使用 Bluemix 和 Cloudant 构建一个企业级的 SEC 财务数据数据库
NoSQL 数据库现在风靡一时,它这样广受欢迎是有充分理由的。互联网上有大量的非结构化或半结构化数据可供使用。虽然将这种数据加载到传统 RDBMS 比较繁琐和困难,但 NoSQL 数据库能够以几乎任何形式动态加载内容,这使得访问这种非结构化或半结构化数据变得更容易。
在本教程中,我们对美国证券交易委员会使用的数据集类型很感兴趣。证券交易委员会(Securities and Exchange Commission,SEC)报告(根据美国上市公司法规方面的要求)包含资产负债表、现金流量表和其他相关的财务信息。最初,在 1929 年股市崩盘后,市场增加了透明度,防止出现另一次大萧条,因此,这些报告包含一些可以免费获得的数据。以下是 IBM 声明的收入报告的一部分,可以将此作为一个示例:

最初,SEC 报告是以纸张形式提交的,后来是电子格式形式提交的。最后,从 2005 年开始,美国证券交易委员开始以机器可读取的结构化格式(被称为可扩展商业报告语言,XBRL)提交此数据。XBRL 是一种 XML 文档,详细解释这种格式已远远超出了本教程的讨论范围。然而,前面的示例中的 “服务” 数量在 XBRL 中如下所示:
<us-gaap:SalesRevenueServicesNet id="ID_1119" contextRef="FROM_Jul01_2014_TO_Sep30_2014_Entity_0000051143" unitRef="USD" decimals="-6">13869000000</us-gaap:SalesRevenueServicesNet>
“ 在本教程中,您将学习如何从头开始或通过复制来建立您自己的数据库,并部署自己的 xbrl.mybluemix.net 版本。 ”
每个季度或每年的报告都会提交到美国证券交易委员会,其中包括一个随附的 XBRL 文件,该文件提供了相同的数据作为人类可读报告。美国证券交易委员会提供了这些文件的一个清单,任何人都可以免费下载这些文件。虽然数据是以结构化形式提供的,但它不容易查询或枚举,因为它由成千上万个不同的 XML 文件组成。
本教程中讨论的应用程序 xbrl.mybluemix.net 提供了一个简单的接口来查询这个数据集,并以一种容易理解的方式显示它。
作为一个示例,参见下图。在寻找某个公司和金融概念(以 “AssetsCurrent” 为例)后,数据是以曲线图的形式展示的。个别点有一个可以 “固定” 的悬停的弹出式菜单,用来提供在美国证券交易委员会网站上提交数据的导航,您可以从该网站上获得数据。
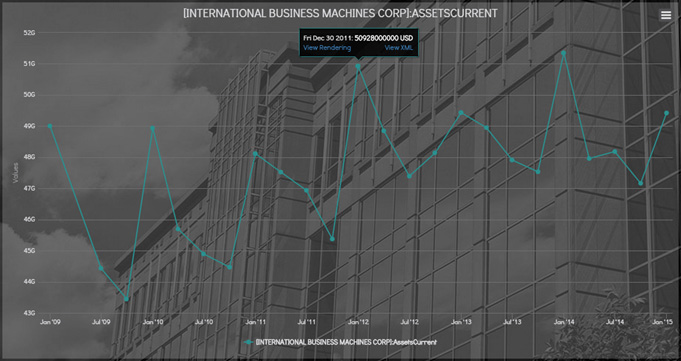
点击查看大图
关闭 [x]
运行应用程序
获取代码
构建您的应用程序需要做的准备工作
- 一个 Bluemix 帐户和一个 DevOps Services 帐户,两个帐户都被链接到您的 IBM ID
- 对于本地部署: Node.js 运行时,这一项是可选的
步骤 1. 构建一个数据库
由三个选项可用来向您的应用程序提供数据。按照困难程度进行降序排序,这三个选项是:
- 从头构建一个新的数据库。
- 将现有数据库复制到您自己的 Cloudant 帐户。
- 使用现有数据库。
选项 c 意味着什么都不做,所以我们将重点介绍选项 a 和选项 b。如果您想使用现有的数据库,那么可以跳到步骤 2. 在 DevOps Services 上创建一个新项目。
选项 1: 从头构建一个新的数据库
- 登录到 Bluemix 并将 Cloudant NoSQL DB 服务添加到您的 Bluemix 空间中。
- 打开 Cloudant 仪表板。(参见附录,获得关于如何访问 Cloudant dashboard 的指导。)创建一个新的数据库。
- 如果尚未在本地安装 Node.js 运行时,请安装它。
- 从 XbrlBuilder 源代码存储库 中,将源代码树导出到一个存档文件中。
- 将该存档文件解压到一个本地目录中。
-
在 XbrlBuilder 文件夹中,通过输入
node app.js
启动应用程序
您需要指定以下环境变量:
- BASE_DIRECTORY:将在其中存储已下载的 XBRL 文件 (gzipped)。
-
CLOUDANT_DATABASE:您在步骤 2 中创建的 Cloudant 数据库。它应该如下所示:
https://<user>:<pass>@cloudant.com/<db>/
这些凭证可以在 Bluemix 仪表板中找到。请注意,如果没有 Bluemix 应用程序被绑定到 Cloudant 服务,那么您必须创建一个绑定来查看这两个凭证。
