一步步图解G1
G1在堆上分配内存和其他的GC有点不一样。现在我们来一步一步看下G1系统。
1、 G1堆结构
G1的堆结构就是把一整块内存区域切分成多个固定大小的块。

在JVM在启动时来决定每个小块,也就是region的大小。 JVM一般是把一整块堆切分成2000个小region。然后每个小region从1到32Mb不等。
2、 G1内存分配
事实上,这些region最后又被分别标记为Eden,Survivor和old。这里的eden,survivor和old已经是一个标签,也就是说只是一个逻辑表示,不是物理表示。
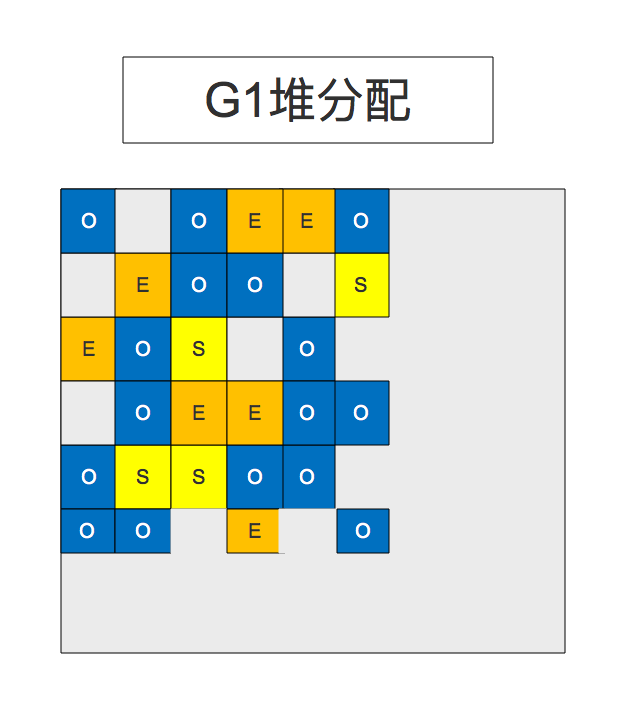
O表示老生代(Old),E表示Eden,S表示Survivor。为了明了,我们分别用三种不同的颜色区分。存活下来的对象就被虚拟机从一个小region里被移动到另一个中。这些小块(region)的回收是并行回收的,期间其他的应用线程照常工作。和以往的回收器一样,G1中也有Eden,survivor,old。在这三个之外,还增加了第四种类型,叫Humongous。这个单词翻译过来就是“堆积如山”的意思。这个类型主要是用来存储那些比标准块大50%,甚至更大的那些对象。这些大对象被保存到一整块连续的区域。这个堆积如山区就是堆里没有被使用的区域。
需要注意的是,这个堆积如山区目前还没有被优化到最佳,所以你还是尽量不要创建这么大的对象。
3、G1中的年轻代
整个堆被分成大约2000个小区域块。最大的块32Mb,最小的1Mb。蓝色的块用来存储老生代对象,绿色的用来存储年轻代对象。
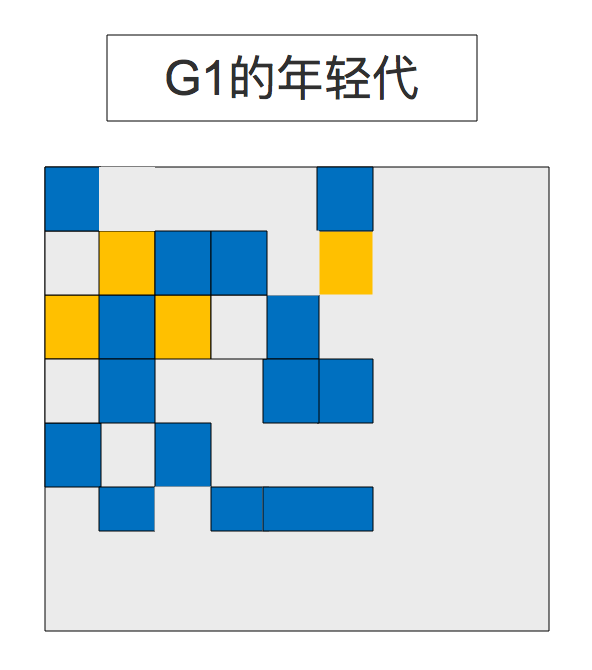
记住一点:G1不是像老一辈的那些垃圾回收器一样要求每一代的块是连续的,在G1中可以不是连续的。
4、G1中的一次Young GC
存活的对象被转移到一个/或多个survivor 块上去。 如果存活时间达到阀值,这部分对象就会被晋升到老年代。
