服务发现-注册中心概述
概述
服务注册与发现是微服务的核心,否则新发布一个服务只能去调用方配置地址,不能接受的事。不管是rpc还是spring cloud这种Http调用,注册中心都不可少。
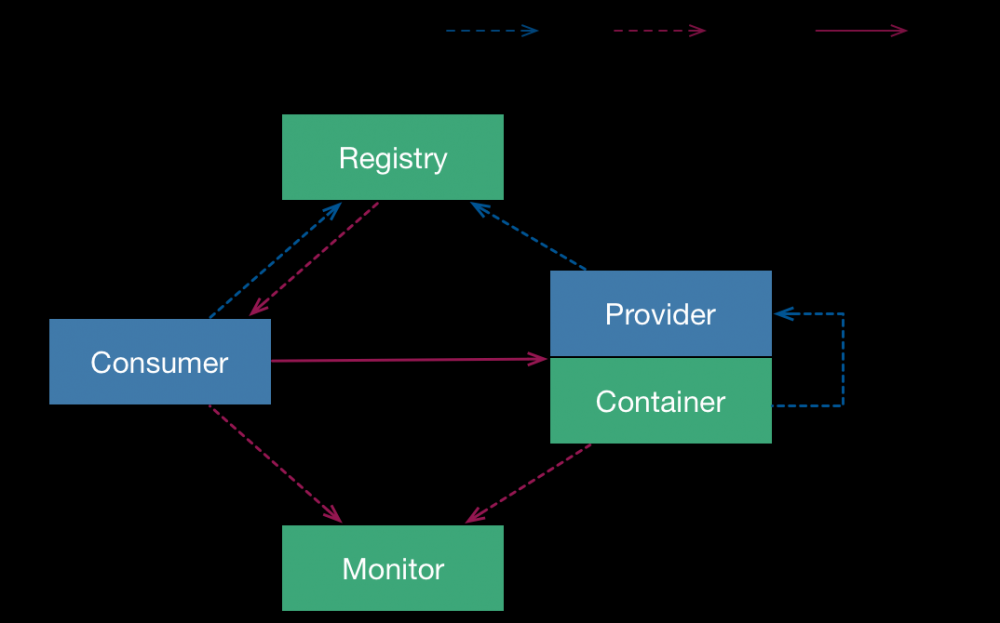

这是dubbo的基本结构,但几乎所有服务发现的注册中心都这样。服务提供方注册到注册中心,消费方订阅或者拉取提供者信息,发起调用。
客户端设计
客户端比较简单:
1. 从注册中心拉取服务信息
2. 维持服务信息缓存
3. 负载均衡和路由
不过说简单也不简单,根据注册中心使用的技术不同,实现方式不同。比如使用zk,consule等中间件自带通知功能,集成中间件客户端,做好订阅即可。eureka采用定时Http拉取的方式,可以自己开发多语言客户端,按照注册中心提供的接口实现。
不过,只是拉取(poll)并不是很好,频率低无法及时获取服务更新信息,频率太高增加注册中心的负载,而且大部分拉取都是没变化的。一直保持长连接接收推送也不是很好的方案,可以考虑长轮询的方式(实现参考nacos配置监听代码 LongPollingService )。
 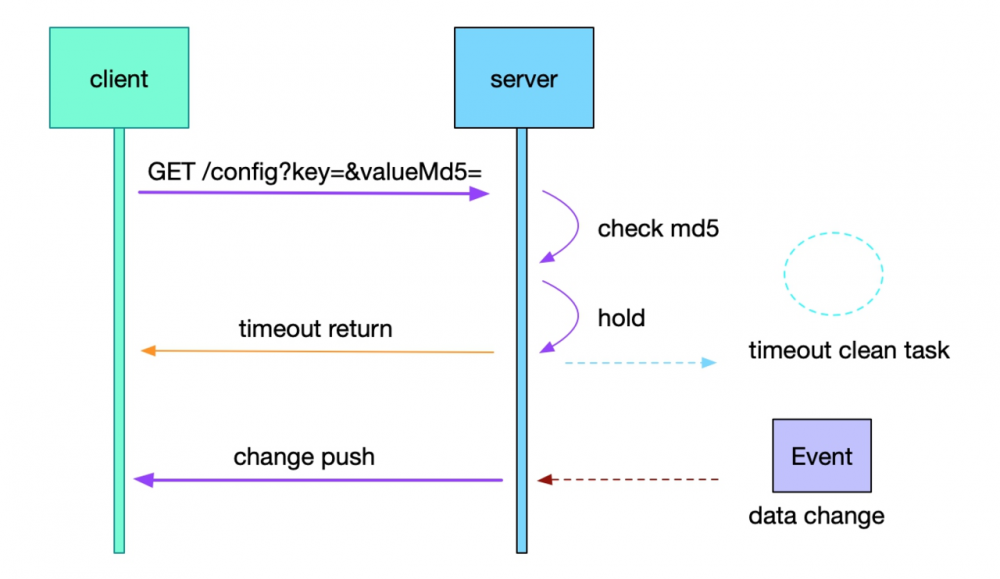
long polling
另外,nacos服务发现部分的通知方式又作了升级,不再hold客户端请求,而是通过udp通知。和long polling类似,客户端每10s查询一次,不再hold,保存客户端信息后直接返回。在下一个10秒来临前,如果instance有变更,直接从缓存捞取所有相关客户端,发送udp通知。但需要客户端开启一个udp端口并且能被访问。
负载均衡一般有一致性hash、轮询、加权轮询等,比较成熟,暂且不表。路由比较重要,灵活的路由能实现分流、降级、灰度发布、金丝雀发布、容灾等能力,路由信息配置应该有个管理后台,动态修改并实时生效。有如下路由规则:
- ip: 指定ip路由,方便有时候测试和定位问题。
- 地域(Region)、区域(Zone): 多区域部署实现容灾,同时优先Zone内调用降低网络延迟。
- 服务分组:有可能需要部署多组服务分别不同消费方使用。
- 服务版本:版本化,支持灰度。