应用程序会在 XBRL 申请被接受的每个月进行迭代。它会首先将 XBRL 文件下载到 BASE_DIRECTORY,然后将它们上传到 CLOUDANT_DATABASE。如果出现故障,则会在下载时产生一个不可恢复的错误,只需重启应用程序即可。以前已下载的所有文件都将被忽略。
-
创建必要的视图。这些视图包括:
factsMainViews/EntityConceptName
映射:
function getValue(fqn) { return fqn.substring(fqn.lastIndexOf("/") + 1, fqn.length); } function(doc) { emit([doc['http://www.xbrl.org/2003/instance/Entity'], getValue(doc['http://www.xbrl.org/2003/instance/Concept'])], null); }Reduce:
_count
factsMainSearchIndexes/EntitySplitConcept
搜索索引功能:
function unCamelCase (str){ return str // insert a space between lower & upper .replace(/([a-z])([A-Z])/g, '$1 $2') // space before last upper in a sequence followed by lower .replace(//b([A-Z]+)([A-Z])([a-z])/, '$1 $2$3') // uppercase the first character .replace(/^./, function(str){ return str.toUpperCase(); }); } function getValue(fqn) { return fqn.substring(fqn.lastIndexOf("/") + 1, fqn.length); } function(doc){ index("entity", doc['http://www.xbrl.org/2003/instance/Entity'], {"store": true}); index("conceptNameSplit", unCamelCase(getValue(doc['http://www.xbrl.org/2003/instance/Concept'])), {"store": true, "facet":true}); }factsMainSearchIndexes/EntityCipherCompanyName
搜索索引功能:
function rotateText(text, rotation) { // Surrogate pair limit var bound = 0x10000; // Force the rotation an integer and within bounds, just to be safe rotation = parseInt(rotation) % bound; // Might as well return the text if there's no change if(rotation === 0) return text; // Create string from character codes return String.fromCharCode.apply(null, // Turn string to character codes text.split('').map(function(v) { // Return current character code + rotation return (v.charCodeAt() + rotation + bound) % bound; }) ); } function getValue(fqn) { return fqn.substring(fqn.lastIndexOf("/") + 1, fqn.length); } function(doc){ index("companyName", rotateText(doc['http://www.xbrl.org/2003/instance/Entity'], 325) + ' ' + doc['http://www.sec.gov/Archives/edgar/companyName'], {"store": true, "facet":true}); }
选项 2:复制一个新的 Cloudant 数据库