 此时会有一次 stop the world暂停,会计算出 Eden大小和 survivor 大小,用于下次young GC。统计信息会被保存下来,用于辅助计算size。比如暂停时间之类的指标也会纳入考虑。
此时会有一次 stop the world暂停,会计算出 Eden大小和 survivor 大小,用于下次young GC。统计信息会被保存下来,用于辅助计算size。比如暂停时间之类的指标也会纳入考虑。
这种做法使得调整各代区域的大小变得很容易,根据需求可以让他们变大一些或变小一些。
5、年轻代GC之后
现在存活的对象已经被转移或晋升到了survivor或old区了。
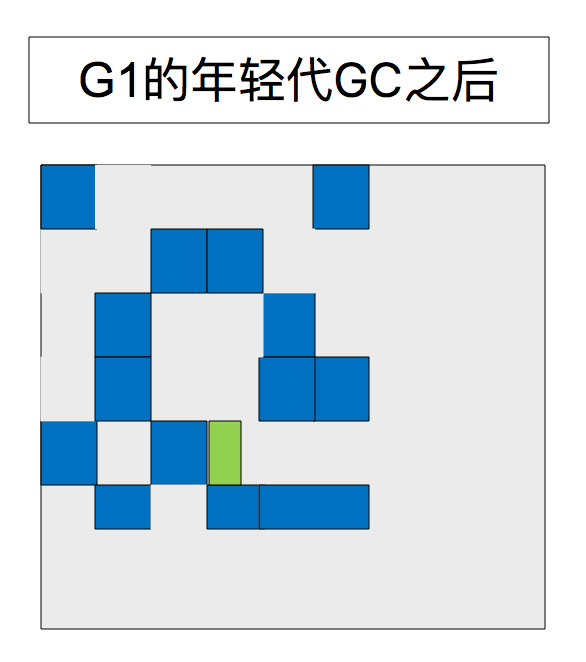
刚刚被晋升的对象用深蓝色表示。Survivor 用绿色表示。
总结起来,G1的年轻代收集归纳如下:
- 堆就是一整块内存空间,被分为多个heap区(regions)。
- 年轻代内存由一组不连续的heap块也就是region组成. 这使得在需要时很容易进行容量调整。
- 年轻代的垃圾收集,或者叫 young GCs, 会发生stop the world。 在回收时所有的应用程序线程都会被暂停。
- 年轻代 GC 通过多线程并行进行。
- 存活的对象被拷贝到新的 survivor 块或者老年代。
6、G1的老年代垃圾收集
就像CMS收集器一样,G1也是一个暂停少的收集器。下面这个流程图就描述了G1在老年代的各个收集阶段。

一步步了解老年代垃圾收集
结合上面的流程图,我们来看看在G1收集器中他们是如何和老生代互动的。
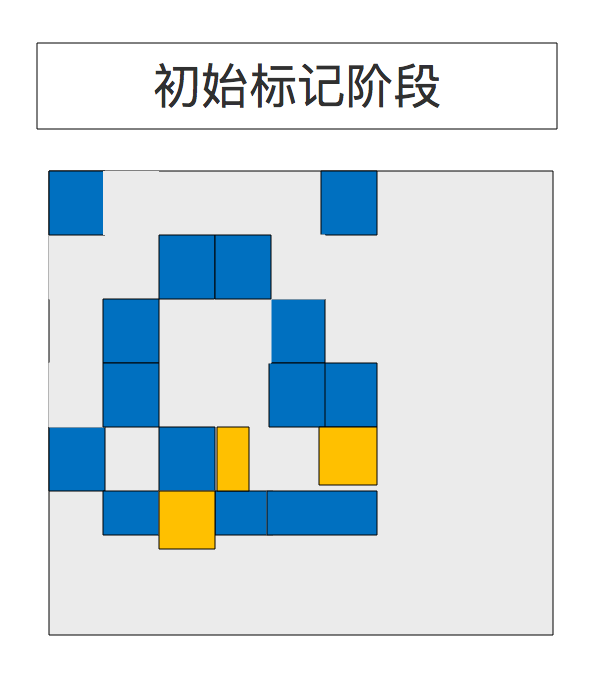
7、初始标记(Initial Marking)
存活对象的初始标记被固定放在年轻代垃圾收集阶段进行的,之所以把他列为第一个阶段,是因为只有进行初始标记了才有后续的阶段, 在日志中被记为 GC pause (young)(inital-mark)。
8、并发标记阶段(Concurrent Marking Phase)
