热实体问题不仅在于过多的事件让一个实体不堪重负,还在于因为接收事件的实体越来越少而逐步降低性能。在下表中,可以看到当能处理入站事件的实体低于 200 个时,事件摄取量(每秒摄取的事件)呈线性减少。该表表明本教程中的 Decision Server Insights 示例解决方案的性能在降低。根据您自己的解决方案和硬件,具体的数量可能会有所不同。
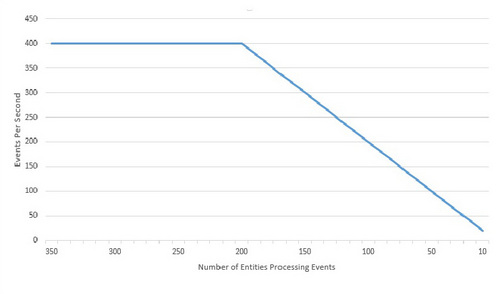
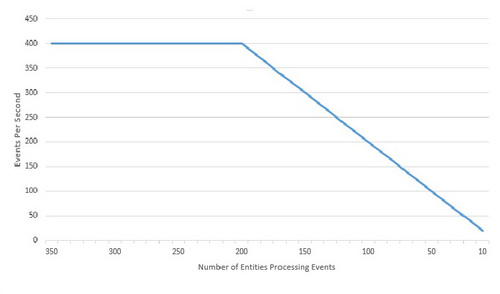
设计糟糕的 Decision Server Insights 解决方案允许热实体减缓事件摄取,直到网格停止。在最糟的情况下,解决方案会面临以下问题:
- 入站事件队列装满,迫使 Decision Server Insights 解决方案拒绝未来的事件。
- 数百万个事件传输到一个热实体,需要数天时间才能清理完这些事件。
本教程给出 3 个示例解决方案,解释了如何识别热实体,并介绍了避免它们的方法。第一个解决方案完全没有热实体保护,第二个具有部分保护,第三个拥有全面的热实体保护。
热实体类型
您可能遇到以下 3 种类型的热实体:
- 良性热实体,它们导致的细微性能问题可以忽略不计。
- 永久热实体,它们始终会导致问题。
- 隐含热实体,它们偶尔会导致问题。
良性热实体 花几分钟来处理一大批事件,这会导致近实时的事件检测,而不是实时检测。除非实时事件检测至关重要,否则良性热实体通常不是问题。
永久热实体 导致严重的性能问题,但问题可在开发过程中轻松识别,并在部署到生产环境之前解决。
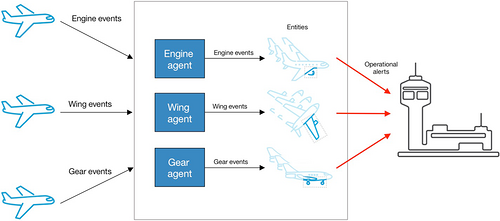
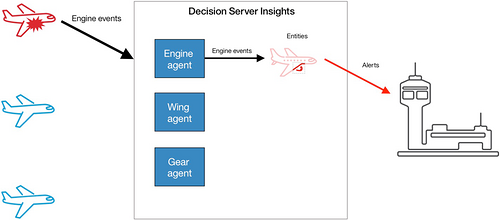
隐含热实体 最容易出现问题,只能在解决方案上线后识别。例如,想象一个接收 飞机事件 的飞机监控系统,如下图所示。这些事件被发送到一个 飞机代理 ,该代理与一个或多个 飞机实体 相关联。在正常操作下,所有飞机发出状态事件,这些事件均匀地分散在所有飞机中。但是,如果有一架飞机开始出现故障,它会向一个飞机实体实例发出大量警告事件。此实体实例就变成大部分飞机事件的使用者,这个实体就会变热。