- 登录到 Bluemix,并将 Cloudant NoSQL DB 服务添加到您的 Bluemix 空间。
- 打开 Cloudant 仪表板。(参见附录,以获得如何访问该仪表板的指导。)
- 转到复制屏幕并执行以下操作:
- 选择 New Replication 。
- 在 SOURCE DATABASE > Remote Database 下,输入数据库 URL:
https://0741ae13-4f99-4ffb-8282-60d27e161c7f-bluemix.cloudant.com/facts - 在 TARGET DATABASE > New Database > Create a new database locally 下,为新数据库输入一个名称。它可以是任何您选择的名称。在本示例中,我使用的是 "facts"。
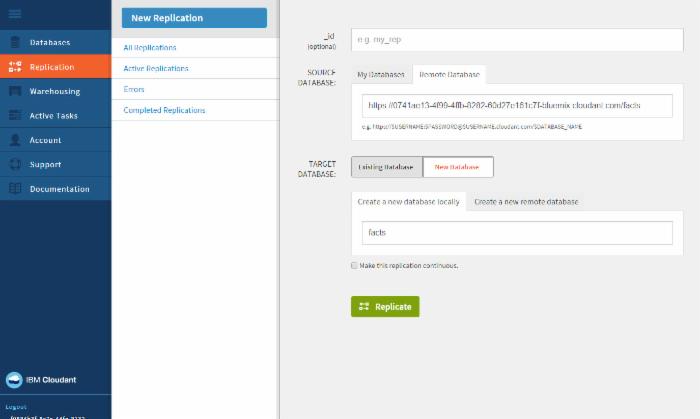
点击查看大图
关闭 [x]
- 单击 Replicate 。
备注:facts 数据库的大小超过了 100GB。这里还提供了一个更小的数据子集(大约 47MB),名为 facts_test 。使用这个子集来测试您的复制。您甚至可以使用 facts_test 来测试整个应用程序,尽管您需要在选项 1:从头创建一个新的数据库的最终步骤中创建视图。
步骤 2. 在 DevOps Services 上创建一个新项目
- 登录到 DevOps Services 。
- 浏览到 XbrlServer 源代码存储库 。
- 单击顶部菜单上的 FORK ,并按照指令创建一个新项目。
步骤 3. 将应用程序部署到 Bluemix
- 浏览到您在步骤 2中创建的 DevOps 项目。
- 在必要的时候修改代码,使其指向正确的数据库:
- 如果您创建了自己的数据库,请将它链接到您的应用程序,并将它命名为 "facts",那么这里已经没什么好做的了。Cloudant URL 来自应用程序环境变量。
- 如果您已经创建了自己的数据库,并将它命名为 "facts" 以外的其他名称,那么您必须修改 helpers.coffee 文件中的
cloudantFactsUri参数,以及 elements.coffee、companies.coffee 和 size.coffee 文件中的cloudantUri参数。 - 如果您使用现有数据库,则必须修改 helpers.coffee 文件中的
getCloudantUrl方法,以便返回https://0741ae13-4f99-4ffb-8282-60d27e161c7fbluemix.cloudant.com。
- 单击根文件夹,然后单击 Launch Configuration 运行栏中下拉按钮,并单击 CREATE NEW 。
- 按照指令完成部署过程。
部署过程可能会花费几分钟的时间。在完成部署时,会显示一条消息,或者您可以从 Bluemix 仪表板查看部署状态。
您只需执行一次部署。您可以单击 Launch Configuration 运行栏旁边的 PLAY 按钮,再次使用相同的设置进行部署。
代码亮点
XbrlBuilder
这里有一些来自 XbrlBuilder 源代码存储库的关键文件:
- app.coffee 是主要的入口点。
-
parseRss()采用了已提交文件的 RSS 提要,通过解析它们获得相关的 XBRL 文件,然后开始下载/解析这些文件。 -
parseInstance()采用了一个 XBRL 实例,将它们转换为一组 JSON 文档,以便将它们发送到 Cloudant bulk_posts 端点。
-
- streams/CloudantBulkPostStream.coffee 采用了一系列对象,将它们序列化为一个 JSON 数组,以便上传到 Cloudant。
- streams/FactTransformStream.coffee 采用了一系列来自 XBRL 文档的事实,并将它们转换成 JavaScript 对象。
- streams/InstancePerProcessorTransformStream.coffee 可以保存关于来自 RSS 提要的某个实例文档的信息,在该提要中,这些信息被发现用于 FactTransformStream.coffee 文件。
- streams/XmlTransformStream.coffee 一个流式 XML 解析器。
- model/xml/Selector.coffee 是一个类,用于选择 XML 中的一个元素,供 XmlTransformStream.coffee 使用(而不是一个基于字符串的选择器,比如 XLink)。