如果发现有空的块(这里用红叉“X”标示的区域), 则会在 Remark 阶段立即移除。当然,”清单(accounting)”信息决定了活跃度的计算。
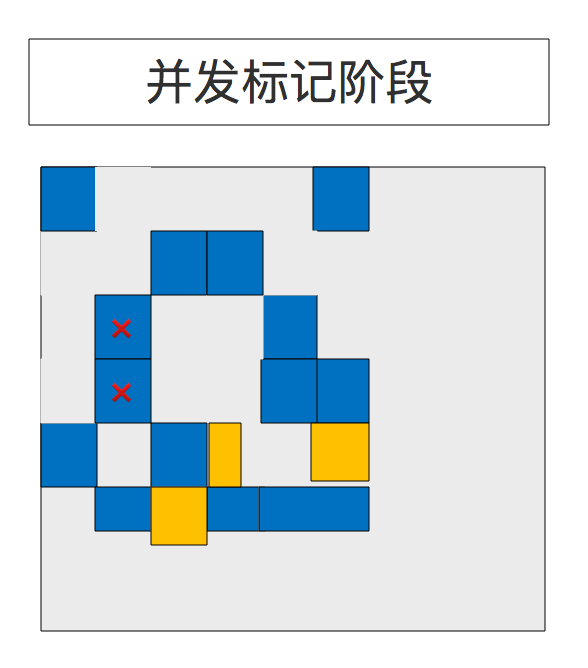
9、重新标记阶段(Remark Phase)
空的区域块被移除并回收。现在计算所有区域块的活跃度(Region liveness)。

10、复制清除阶段(Copying/Cleanup Phase)
G1选择“活跃度(liveness)”最低的区域块,这些区域可以最快的完成回收。然后这些区域和年轻代GC在同时被垃圾收集 。 日志上是被标识为 [GC pause (mixed)]。所以年轻代和老年代都在同一时间被垃圾收集。
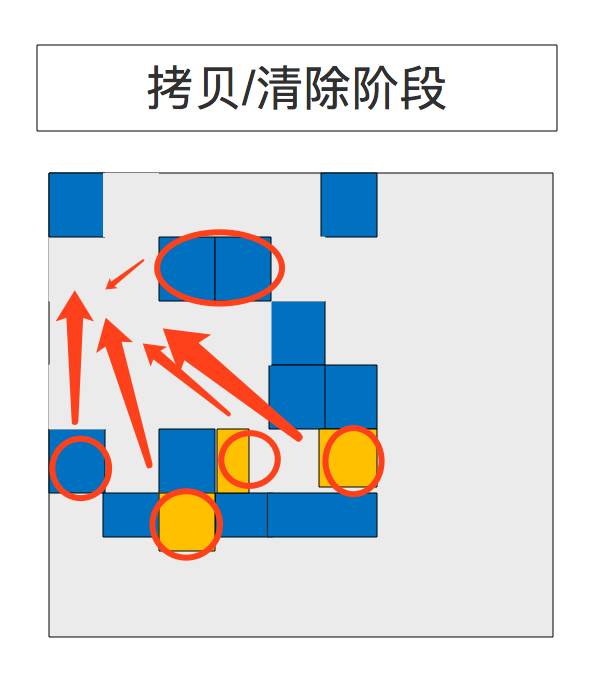
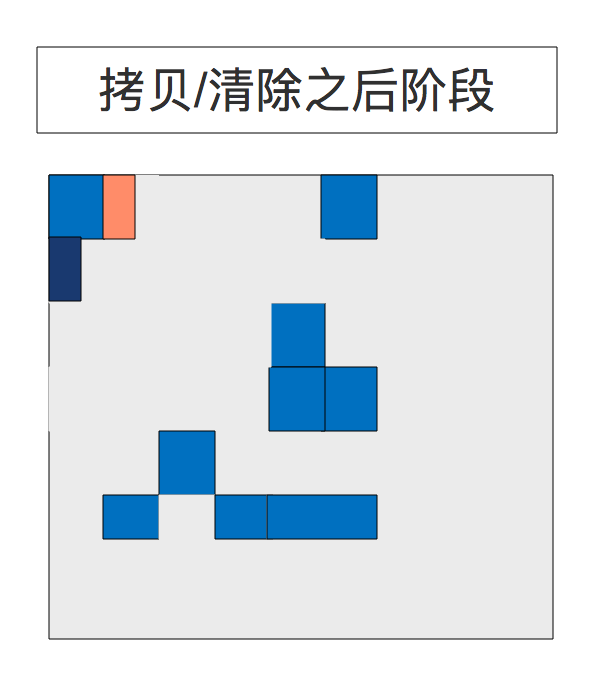
11、复制/清除之后阶段(After Copying/Cleanup Phase)
所选择的区域被收集和压缩到下图所示的深蓝色区域和深绿色区域。
12、 老生代GC总结
老生代的G1垃圾回收有以下几个关键点:
1、并发标记阶段(Concurrent Marking Phase)
- 活跃度信息在程序运行的时候就被并行的计算了出来。
- 活跃度(liveness)信息标记出哪些区域块最适合回收,在转移暂停期间最适合回收掉。
- 没有sweep阶段。但CMS是有这个阶段的。
2、重新标记阶段(Remark Phase)
- 使用了Snapshot-at-the-Beginning (SATB)算法,这个要比CMS的算法快很多。
- 完全空的区域块会被直接回收掉。
3、复制/清除阶段(Copying/Cleanup Phase)
- 年轻代和老年代会被同时回收。
- 老年代的区域块会不会被选择,取决于它的活跃度。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

