你不得不掌握的 JVM 内存管理
Java 引以为豪的就是它的自动内存管理机制。相比于 C++的手动内存管理、复杂难以理解的指针等,Java 程序写起来就方便的多。
然而这种呼之即来挥之即去的内存申请和释放方式,自然也有它的代价。为了管理这些快速的内存申请释放操作,就必须引入一个池子来延迟这些内存区域的回收操作。
我们常说的内存回收,就是针对这个池子的操作。我们把上面说的这个池子,叫作堆,可以暂时把它看成一个整体。
JVM 内存布局
Java 程序的数据结构是非常丰富的。其中的内容,举一些例子:
静态成员变
动态成员变量
区域变量
短小紧凑的对象声明
庞大复杂的内存申请
我们先看一下 JVM 的内存布局。随着 Java 的发展,内存布局一直在调整之中。比如,Java 8 及之后的版本,彻底移除了持久代,而使用 Metaspace 来进行替代。这也表示着 -XX:PermSize 和 -XX:MaxPermSize 等参数调优,已经没有了意义。但大体上,比较重要的内存区域是固定的。
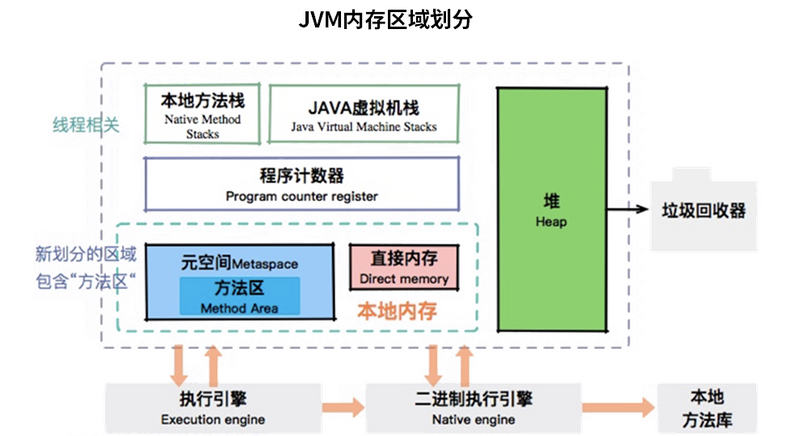
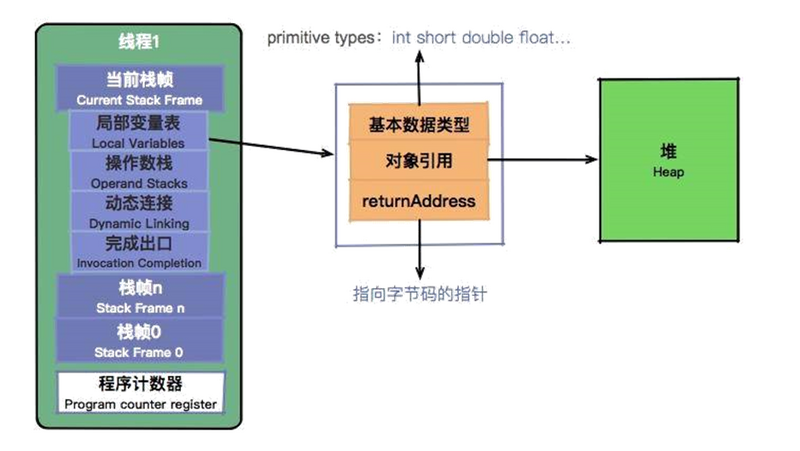
JVM 内存区域划分如图所示,从图中我们可以看出:
- JVM 堆中的数据是共享的,是占用内存最大的一块区域。
- 可以执行字节码的模块叫作执行引擎。
- 执行引擎在线程切换时怎么恢复?依靠的就是程序计数器。
- JVM 的内存划分与多线程是息息相关的。像我们程序中运行时用到的栈,以及本地方法栈,它们的维度都是线程。
- 本地内存包含元数据区和一些直接内存。
虚拟机栈
Java 虚拟机栈是基于线程的。哪怕你只有一个 main() 方法,也是以线程的方式运行的。在线程的生命周期中,参与计算的数据会频繁地入栈和出栈,栈的生命周期是和线程一样的。