- model/xml/SelectorSet.coffee 是解析器将在 XML 元素上执行的一系列测试,以确定它们是否被选中。这些都是逻辑
OR运算。对于某个将被选中的元素,只有一个测试必须成功。
XbrlServer
以下是针对 xbrl.mybluemix.net 的一些关键文件:
- routes/helpers.coffee 包含许多供应用程序使用的 helper 函数:
-
getCloudantURL()返回 Cloudant 数据存储的 URL;默认情况下,它从 VCAP_SERVICES 中获取该 URL。可以更改此函数来进行本地开发,或者从这里没有定义的某个数据库中获取数据。 -
recursiveCloudantSearch()目前未被使用,请参阅来自 Cloudant 搜索索引的每个结果,获得关于如何使用它的信息。 -
getParsedFactData()返回将用来填充表的数据。 -
tickerResolver()允许用户搜索股票代码以及公司名称中的文本。
-
- routes/companies.coffee 被用来填充公司搜索组合框。
- routes/elements.coffee 被用来填充概念搜索组合框。
- routes/facts.coffee 返回用来填充表的数据。
- routes/save.coffee 将数据保存在 Cloudant 中,以便允许使用共享功能。它需要具有写访问权,因此,使用现有的事实数据库(具有只读访问权)在这里不是一个好的选择。
- model/Fact.coffee 允许更有效地使用来自 Cloudant 的 JSON 对象。
-
getValue()返回 URI 中最后一个 "/" 后面跟着的文本。 -
GetUnitDescription()返回事实单元的一个友好的字符串描述。 -
GetDimensions()返回一个由控制事实的 XBRL 维度的轴/成员对(axis/member pairs)组成的关联数组。 -
GetHashValue()返回一个字符串,该字符串应该惟一地标识一个事实,无论其价值如何。如果两个事实有相同的 HashValue,则必须确定哪一个更 “正确”,例如,日期更近一些。 -
GetPeriodDescription()返回事实的 XBRL 维度的一个友好的字符串描述。
-
- streams/FactTransformStream.coffee 采用了来自 Cloudant 的事实数据,并将它们转换成一种更适合加载到 Highcharts(xbrl.mybluemix.net 上使用的绘图工具)中的形式。
- public/scripts/index.coffee 包含 xbrl.mybluemix.net 使用的所有客户端 JavaScript 代码。
在使用 Cloudant 时吸取的经验教训
本节包含了一系列我在构建 xbrl.mybluemix.net 时吸取的经验教训。一些人可能觉得成为 Node.js 或 Cloudant 大师非常简单,但我对这两个主题没有任何的了解,所以我不得不努力学习。
最大可能地减少每个设计文档中的视图数量
这不是一个官方的 “最佳实践”,只是我使用 Cloudant 和大型数据集时养成的一个习惯。在处理 Cloudant 数据库时并没有这样的 “要求”。相反,您可以对数据库创建次级索引、搜索索引或 “视图”。所有这些函数都是用 JavaScript 编写,将对数据库中的每个文档执行,结果存储在一个 b-树中。这使得从大型数据集中获得结果变得快得多,因为所有可能的结果都已预先计算。不过,如果有大量的数据,或者索引函数非常复杂,那么创建索引可能非常慢。每一个视图都是设计文档的一部分,每个设计文档都可以包含任意数量的视图。正如您从 Cloudant 文档 中看到的那样:
在更新设计文档时,会重建视图索引。任何视图的更新都会导致文档中的所有视图的重建。
第二句是重点。在撰写本教程时,xbrl.mybluemix.net 的主要数据库中的文档数量不到 8000 万个。对这些数据而言,构建一个简单的次级指数通常需要大约 72 个小时。如果您有一个依赖于这样一个视图的应用程序,那么它会在此期间显示不太完整的数据,或者不显示任何数据。还有其他一些教程,它们介绍说,每个设计文档从概念上讲都代表一个 “应用程序”,而每个视图都是应用程序的一部分。这听起来貌似不错,但是,如果您有数百 GB 或 TB 的数据,那么这意味着,如果您想改变应用程序的一部分,或者只是添加一些东西,那么整个操作需要好几天的时间才能完成。即使只是开发,而不是创造产品,也仍然有点烦人。所以,无论是官方的 “最佳实践” 是什么,我的习惯是让每个设计文档中的视图尽可能的少,通常只有一两个。这种做法可能并不总是奏效,但是,如果我想更改应用程序的一部分而不动其他所有部分,这种做法真的很不错。
