Flink 的神奇分流器:sideoutput
今天浪尖给大家讲讲 flink 的一个神奇功能, sideouptut 侧输出。
为了说明侧输出 (sideouptut) 的作用,浪尖举个例子,比如现在有一篇文章吧,单词长度不一,但是我们想对单词长度小于 5 的单词进行 wordcount 操作,同时又想记录下来哪些单词的长度大于了 5 ,那么我们该如何做呢?
比如, Datastream 是单词流,那么一般做法 ( 只写了代码模版 ) 是
datastream.filter(word.length>=5); // 获取不统计的单词,也即是单词长度大于等于 5 。
datastream.filter(word.length <5);// 获取需要进行 wordcount 的单词。
这样数据,然后每次筛选都要保留整个流,然后遍历整个流,显然很浪费性能,假如能够在一个流了多次输出就好了, flink 的侧输出提供了这个功能,侧输出的输出 (sideoutput) 类型可以与主流不同,可以有多个侧输出 (sideoutput) ,每个侧输出不同的类型。
下面浪尖就来具体讲一下如何使用侧输出。
1. 定义 OutputTag
在使用侧输出的时候需要先定义一个 OutputTag 。定义方式,如下:
OutputTag<String> outputTag = newOutputTag<String>("side-output") {};
OutputTag 有两个构造函数,上面例子构造函数只有一个 id 参数,还有一个构造函数包括两个参数, id , TypeInformation 信息。
OutputTag(String id) OutputTag(String id, TypeInformation<T>typeInfo)
2. 使用特定的函数
要使用侧输出,在处理数据的时候除了要定义相应类型的 OutputTag 外,还要使用特定的函数,主要是有四个:
ProcessFunction
CoProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
本文主要是以 ProcessFunction 为例讲解如何使用 flink 的侧输出 (sideoutput) 功能,具体这几个函数的深入含义及应用,后面再出文章分析。
上述函数中暴漏了 Context 参数给用户,让用户可以将数据通过 outputtag 发给侧输出流。
3. 案例
准备数据
/**
* Provides the default data sets used for the WordCount example program.
* The default data sets are used, if no parameters are given to the program.
*
*/
public class WordCountData {
public static final String[] WORDS = new String[] {
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,",
"And by opposing end them?--To die,--to sleep,--",
"No more; and by a sleep to say we end",
"The heartache, and the thousand natural shocks",
"That flesh is heir to,--'tis a consummation",
"Devoutly to be wish'd. To die,--to sleep;--",
"To sleep! perchance to dream:--ay, there's the rub;",
"For in that sleep of death what dreams may come,",
"When we have shuffled off this mortal coil,",
"Must give us pause: there's the respect",
"That makes calamity of so long life;",
"For who would bear the whips and scorns of time,",
"The oppressor's wrong, the proud man's contumely,",
"The pangs of despis'd love, the law's delay,",
"The insolence of office, and the spurns",
"That patient merit of the unworthy takes,",
"When he himself might his quietus make",
"With a bare bodkin? who would these fardels bear,",
"To grunt and sweat under a weary life,",
"But that the dread of something after death,--",
"The undiscover'd country, from whose bourn",
"No traveller returns,--puzzles the will,",
"And makes us rather bear those ills we have",
"Than fly to others that we know not of?",
"Thus conscience does make cowards of us all;",
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."
};
}
定义 OutputTag 对象:
private static final OutputTag<String> rejectedWordsTag = new OutputTag<String>("rejected") {};
定义 ProcessFunction 函数:
/**
* 以用户自定义FlatMapFunction函数的形式来实现分词器功能,该分词器会将分词封装为(word,1),
* 同时不接受单词长度大于5的,也即是侧输出都是单词长度大于5的单词。
*/
public static final class Tokenizer extends ProcessFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
@Override
public void processElement(
String value,
Context ctx,
Collector<Tuple2<String, Integer>> out) throws Exception {
// normalize and split the line
String[] tokens = value.toLowerCase().split("//W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 5) {
ctx.output(rejectedWordsTag, token);
} else if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
初始化 flink ,并使用侧输出:
public static void main(String[] args) throws Exception {
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// 获取输入数据
DataStream<String> text = env.fromElements(WordCountData.WORDS);
SingleOutputStreamOperator<Tuple2<String, Integer>> tokenized = text
.keyBy(new KeySelector<String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer getKey(String value) throws Exception {
return 0;
}
})
.process(new Tokenizer());
// 获取侧输出
DataStream<String> rejectedWords = tokenized
.getSideOutput(rejectedWordsTag)
.map(new MapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public String map(String value) throws Exception {
return "rejected: " + value;
}
});
DataStream<Tuple2<String, Integer>> counts = tokenized
.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(1);
// wordcount结果输出
counts.print();
// 侧输出结果输出
rejectedWords.print();
// execute program
env.execute("Streaming WordCount SideOutput");
}
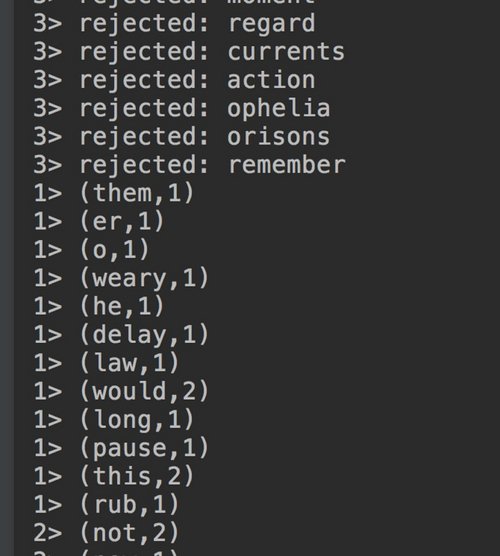
直接本地运行,查看结果:
推荐阅读:
调试flink源码
Flink异步IO第一讲
结合Spark讲一下Flink的runtime
干货|kafka流量监控的原理及实现

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