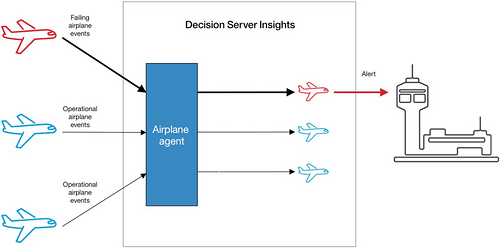
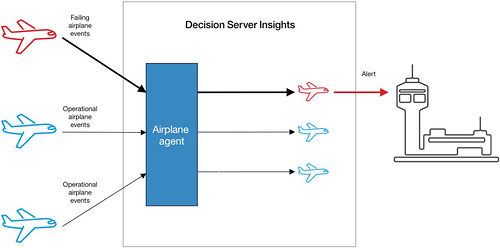
避免热实体的技巧
现在介绍重新设计解决方案来避免热实体的技巧。
技巧 1:分而治之
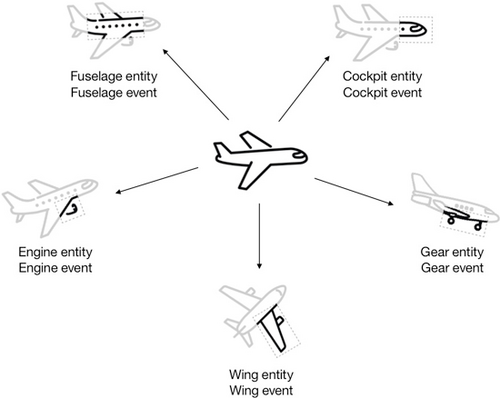
避免会使用复杂事件的复杂实体。将复杂实体和事件分解为更小的部分。如下图所示,飞机事件和飞机实体被拆分为更小的组件实体: 机身实体 、 驾驶舱实体 、 引擎实体 、 机翼实体 和 起落架实体 。每个组件实体接收飞机发出的一个事件子集,这减少了出现热实体的可能性。

技巧 2:解决规则代理性能
在一个实体实例无法采用以事件到达的速度来使用事件时,就会出现热实体。一个原因可能是您的规则代理的性能太慢了。这可能是因为您的解决方案有较大的事件范围。
检查您是否需要较大的事件范围。您能否在实体中存储事件历史的摘要?例如,考虑一条对引擎警告计数的规则。无需使用事件历史来统计警告事件数量,在引擎实体上添加一个警告计数器可能更好一些。
另一种提高性能的方法是将规则代理重写为 Java™ 代理。如果您的规则是技术性的,而且将逻辑表达为业务规则没有实际好处,那么可以考虑这种方法。
技巧 3:避免对每个事件执行昂贵的 OSGi 调用
检查您的规则,看看是否需要在每次收到事件时执行昂贵的 Open Source Gateway Initiative (OSGi) 调用。例如,如果您调用预测分析软件,比如 IBM SPSS Statistic,是否需要对每个事件都执行该调用?或者,是否可以通过引入另一个接收事件摘要的代理来减少调用频率?本教程后面将解释此概念。
技巧 4:克隆实体
如果您采用了技巧 1-3,但是仍然有热实体,那么可以考虑使用以下模式来克隆实体。技巧 1 中的方法将实体拆分为逻辑构成部分,而此模式将 同一个 实体克隆 n 次。每个克隆实体使用整个对象的事件总量的 1/n 。有关此模式的更多信息,请参阅相关小节。
您的解决方案是否会遇到热实体?