栈里的每条数据,就是栈帧。在每个 Java 方法被调用的时候,都会创建一个栈帧,并入栈。一旦完成相应的调用,则出栈。所有的栈帧都出栈后,线程也就结束了。每个栈帧,都包含四个区域:
- 局部变量表
- 操作数栈
- 动态连接
- 返回地址
我们的应用程序,就是在不断操作这些内存空间中完成的。
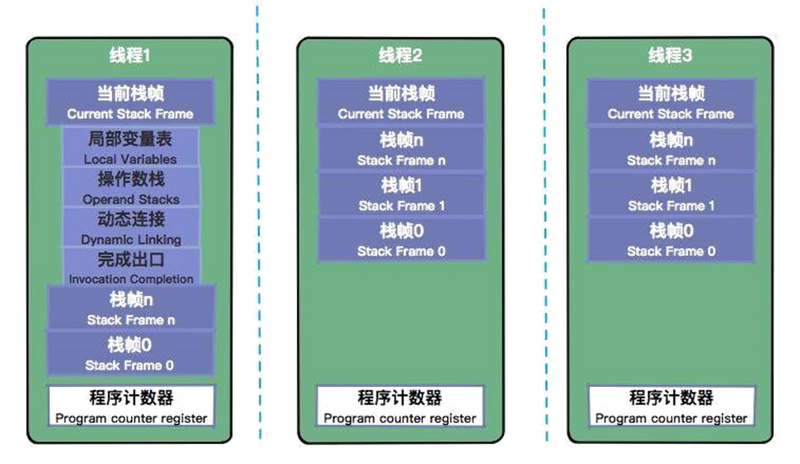
本地方法栈是和虚拟机栈非常相似的一个区域,它服务的对象是 native 方法。你甚至可以认为虚拟机栈和本地方法栈是同一个区域,这并不影响我们对 JVM 的了解。
这里有一个比较特殊的数据类型叫作 returnAdress。因为这种类型只存在于字节码层面,所以我们平常打交道的比较少。对于 JVM 来说,程序就是存储在方法区的字节码指令,而 returnAddress 类型的值就是指向特定指令内存地址的指针。
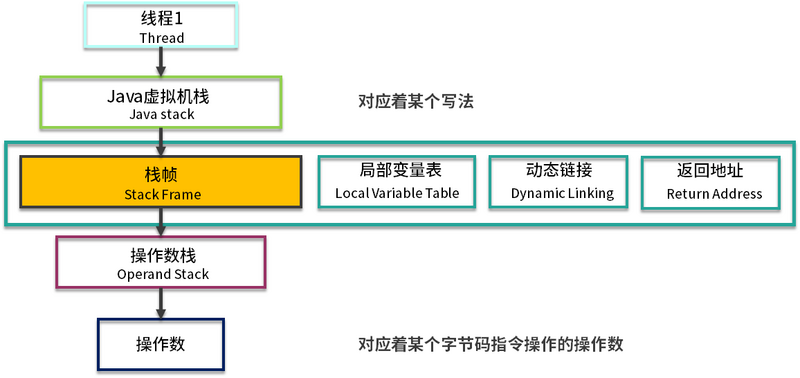
- 这里有一个两层的栈。第一层是栈帧,对应着方法;第二层是方法的执行,对应着操作数。注意千万不要搞混了。
- 你可以看到,所有的字节码指令,其实都会抽象成对栈的入栈出栈操作。执行引擎只需要傻瓜式的按顺序执行,就可以保证它的正确性。
程序计数器
既然是线程,就代表它在获取 CPU 时间片上,是不可预知的,需要有一个地方,对线程正在运行的点位进行缓冲记录,以便在获取 CPU 时间片时能够快速恢复。
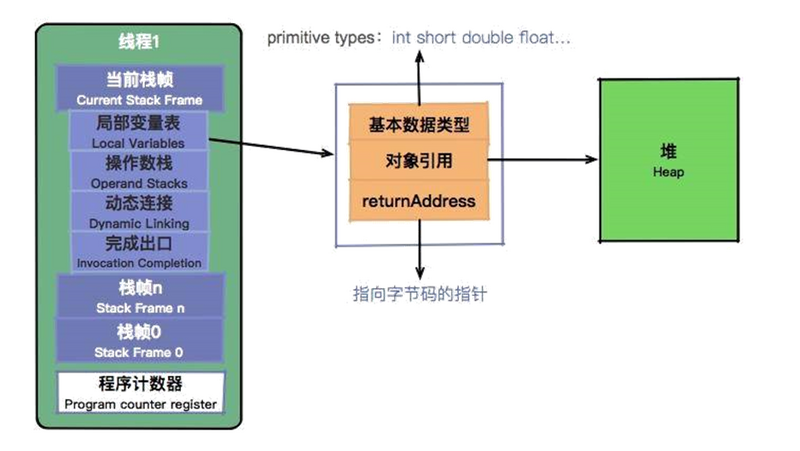
程序计数器是一块较小的内存空间,它的作用可以看作是当前线程所执行的字节码的行号指示器。这里面存的,就是当前线程执行的进度。下面这张图,能够加深大家对这个过程的理解。
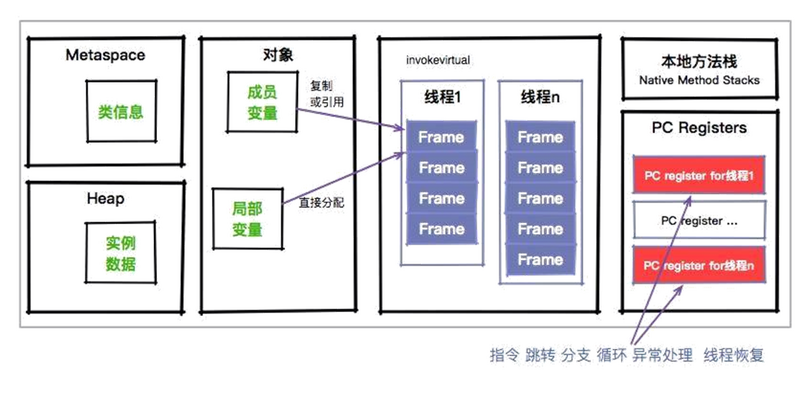
可以看到,程序计数器也是因为线程而产生的,与虚拟机栈配合完成计算操作。程序计数器还存储了当前正在运行的流程,包括正在执行的指令、跳转、分支、循环、异常处理等。