针对 Cloudant 搜索索引的 CamelCase 分词器
在通过 Cloudant 数据库创建一个搜索索引时,您会发现许多用来解析和令牌化全文数据的分析器。在构建 xbrl.mybluemix.net 时,我想搜索 CamelCase 字符串,比如 SalesRevenueNet。CamelCase 中没有内置的 Cloudant 分词器(tokenizer)。您可以为 CamelCase 构建您自己的 Lucene.Net 分词器,但该分词器在使用 Cloudant 时没用。幸运的是,可以将搜索索引作为一个 JavaScript 函数进行创建,这个灵活性允许您几乎以任何您想要的方式进行标记。只在创建索引时应用自己的分词器。
function unCamelCase (str){ return str // insert a space between lower and upper .replace(/([a-z])([A-Z])/g, '$1 $2') // space before last upper in a sequence followed by lower .replace(//b([A-Z]+)([A-Z])([a-z])/, '$1 $2$3') // uppercase the first character .replace(/^./, function(str){ return str.toUpperCase(); }); } function(doc){ index("name", unCamelCase(doc.name), {"store": true}); } 就是这么容易。您不需要在已经存在的字段上建立索引,您可以创建一个 “运行时“。通过用敏锐的目光进行观察,我意识到前面的示例没有考虑到数字,但是,如果这是一个问题,您可以将此作为一个练习。这要归功于 StackOverflow 线程 ,它提供 CamelCase 分词器的一个 JavaScript 示例。
来自 Cloudant 搜索索引的 “不同” 结果
搜索索引是 Cloudant 的一个很好的特性,甚至可以说它们至关重要。没有它们,很多人会考虑使用例程数据库任务,这会更复杂,但存在这种可能。让我们来查看 xbrl.mybluemix.net 上的一组简化的数据,IBM 过一段时间就会在该网站上报道一些金融信息:
{ "date": "03/31/2010", "company": "IBM", "concept":"Assets", "value": 100.00} { "date": "06/30/2010", "company": "IBM", "concept":"Assets", "value": 110.00} ...重复...
{ "date": "12/31/2014", "company": "IBM", "concept":"Assets", "value": 200.00} { "date": "03/31/2010", "company": "IBM", "concept":"Current Assets", "value": 50.00} ...继续
到目前为止,没有什么太复杂的东西。让我们在概念字段上创建一个搜索索引:
function(doc){ index("default", doc.company, {"store": true}); index("concept", doc.concept, {"store": true}); } 到目前为止,一切看起来都还不错。要填充 xbrl.mybluemix.net 的主页面上的第二个自动填写组合框,需要搜索一家公司提出的所有概念,这些概念中包含某个字符串。我们假设我们正在寻找 IBM 提供的所有包含文本 “资产” 的概念,仅搜索 10 个结果。查询 URI 看起来是这样的:
https://myaccount.cloudant.com/facts/_design/factsSearches/ _search/nameSearch?q="IBM"%20AND%20name:Assets&limit=10
结果的实际 JSON 并不重要,重要的是来自这个 URI 的响应,它应该包含以下结果:
{ "date": "03/31/2010", "company": "IBM", "concept":"Assets", "value": 100.00} { "date": "06/30/2010", "company": "IBM", "concept":"Assets", "value": 110.00} ... 重复 ...