要确定您的 Decision Server Insights 解决方案是否容易产生热实体,可采用下面这个公式:
hot entity potential = inbound EPS / (instance EPS * min instances)
假设 inbound EPS 是每秒保持的入站事件量。
假设 instance EPS 是一个实体实例每秒可处理的最大事件量。
假设 min instances 是处理入站事件所涉及的最少的实体实例数量(最糟的情况)。
如果您的热实体潜力大于 1,那么解决方案中就会面临存在热实体的风险。该值越高,风险就越大。
冷实体示例
inbound EPS 值为 100, instance EPS 值为 50, min instances 值为 4:
100 / (50 * 4) = 0.5
热实体潜力为 0.5 ,表明这是一个冷解决方案。
热实体示例
inbound EPS 值为 100, instance EPS 值为 50, min instances 值为 1:
100 / (50 * 1) = 2
这一次热实体潜力为 2 ,表明这是一个热解决方案。如果存在出现热实体的风险,可应用上一节中的技巧来解决它们。
下一节将介绍如何根据与遇到热实体的 IBM ODM 客户的实际工作,向一个示例应用这些技巧。深入剖析简介中演示的飞机监控系统示例的 3 个不同的 Decision Server Insights 实现。第一个解决方案最简单,但最容易出现热实体。第二个解决方案应用分而治之模式来降温,但仍可能出现问题。第三个解决方案实施了全面的热实体保护。
示例解决方案 1:没有优化的机场监控解决方案
前面的 “热实体类型” 部分已给出了实现该机场监控解决方案示例的第一次尝试。飞机实体与飞机事件相关联。如下面的代码清单所示,一个飞机实体记录一架飞机的飞行数据:
清单 1. 飞机实体
/****** Airplane Entity ******/ an airplane is a business entity identified by an airplane id . an airplane has an average engine exhaust temperature (integer ) . an airplane has an average engine pressure ratio (integer ) . an airplane has an average engine rpm (integer ) . an airplane has an wing warnings (integer ) . an airplane has an cockpit warnings (integer ) . an airplane has an fuselage warnings (integer ) . an airplane has an gear warnings (integer ) . an airplane has an event count (integer ) .
飞机事件由飞机定期发出,以提供飞行数据,如下面的代码清单所示:
清单 2. 飞机事件
/****************** Airplane Event ******************/ an airplane event is a business event time-stamped by a timestamp ( date & time ) . an airplane event has an aircraft id . an airplane event has an engine . an airplane event has a wing . an airplane event has a gear . an airplane event has a cockpit . an airplane event has a fuselage . a wing is a concept . a wing has a lift ( integer ) . a fuselage is a concept. a fuselage has a pressure ( integer ) . a cockpit is a concept . a cockpit has a altitude ( integer ) . a cockpit has a speed ( integer ) . a gear is a concept . a gear has a gear state ( a gear status ). a engine is a concept . an engine has a pressure ratio ( integer ) . an engine has a rpm ( integer ) . an engine has a exhaust temperature ( integer ) . a gear status can be one of: UP, DOWN, STUCK.
飞机实体被绑定到飞机代理,代理接收飞机事件。飞机代理包含以下规则。
业务规则
如下面的 Insight Designer 屏幕截图所示,有 6 条监控飞机的业务规则:
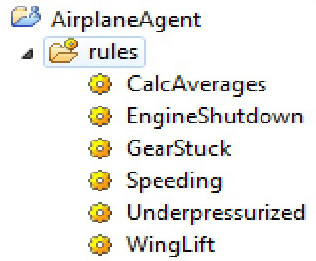