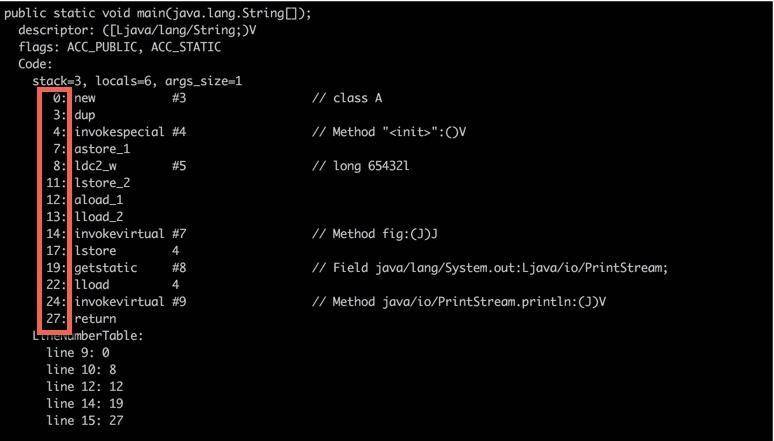
我们可以看一下程序计数器里面的具体内容。下面这张图,就是使用 javap 命令输出的字节码。大家可以看到在每个 opcode 前面,都有一个序号。就是图中红框中的偏移地址,你可以认为它们是程序计数器的内容。
堆
堆是 JVM 上最大的内存区域,我们申请的几乎所有的对象,都是在这里存储的。我们常说的垃圾回收,操作的对象就是堆。
堆空间一般是程序启动时,就申请了,但是并不一定会全部使用。
随着对象的频繁创建,堆空间占用的越来越多,就需要不定期的对不再使用的对象进行回收。这个在 Java 中,就叫作 GC(Garbage Collection)。
由于对象的大小不一,在长时间运行后,堆空间会被许多细小的碎片占满,造成空间浪费。所以,仅仅销毁对象是不够的,还需要堆空间整理。这个过程非常的复杂。
那一个对象创建的时候,到底是在堆上分配,还是在栈上分配呢?这和两个方面有关:对象的类型和在 Java 类中存在的位置。
Java 的对象可以分为基本数据类型和普通对象。
对于普通对象来说,JVM 会首先在堆上创建对象,然后在其他地方使用的其实是它的引用。比如,把这个引用保存在虚拟机栈的局部变量表中。
对于基本数据类型来说(byte、short、int、long、float、double、char),有两种情况。
我们上面提到,每个线程拥有一个虚拟机栈。当你在方法体内声明了基本数据类型的对象,它就会在栈上直接分配。其他情况,都是在堆上分配。
注意,像 int[] 数组这样的内容,是在堆上分配的。数组并不是基本数据类型。
这就是 JVM 的基本的内存分配策略。而堆是所有线程共享的,如果是多个线程访问,会涉及数据同步问题。
元空间
关于元空间,我们还是以一个非常高频的面试题开始:“为什么有 Metaspace 区域?它有什么问题?”
