Fregata: Spark上支持万亿维机器学习模型
作者:张夏天,TalkingData首席数据科学家。12年大规模机器学习和数据挖掘经验,对推荐系统、计算广告、大规模机器学习算法并行化、流式机器学习算法有很深的造诣;在国际顶级会议和期刊上发表论文12篇,申请专利9项;前IBM CRL、腾讯、华为诺亚方舟实验室数据科学家;KDD2015、DSS2016国际会议主题演讲;机器学习开源项目Dice创始人。
欢迎人工智能技术投稿、约稿、给文章纠错,请发送邮件至heyc@csdn.net
大规模机器学习工程上最大的挑战是模型的规模。在计算广告,推荐系统的场景下,运用Logistic Regression算法时常需要做特征交叉。原来两组,三组特征的数量可能并不是太大,但是通过交叉后可能会特征数会爆炸。例如,用户特征数1万,广告特征数1万,那么交叉后总特征数就是1亿,如果再与几十个广告位特征交叉,总特征数就会达到几十亿。有些情况下,特征交叉后,总数甚至能达到上千亿。特征数量的爆炸,也带来模型规模的爆炸,这给机器学习带来的挑战比庞大的训练数据量更大。
通常认为,当模型的规模超过单节点的容量后,基于MapReduce计算模型的Spark, Hadoop MapReduce就无法支持了。为了解决这一问题,Parameter Server应运而生,目前是大规模机器学习研究方面的前沿。目前Parameter Server还在发展的过程中,其使用,开发门槛相较于Spark来说都是较高的,而且在大数据平台中再引入一套新的计算平台,对整个体系的管理,运维都将带来更大点挑战。
Fregata致力于在Spark上解决大规模机器学习的问题,Fregata目前已经公开发布的版本已经能支持亿级维度的模型,而目前内部最新版本已经在一个月内连续突破了10亿,100亿,1000亿和10000亿4个台阶。在模型规模提高了4个数量级的同时保持了训练的高效性。下面是 Fregata的Logistic Regression算法在511412394个样本的训练集下的训练时间:
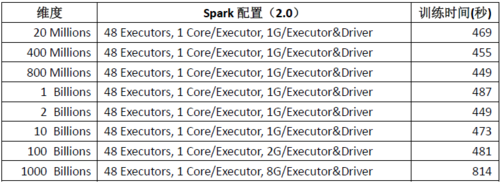
从上表可以看出,对于5亿多样本的训练集,在仅使用48个Executor的情况下,千亿维度以内的问题,都可在500秒内完成,而且每个Executor仅需最多2G内存。对于万亿维度的问题,训练时间也仅需800秒多一点,只是Executor的内存加到了8G。Fregata最近的突破,打破了在Spark上无法支持超大规模模型的瓶颈,将进一步降低大规模机器学习的使用门槛和成本。
Fregata 项目地址: https://github.com/TalkingData/Fregata
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