有两个引擎规则。第一个是 CalcAverages ,用于计算引擎参数的滚动加权平均值,如下面的代码清单所示:
清单 3. CalcAverages 规则
when an airplane event occurs
then
define rpmAverage as ( the average engine rpm of 'the airplane' +
the rpm of the engine of this airplane event ) / 2 ;
define pressureAverage as ( the average engine pressure ratio of 'the airplane' +
the pressure ratio of the engine of this airplane event ) / 2 ;
define exhaustTempAverage as ( the average engine exhaust temperature of 'the airplane' +
the exhaust temperature of the engine of this airplane event ) / 2 ;
set the average engine rpm of 'the airplane' to rpmAverage;
set the average engine pressure ratio of 'the airplane' to pressureAverage;
set the average engine exhaust temperature of 'the airplane' to exhaustTempAverage;
set the event count of 'the airplane' to the event count of 'the airplane' + 1 ;
第二个引擎规则是 EngineShutdown ,它应用前面的代码清单中计算的平均值来预测引擎故障。如下面的代码清单所示,运行一个 IBM SPSS Statistics 分析算法来确定故障概率。如果概率超过 8,则发出引擎关闭事件。
清单 4. EngineShutdown 规则
when an airplane event occurs
if
calculate engine failure probability ( the average engine exhaust temperature of 'the airplane' ,
the average engine pressure ratio of 'the airplane' ,
the average engine rpm of 'the airplane' ) is more than 8
then
emit a new actionable event where
the operator action is ENGINE_ERROR ,
the reason is "Engine Failing on " + the aircraft id,
the aircraft id is the aircraft id of this airplane event ,
the timestamp is now ;
在此解决方案中,IBM SPSS Statistics 对 'calculate engine failure probability' 的调用是一次模拟调用。
现在您可以在 Github 上探索该解决方案中提供的剩余规则。
运行示例解决方案 1
- 访问 http://github.com/ncrowther/CoolingHotEntities
- 下载示例代码。
- 将内容解压到方便的位置。
- 打开 Insight Designer。
- 单击 File > Import 并选择 General > Existing Projects into Workspace 。
- 将下载的
JetSolution1文件夹下的所有项目导入 Insight Designer 中。 - 如果看到
Generate Java Model错误,请右键单击 JetSolution 项目并选择 Configure > Migrate Solution 。 - 在您的本地机器上启动 cisDev Decision Server Insights 服务器。
- 右键单击 JetSolution 项目并选择 Deploy > Deployment Configurations 。
- 单击 New,创建一个名为 JetSolution 的部署。
- 选择 Local server 。然后单击 Next 。
- 选择 Disable SSL hostname verification 和 Disable server certificate verification ,单击 Next 。
- 选择 Create new connectivity server configuration ,单击 Next 。
- 确保所有选项都已选择(Inbound Endpoints、HTTP 和 InboundHttpEndpoint),单击 Finish 。
- 该解决方案应部署到您本地的 cisDev Decision Server Insights 服务器实例。在控制台中检查以下消息:
CWMBE1452I:Successfully deployed connectivity for the solution "JetSolution"。 - 在 Insight Designer 中,转到 JetStatusTester 项目,打开 Event Sequences 文件夹下的 JetStatusTestSeq.eseq 。
- 在项目的顶级目录中,编辑
testdriver.properties,确保trustStoreLocation被设置为您的 Decision Server Insights 安装路径。 - 右键单击 JetStatusTestSeq.eseq ,选择 Run As > Event Sequence 。
- 选择 Enable recording 、 Reset solution state 和 Delete all entries ,单击 Run 。
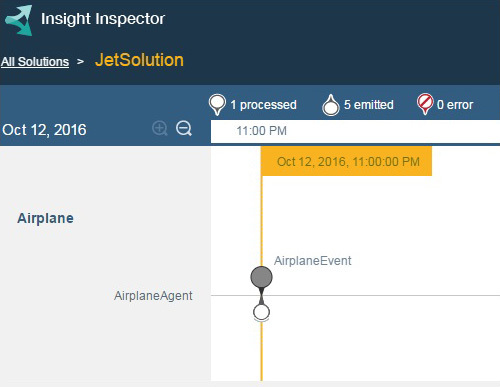
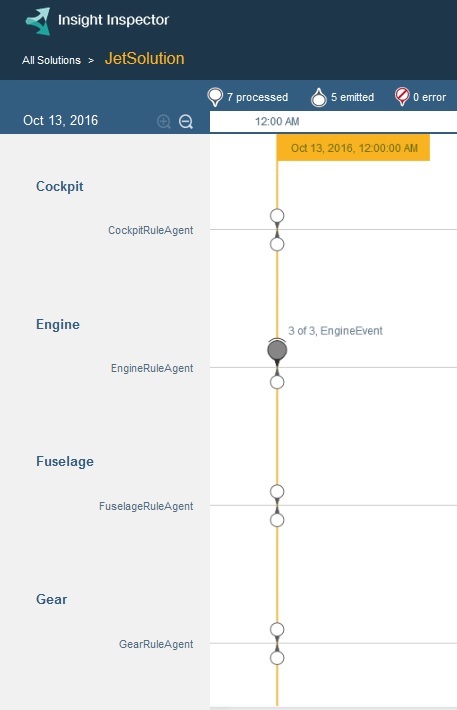
脚本将会运行,并将一个或多个事件发送到解决方案中。各项规则将触发,并创建 可操作的事件 供飞行控制团队处理。一条记录捕获所有提交和发出的事件,将处理每个事件之前和之后的实体状态存储在一个可在 Insight Inspector 中查看的文件中。 - 在 Insight Inspector 中打开以下记录,以查看事件:
https://localhost:9443/ibm/insights/view?id=JetSolution-0.0。 - 在 Insight Inspector 中,确认所有事件都集中在一个飞机实体上,而且该实体是热实体,如下面的屏幕截图所示:

示例解决方案 2:应用分而治之模式
第一个示例解决方案的问题在于,飞机实体是热实体。示例解决方案 2 对飞机事件采用了一种分而治之模式,将它拆分为多个组成部分,比如 引擎 、 机翼 和 起落架 。
在示例代码中,可以看到飞机实体和飞机事件都被拆分为多个部分,如下面的屏幕截图所示:

将飞机事件拆分为组件事件,不仅可以提高性能,还能使您无需更改事件结构即可配置飞机的组件数量。
运行示例解决方案 2
按照 JetSolution1 的所有构建和运行指令操作,但这一次导入 JetSolution2 。
- 在 Insight Inspector 中打开以下记录,以查看事件:
https://localhost:9443/ibm/insights/view?id=JetSolution-0.0。 - 您应该在 Insight Inspector 中看到下面的屏幕截图中显示的实体:
从 Insight Inspector 中确认,事件现在被分解为不同组件,这样做不仅提高了性能,还降低了出现热实体的可能性。要进行确认,可以运行一个性能测试器,如下一节所述。
对示例解决方案 2 运行性能测试器
现在运行一个 Java 程序,以便对引擎组件执行压力测试。
要运行性能测试器,请完成以下步骤:
- 打开
JetSolution2中的 HttpPerformanceTester 项目。 - 转到
src/dsi文件夹并打开DSISendEvent.java。 - 在
main()方法的开头 , 设置以下值:NUMBER_OF_AIRPLANES = 50; NUMBER_OF_ENGINES = 2; NUMBER_OF_EVENTS = 500;
- 确认入站 HTTP 端点上的端口号对您的安装而言是正确的:
urlStr = "http://localhost:9080/jetstatus/InboundHttpEndpoint"; - 保存更改,右键单击
DSISendEvent.java并选择 Run as Java Application 来运行该程序。
在这里的日志中检查引擎代理活动:
Decision_Server_Insights_installation_directory/runtime/wlp/usr/servers/cisDev/logs/trace.log
https://localhost:9443/ibm/ia/rest/solutions/JetSolution/entity-types/entityModel.Engine跟预期一样,引擎实体已使用几秒内的最新引擎数据更新。
- 现在更改以下常量来模拟一个发出大量事件的引擎故障:
NUMBER_OF_AIRPLANES = 1;
NUMBER_OF_ENGINES = 1;
NUMBER_OF_EVENTS= 500; - 再次运行该程序,检查跟踪日志。这一次,处理 500 个事件就花了好几 分钟 。为什么?因为所有事件都定向到一个引擎实体实例,而且这个实例是热实体,如下面的屏幕截图所示:
示例解决方案 3:改进解决方案
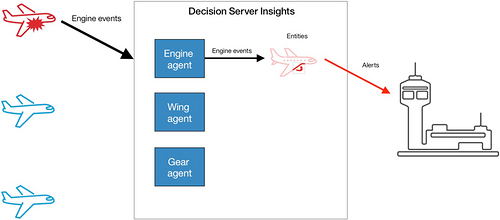
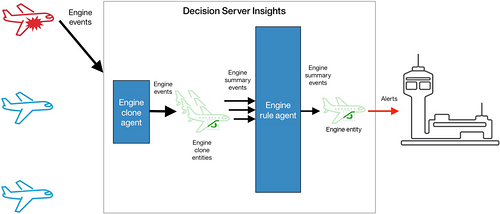
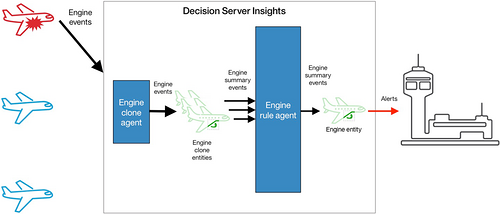
在示例解决方案 2 中,引擎实体是热实体。在引擎即将发生故障时,它接收了所有引擎事件。现在,在最后一个示例 3 中,应用了克隆模式来对飞机解决方案降温。每个引擎实例的引擎事件现在由 n 个引擎克隆实体中的一个使用。每个克隆实体都会汇总数据,并按定义的时间间隔将摘要传递给引擎代理。引擎规则代理中的业务规则判断引擎是否即将发生故障。此代理仅接收一个事件子集,所以它的绑定实体不是热实体。