- 其他可选:故障注入、熔断、流量镜像等。
有的服务发现通过注册中心的proxy代理实现负责均衡和路由,这种中心化的设计并不好,对proxy的性能要求极高,从而成为瓶颈点,一般都从客户端直接调用服务提供方。
有的服务发现为了实现多语言,在客户端部署了一个agent,通过agent跟注册中心通讯,对客户端调用透明,但是增加了部署复杂度。比如通过边车模式实现的 Netflix Prana 。不过service mesh的到来反而做到解耦业务和网络配置,方便升级、支持多语言等,在k8s生态下部署也不是问题。
服务提供者设计
服务端:
1. 注册
2. 续租(心跳、定时上报)
3. 下线
启动完成后,调用注册中心注册服务信息,然后定时上报,除了告知自己还活着外,还可以上报健康状态。因为活着不代表健康,比如某个中间件连不上等,spring boot可以检查 /health 。
注意,注册是服务正常启动完成后才开始,如果无法做到启动成功才上报,可以延时注册,否则客户端发起调用时,服务提供方其实还没准备好。
好的方式有个服务状态机:UP,DOWN,STRATING等,启动时注册服务时,status为STARTING,后续的心跳更新为UP。Eureka就是这样的方式。
容易出现的问题是服务下线时,注册中心没有及时下线,导致请求还是被路由到已经关闭(或者关闭中)的提供者,一般客户端会写一个shutdown hook通知注册中心下线。不过客户端可能直接被kill,或者消费者本地缓存没更新,仍然存在问题。以其纠结半天,不如弯道解决问题,通过应用启停脚本,先主动下线,隔几秒再stop提供者。
注册中心
市面上开源的可以用作注册中心的中间件主要是zk,console,etcd等。double用的zk、nacos,docker swarm使用consul,老版本的kubernate dns使用etcd。
这些中间件不是为服务发现而生,大部分保证了CAP定律的一致性、分区容错性,但不能保证每次请求都可用。对服务注册发现来说,我们更希望是AP,可以容忍短暂不一致,但必须可用。具体可参考: Why not use Curator/Zookeeper as a service registry?