说到这里,你应该回想一下类与对象的区别。对象是一个活生生的个体,可以参与到程序的运行中;类更像是一个模版,定义了一系列属性和操作。那么你可以设想一下。我们前面生成的 A.class,是放在 JVM 的哪个区域的?
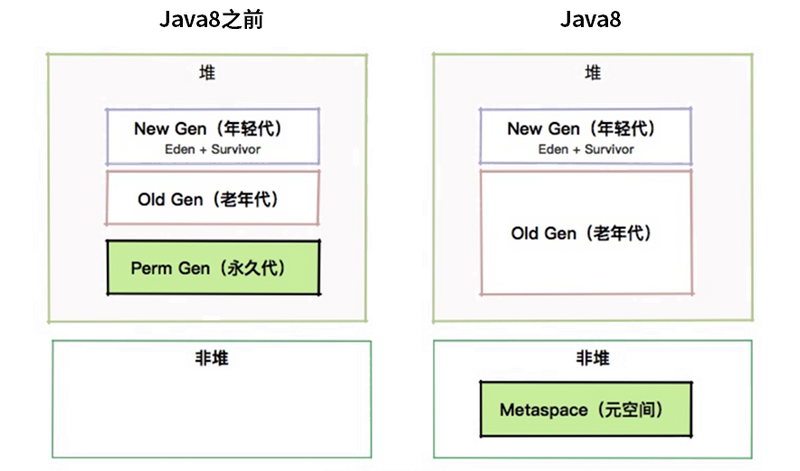
想要问答这个问题,就不得不提下 Java 的历史。在 Java 8 之前,这些类的信息是放在一个叫 Perm 区的内存里面的。更早版本,甚至 String.intern 相关的运行时常量池也放在这里。这个区域有大小限制,很容易造成 JVM 内存溢出,从而造成 JVM 崩溃。
Perm 区在 Java 8 中已经被彻底废除,取而代之的是 Metaspace。原来的 Perm 区是在堆上的,现在的元空间是在非堆上的,这是背景。关于它们的对比,可以看下这张图。
然后,元空间的好处也是它的坏处。使用非堆可以使用操作系统的内存,JVM 不会再出现方法区的内存溢出;但是,无限制的使用会造成操作系统的死亡。所以,一般也会使用参数 -XX:MaxMetaspaceSize 来控制大小。
方法区,作为一个概念,依然存在。它的物理存储的容器,就是 Metaspace。现在,只需要了解到,这个区域存储的内容,包括:类的信息、常量池、方法数据、方法代码就可以了。
小结
- 我们常说的字符串常量,存放在哪呢?
由于常量池,在 Java 7 之后,放到了堆中,我们创建的字符串,将会在堆上分配。
- 堆、非堆、本地内存,有什么关系?
关于它们的关系,我们可以看一张图。在我的感觉里,堆是软绵绵的,松散而有弹性;而非堆是冰冷生硬的,内存非常紧凑。
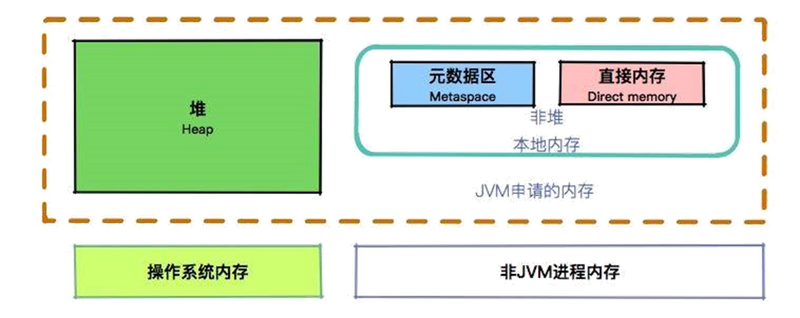
大家都知道,JVM 在运行时,会从操作系统申请大块的堆内内存,进行数据的存储。但是,堆外内存也就是申请后操作系统剩余的内存,也会有部分受到 JVM 的控制。比较典型的就是一些 native 关键词修饰的方法,以及对内存的申请和处理。
在 Linux 机器上,使用 top 或者 ps 命令,在大多数情况下,能够看到 RSS 段(实际的内存占用),是大于给 JVM 分配的堆内存的。
如果你申请了一台系统内存为 2GB 的主机,可能 JVM 能用的就只有 1GB,这便是一个限制。
总结
JVM 的运行时区域是栈,而存储区域是堆。很多变量,其实在编译期就已经固定了。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