当发生引擎事件风暴时,您会在解决方案中看到以下活动:
- 引擎事件发送到一个 引擎克隆代理 ,该代理被绑定到多个 引擎克隆实体 。
- 每隔 30 秒,每个引擎克隆实体都会将一个 引擎摘要事件 发送到 引擎规则代理 。
- 引擎规则代理被绑定到 引擎实体 。这些规则使用 引擎摘要事件 确定引擎是否正处在故障中。
此操作序列如下面的屏幕截图所示:
克隆模式实现
克隆模式的基础是 EngineCloneJavaAgent.java 。它将传入的针对某个引擎的事件风暴拆分到许多克隆实体中,以分散事件负载。每个克隆实体每隔 30 秒向引擎实体缓慢地发出摘要事件,所以它不再是热实体。代理 Java 类名为 EngineCloneJavaAgent.java 。
下面这个流程事件方法位于 EngineCloneJavaAgent.java Java 类中:
清单 5. 流程事件方法
@Override
public void process(Event event) throws AgentException {
if (event instanceof EngineEvent) {
// Summarize the Engine event
summarizeEngineEvent((EngineEvent) event);
}
}
如果事件是 EngineEvent 的实例,则调用下面这个 summarizeEngineEvent 方法:
清单 6. summarizeEngineEvent 方法
/**
* Summarize the Engine event
*
* @param engineEvent the engine event to be summarized
* @throws AgentException
*/
private void summarizeEngineEvent(EngineEvent engineEvent) throws AgentException,
EntityTypeException {
EngineClone engineClone = (EngineClone) getBoundEntity();
String EngineCloneName = engineEvent.getEngineCloneId();
String engineName = engineEvent.getEngineId();
if (conceptFactory == null) {
conceptFactory = getConceptFactory(ConceptFactory.class);
}
if (engineClone == null) {
printToLog(Level.INFO, "Creating a new engine Clone: "
+ EngineCloneName + " associated to engine: " + engineName);
engineClone = (EngineClone) createBoundEntity();
engineClone.setEngineId(engineEvent.getEngineId());
engineClone.setEngineCloneId(EngineCloneName);
engineClone.setAircraftId(engineEvent.getAircraftId());
engineClone.setAverageExhaustTemperature(engineEvent.getExhaustTemperature());
engineClone.setAverageRpm(engineEvent.getRpm());
engineClone.setAveragePressureRatio(engineEvent.getPressureRatio());
engineClone.setEventCount(1);
engineClone.set$CreationTime(engineEvent.getTimestamp());
// Load the bound entity back into the grid
updateBoundEntity(engineClone);
} else {
printToLog(Level.INFO,
"Calculate averages in engine Clone: " + EngineCloneName);
int eventCount = engineClone.getEventCount() + 1;
engineClone.setEventCount(eventCount);
int averagePressureRatio = (engineClone.getAveragePressureRatio() +
engineEvent.getPressureRatio()) / 2;
engineClone.setAveragePressureRatio(averagePressureRatio);
int averageRpm = (engineClone.getAverageRpm() + engineEvent.getRpm()) / 2;