 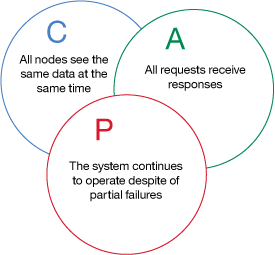
cap理论
总结,目前实现服务发现的注册中心有三种方式:
1. 使用中心化一致性存储中间件,如zk(Paxos算法),etcd(Raft算法);
2. 使用传统DNS+新的一致性算法,如SkyDNS、Spotify;
3. 去中心化,弱一致性实现如Eureka。
上文提到的nacos采用的是raft算法保证集群数据一致。下文主要介绍Eureka,注册信息维护在内存中,不需选主,集群间同步注册信息,可能有短暂的数据不一致,但保证可用性。
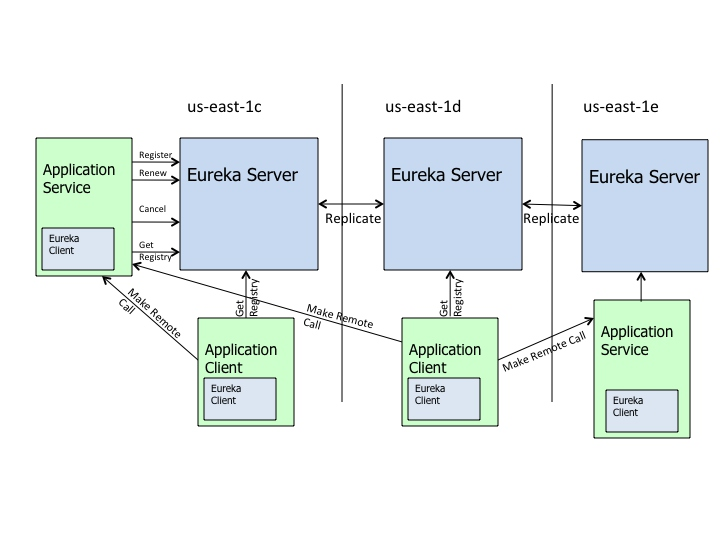
Eureka
Eureka高可用架构图:


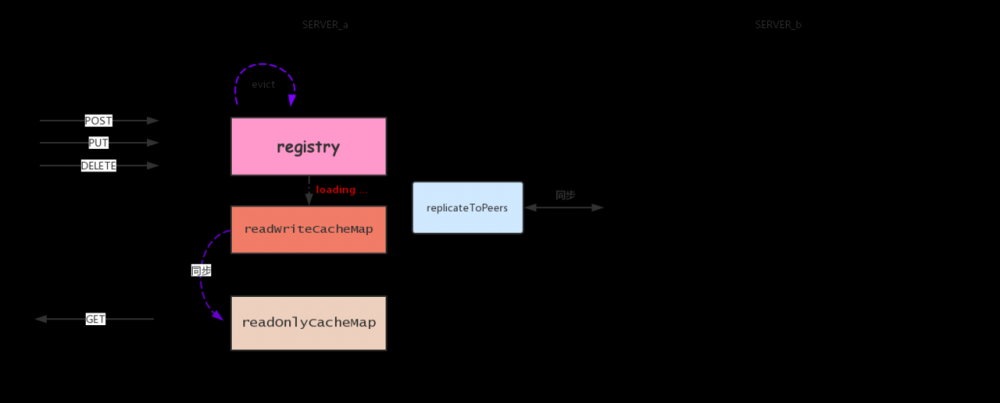
服务端注册什么?
eureka server主要通过一个嵌套ConcurrentHashMap维护注册信息:
ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry = new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>(); 复制代码
外层map的key为服务名(要求服务名唯一、好像没有实现namespace隔离),内层map的key为实例ID,用以区分相同服务的不同实例。Lease对象持有InstanceInfo,还有一些属性如 lastUpdatetime 。InstanceInfo类就是服务信息,比如ip,port,host等。下面是数据结构示例:
{
"name":"my-app-name",
"instance":[
{
"instanceId":"192.18.99.100:my-app-name:60000",
"hostName":"192.18.99.100",
"app":"my-app-name",
"ipAddr":"192.18.99.100",
"status":"UP",
"overriddenstatus":"UNKNOWN",
"port":{
"$":8080,
"@enabled":"true"
},
"securePort":{
"$":443,
"@enabled":"false"
},
"countryId":1,
"dataCenterInfo":{
"name":"MyOwn"
},
"leaseInfo":{
"renewalIntervalInSecs":30,
"durationInSecs":90,
"registrationTimestamp":1525342799736,
"lastRenewalTimestamp":1525364448834,
"evictionTimestamp":0,
"serviceUpTimestamp":1525242780899
},
"metadata":{
},
"homePageUrl":"http://192.18.99.100:8080/",
"statusPageUrl":"http://192.168.99.100:8080/info",
"isCoordinatingDiscoveryServer":"false",
"lastUpdatedTimestamp":"1525342799736",
"lastDirtyTimestamp":"1525342797179",
"actionType":"ADDED"
}
]
}
复制代码
服务如何下线?
不考虑数据同步间隔,一般移出不健康的服务用4种方式:
1. 停服务时,通过shutdown hook调用server,主动下线服务;
2. eureka server有一个定时任务检查一段时间没有心跳的服务,把它从列表剔除;
3. 服务健康检查不通过时,通过心跳上报给server,服务不被剔除,但被标记为down,客户端也不会访问。
4. 直接调用eureka api,把服务标为offline,同down类似。
eureka 集群如何同步?
eureka集群去中心化,客户端和不同的server通讯,eureka间同步有3个问题(eureka 特指eureka server):
1. 如图:如果某服务S,先向eurekaA注册,再向eurekaB注册,然后eurekaA向eurekaB同步。此时,同步信息会不会覆盖?