engineClone.setAverageRpm(averageRpm);
int averageExhaustTemperature = (engineClone.getAverageExhaustTemperature() +
engineEvent.getExhaustTemperature()) / 2;
engineClone.setAverageExhaustTemperature(averageExhaustTemperature);
}
// Schedule call back to emit summary event after n seconds
if (!engineClone.isTimerRunning()) {
engineClone.setTimerRunning(true);
printToLog(Level.INFO,
"Timer started for : " + engineClone.getEngineCloneId());
final int TIMER_INTERVAL = 30;
schedule(TIMER_INTERVAL, TimeUnit.SECONDS, "");
}
updateBoundEntity(engineClone);
}
这个 summarizeEngineEvent 方法通过创建引擎参数的加权平均值来汇总 EngineEvent 。然后,它计划在 30 秒内通过一个回调(如果还未计划)来发出摘要事件。
每隔 30 秒,就会调用下面这个计时器回调方法:
清单 7. 计时器回调方法
@Override
// Timer callback method
public void process(String key, String cookie) throws AgentException {
EngineClone engineClone = (EngineClone) getBoundEntity();
if (engineClone != null) {
// Emit summary event to Engine Entity
emitSummaryEvent(engineClone);
// Delete the entity as its job is done
deleteBoundEntity();
}
}
这个计时器回调方法调用下面这个 emitSummaryEvent 方法来发送引擎摘要事件:
清单 8. emitSummaryEvent 方法
/**
* Emit an Engine Summary Event
*
* @param EngineClone the Engine clone bound entity
*/
private void emitSummaryEvent(EngineClone EngineClone) {
if (conceptFactory == null) {
conceptFactory = getConceptFactory(ConceptFactory.class);
}
EngineSummaryEvent engineSummaryEvent =
conceptFactory.createEngineSummaryEvent(ZonedDateTime.now());
engineSummaryEvent.setEngineId(EngineClone.getEngineId());
engineSummaryEvent.setAircraftId(EngineClone.getAircraftId());
engineSummaryEvent.setAveragePressureRatio(EngineClone.getAveragePressureRatio());
engineSummaryEvent.setAverageRpm(EngineClone.getAverageRpm());
engineSummaryEvent.setAverageExhaustTemperature(EngineClone.getAverageExhaustTemperature());
engineSummaryEvent.setEventCount(EngineClone.getEventCount());
try {
printToLog(Level.INFO,
"Emit Engine Summary Event from : " +
EngineClone.getEngineCloneId() + " to " +
EngineClone.getEngineId());
emit(engineSummaryEvent);
} catch (AgentException e) {
printToLog(Level.SEVERE, "Error emitting Engine Summary Event : "
+ engineSummaryEvent.get$Id());
e.printStackTrace();
}
}
发送摘要事件后,摘要代理删除绑定的实体。该代理仅在收到更多引擎事件时创建新克隆实体。
通过这种方式删除和再创建克隆实体,就可以实现内存弹性,这意味着仅在发生事件风暴时,内存中才会存在克隆实体。在没有事件风暴时,克隆实体会变少,在没有事件时,也没有克隆实体。
调优克隆参数
如果采用某种克隆模式,则需要在实时响应与内存使用之间进行权衡。
您可以通过两个参数 NUMBER_OF_CLONES 和 TIMER_INTERVAL 来控制实时响应和内存使用变量。
NUMBER_OF_CLONES 参数
要实现最佳的性能,可以对每个实体使用 10 个克隆实体。超过 10 个可能会占用太多内存,少于 10 个则可能仍会出现热实体。但是,您可以调优克隆实体数量,使之适合您的解决方案。
例如,如果您有一些始终很热的实体,那么可以增加克隆实体数量。如果您的许多实体很少变热,那么可以减少克隆实体数量来节省内存。
要更改示例解决方案 3 中的克隆实体数量,可以编辑 HttpPerformanceTester 项目中的 DsiEventXmlFactory.java 。编辑 NUMBER_OF_CLONES 常量,如下面的代码清单所示:
清单 9. 更改克隆实体数量
final int NUMBER_OF_CLONES = 10; final int engineCloneId = (int) (Math.random() * NUMBER_OF_CLONES);
Timer_Interval 参数
计时器间隔指定接收引擎事件与发送引擎摘要事件之间的时间延迟。延迟越长,摘要事件就越少。
如果您的解决方案需要更快的响应时间,可以减少计时器延迟。但是,需要知道此方法会增加摘要事件,这可能导致引擎实体再次变热。
要在摘要事件数量与近实时的情况检测之间达到良好的平衡,可使用 30 秒的延迟。
要更改解决方案 3 中的计时器间隔,可编辑 EngineCloneJavaAgent 项目中的 EngineCloneJavaAgent.java 。更改 TIMER_INTERVAL 常量,如下面的代码清单所示:
清单 10. 更改计时器间隔
final int TIMER_INTERVAL = 30; schedule(TIMER_INTERVAL, TimeUnit.SECONDS, "");
运行示例解决方案 3
要运行示例解决方案 3 的冷实体示例代码,需要完成以下步骤:
- 停止并使用
--clean选项重新启动 cisDev Decision Server Insights 服务器:server stop cisDev server start cisDev --clean
- 按照
JetSolution1的所有构建和部署指令进行操作,但这次导入JetSolution3。 - 打开 HttpPerformanceTester 项目
- 导航到
src/dsi文件夹并打开DSISendEvent.java。 - 在
main()方法的开头 , 设置以下值来模拟一个导致发出大量事件的引擎故障:
NUMBER_OF_AIRPLANES = 1; NUMBER_OF_ENGINES = 1; NUMBER_OF_EVENTS
= 500; - 检查日志。
这次,在检查活动日志时,您会看到一致的性能,无论您运行的示例是包含多架还是一架飞机。但是,需要认识到发出的事件不再是实时事件,而延迟量为计时器间隔,本例中的延迟时间为 30 秒。
检查这里的活动日志:
Decision_Server_Insights_installation_directory/runtime/wlp/usr/servers/cisDev/logs/trace.log
通过 REST API 检查引擎克隆实体。您会看到 10 个实体:
https://localhost:9443/ibm/ia/rest/solutions/JetSolution/entity-types/entityModel.EngineClone
请注意,引擎克隆实体仅在内存中存在很短的时间。在将它们的摘要信息发送到引擎实体后,就会删除它们。
通过 REST API 检查引擎实体。您会看到一个实体,其中包含来自 10 个克隆实体的所有信息:
https://localhost:9443/ibm/ia/rest/solutions/JetSolution/entity-types/entityModel.Engine
结束语
在本教程中,您学习了如何确认出现热实体的原因,以及哪些设计技巧有助于避免它们。您看到了 3 个示例 Decision Server Insights 解决方案。第一个解决方案没有热实体优化,第二个进行了部分优化,第三个进行了全面优化。
现在,您可以识别 IBM ODM Decision Server Insights 解决方案何时存在由热实体导致的性能问题,而且您拥有在未来预防这些问题的技巧。
致谢
感谢 Pierre Berlandier、Dan Selman 和 Ben Cornwell 审阅本教程。
正文到此结束
- 本文标签: java git 配置 CEO key Developer ACE 目录 端口 安装 时间 XML 性能问题 删除 IBM cat 代码 实例 final http id rpm 压力 GitHub URLs 开发 DDL IO 测试 线程 API DOM 参数 统计 ORM ssl tar IDE HTML 快的 entity Action 服务器 数据 App REST src Job update https UI CTO 软件 lib 下载
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