2. 服务S只向eurekaA注册,如果eurekaA向eurekaB同步失败,访问B的客户端是不是一直无法获取服务S的信息?
3. 服务多、eureka集群大时,eureka集群同步压力太大?

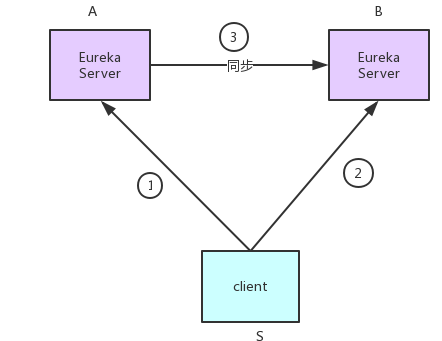
针对第一个问题,eureka通过时间戳和status判断新旧,始终以新版本为主;
第二个问题通过心跳解决,如果A->B失败,心跳再次达到A,还是会向B发送心跳,往B心跳结果404,则A重新把S注册到B。
第三个问题确实是个瓶颈,不过eureka通过“启动一次拉取,之后走批量、增量同步”的方式改善性能。
总结同步流程如下:
1. server启动时去其他server全量拉去
2. 启动后,其他客户端会自动增量同步(走批量接口)
3. 如果同步失败,通过心跳实现补偿逻辑。
eureka还做了哪些性能改善点?
eureka本身有点像一个缓存架构的设计,当然,其中为了改善性能也使用了缓存如guava cache,还有overriddenInstanceStatusMap,recentlyChangedQueue等队列。部分采用异步编程,gzip压缩等。
eureka的问题有哪些?
- 本身没有灰度功能(可以添加metadata信息自由扩展,然后在客户端扩展路由规则)
- 服务粒度太粗,客户端并不需要的信息也拉取,如果有上千个服务,难道客户端还维护那么多实例信息?
- 各个时间配置不好衡量(心跳时间,服务拉取时间等),需要改三四个配置以适应自己的服务。
- 没有权限控制;如果我起了一个服务,跟其他服务同名,且不是把浏览偷偷分过来了。
- 服务提供方也没有权限控制,可以任意调用server注册的服务。
- 控制台功能简陋,只有简单的查看注册列表的功能。
总之,如果要使用eureka,需要针对以上问题扩展很多细节。之所以单独研究它,也因为它问题多多,再看其他框架设计时更能理解相比Eureka的优缺点。
Gossip
如果想了解dns加持的方式,kubernate是一个很好的研究示例,通过一个dns服务还有iptables的方式实现服务发现和路由。这里再介绍一个新玩法Serf。
Eureka是去中心化,弱一致性,但还是有一个AP系统的注册中心集群。Serf的玩法是,完全去中心,不再需要一个注册中心,所有服务组成一个大集群,大概如下:
每个服务都是网络中的一个节点,每个节点都随机与其他节点通讯,最终达成一致,使得每一个节点都可能知道网络中的其他节点。Serf就是gossip算法的实现。看到这种分布式网络中通讯的容错问题,马上想到区块链,P2P。
Serf并不能解决服务发现所有需求,虽然解决了大集群网络中的容错性,但在几千个服务节点中,节点信息传播效率我没作测试。不过这是一个新的玩法,且gossip协议在集群信息同步上用得越来越多,比如consul不同数据中心的同步,Cassandra集群信息的同步都是通过gossip实现。
Apache还有一个正在孵化的项目incubator-gossip。
总结
本文通过研究一些开源服务注册发现框架,总结其设计要点。
[1]. Netflix github
[2].serf
[3]. service-discovery-in-the-cloud
[4].Gossip_protocol
[5].nacos
正文到此结束
- 本文标签: apache git map 代码 key src IO 一致性 HashMap zip iptables zookeeper GitHub Docker Uber cache 高可用 consul update ip 集群 API 实例 同步 Service 分布式 服务注册 部署 spring 压力 管理 Cassandra dubbo Action Spring Boot 注册中心 微服务 端口 tar 数据 App 开源 queue id Netflix Agent tab 负载均衡 UI UDP 总结 ACE 服务端 Spring cloud 缓存 测试 DNS Region 时间 开发 http 希望 权限控制 Proxy 协议 https 配置 需求 Eureka ECS 长连接 灰度发布 ConcurrentHashMap
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