{ "date": "06/32/2012", "company": "IBM", "concept":"Assets", "value": 150.00} “流动资产” 是不存在的!也不该存在。搜索索引完全按照要求它的方式在执行搜索。我们真正想要做的是查找与 “资产” 不同的概念。在 SQL 术语中,我们正在寻找:
SELECT DISTINCT concept FROM facts WHERE company='IBM' AND concept LIKE '%Assets%'
一个简单的解决方案是增加限制,将限定值增加到 100,然后,在填充组合框之前,简单地在客户端或服务器上处理列表,只保留不同的结果。该解决方案对我们的简单示例有效果,但是,假设 IBM 公布其资产 100 次或 1000 次呢?Cloudant 设置了最多 200 个结果的限定值。如果 IBM 报告 “资产” 1000 次(请注意,这是一个有点不自然的示例),那么我们就会变得不太走运。因为我们只需要单个字段(概念)的不同值的列表,我们可以使用计数。只需要重建索引,如下所示:
function(doc){ index("company", doc.company, {"store": true}); index("concept", doc.concept, {"store": true, "facet": true}); } 现在,查询 URI 看起来如下所示:
https://myaccount.cloudant.com/facts/_design/factsSearches/ _search/nameSearch?q="IBM"%20AND%20name:Assets&limit=0&counts=["name"]
我们使用了 limit=0 ,因为我们并不关心实际的文档,只关心不同值的列表, counts=["name"] 为我们提供了我们想要的东西。来自此查询的 JSON 结果类似于:
{"total_rows":17,"bookmark":"g2o","rows":[],"counts":{"name":{"Assets":16,"CurrentAssets":1})) 最后的关联数组正是我们正在寻找的数组,一个含有 “资产” 的名称字段的排列列表,以及每个排列出现了多少次。 警告 :在处理计数方面时,没有 " limit=x " 选项。因此,如果查询所有文档,查找包含 “e” 的概念,那么查询可能需要很长时间,而且会返回一个极长串的计数列表。
返回来自 “不同” Cloudant 搜索索引的多个字段
在前面的小节中,我们希望获得来自某个搜索索引的不同结果。我们做到了,但有一个缺点,我们无法返回多个字段。我的意思是说,我们不能创建如下所示的 SQL:
SELECT DISTINCT identifier, name FROM companies WHERE name LIKE '%International%'
我们只返回我们搜索到的字段。在创建索引时,我们可以直接连接两个或多个字段,但使用这种方法有一个严重的缺陷。我们将在所有连接字段创建索引,而不是在一个字段上创建索引并获得许多结果。
如果字段使用的是完全不同的字符空间,那么这不是问题。例如,一个只包含字母的字符和一个只包含数字的字符。即使不是这样,我们可以通过使用替换密码迫使它成为这样。JSON 文档并没有限定于 ASCII 字符。UTF-8 字符空间相当大,所以在创建索引时,我们可以只将一个或多个字段转移到完全不同的字符空间。
以下是搜索索引看起来的样子(参阅 Tim Severien 在 GitHub 上的密码示例 ,获得关于旋转函数的信息):
function rotateText(text, rotation) { // Surrogate pair limit var bound = 0x10000; // Force the rotation an integer and within bounds, just to be safe rotation = parseInt(rotation) % bound; // Might as well return the text if there's no change if(rotation === 0) return text; // Create string from character codes return String.fromCharCode.apply(null, // Turn string to character codes text.split('').map(function(v) { // Return current character code + rotation return (v.charCodeAt() + rotation + bound) % bound; }) ); } function(doc){ index("companyName", rotateText(doc.identifier, 500) + ' ' + doc.name, {"store": true, "facet":true}); } 我们正在包含使用了密码的标识符和原始名称的连接字符串上创建索引。这意味着 [ '0000051143′ , 'INTERNATIONAL BUSINESS MACHINES CORP' ] 对将变成为字符串 'ȤȤȤȤȤȩȥȥȨȧ INTERNATIONAL BUSINESS MACHINES CORP' 。
在这里,我们继续像以前一样,使用方面功能返回不同结果的列表。然后,简单地反转密码,再取回标识符(在这个示例中,是按 500 来旋转文本的)。您可以进行合理的假设:没有人会从使用了密码的字符空间将字符输入到您的搜索字段中,或者不允许搜索包含它们的结果。
来自 Cloudant 搜索索引的每个结果
正如之前我们所发现的那样,任何单个搜索索引调用只有有限的 200 个结果。假设不管出于什么原因,我们希望获得每一个结果。让我们来看一看我们对某个搜索索引 URI 执行调用时返回的实际 JSON:
{ "total_rows":980, "bookmark":"g1AAAAGneJzLYWBgYMtgTmGQT0lKzi9KdUhJMjTUy0zKNTCw1EvOyS9NScwr0ctLLckBKmRKZEiS ____f1YGk5uD0sugB0CxJAahPbYgA-TgBhjj1J-UANJRDzfifWwD2Ah28To0NxjhNCOPBUgyNAApoDHzIebMzYKYI_ bxDapTzAgYswBizH6IMV9OHwAbw6-cS6yPIMYcgBhzH2LMw9UQY9inPCDNmAcQY6CB870aakx6dRYA32qFdg", "rows": [ { "id":"0bd8dab855b66e643350625a33d79b00", "order":[9.491182327270508,925635], "fields": { "default":"0000789019", "conceptNameSplit":"Deferred Revenue Revenue Recognized" } } ... continues ... ] } 注意结果中的第一个字段 "total_rows" 。Cloudant 知道有多少个结果。然而,它只会给您一次提供 200 个结果。请注意结果中的第二个字段 "bookmark" 。要获得接下来的 n 个结果,只需使用 "bookmark=" 参数调用相同的 URI,并使用前 n 个结果提供的书签。使用神奇的 Node.js、流和递归,我们来看一个简单方法,该方法将会获得每个结果的第一个流,然后获得 n 个不同结果的列表。首先,我们需要一个流,它可以提取书签值,并将其存储在一个通过引用传递的变量中。
stream = require('stream') class exports.JSONArrayTransformStream extends stream.Transform constructor: () -> @first = true super objectMode: true _transform: (chunk, enc, next) -> if (@first) @push('[') @first = false else @push(',/n') @push(JSON.stringify(chunk)) next() _flush: (next) -> if (@first) @push('[]') else @push(']') next() 接下来,我们需要一个流来采用传入的对象,然后将它们作为一个 JSON 数组进行输出。这假设我们到处发送结果,比如一个响应流、一个文件或控制台。
stream = require('stream') class exports.JSONArrayTransformStream extends stream.Transform constructor: () -> @first = true super objectMode: true _transform: (chunk, enc, next) -> if (@first) @push('[') @first = false else @push(',/n') @push(JSON.stringify(chunk)) next() _flush: (next) -> if (@first) @push('[]') else @push(']') next() 最后,我们将使用一个递归函数来按顺序执行每个 API 调用,并使用来自以前的调用的书签。在这里,JSONStream 包非常有用。
stream = require('stream') class exports.JSONArrayTransformStream extends stream.Transform constructor: () -> @first = true super objectMode: true _transform: (chunk, enc, next) -> if (@first) @push('[') @first = false else @push(',/n') @push(JSON.stringify(chunk)) next() _flush: (next) -> if (@first) @push('[]') else @push(']') next() 如果我们想要不同的结果,则需要一个新的流,累积在结束之前输出的结果。
stream = require('stream') class exports.DistinctingTransformStream extends stream.Transform #@keySelector: the name of a field in the object that we wish to find distinct values of #@limit: stop after finding this many distinct values constructor: (@keySelector, @limit) -> @myArray = {} super objectMode: true _transform: (chunk, enc, next) -> if (Object.keys(@myArray).length < @limit) @myArray[chunk[@keySelector]] = chunk[@keySelector] next() _flush: (next) -> for k,v of @myArray @push(v) next() 结束语
在本教程中,您已经了解了如何使用 Node.js 构建自己的企业级 Cloudant 财务数据数据库。还了解了如何利用 Web 绘图工具的表中的数据构建一个简单的用户界面。此外,我们还探讨了关于处理大型数据集并在这样的数据集中找到不同结果的一些经验分享。
附录:打开 Cloudant 仪表板
- 在 Bluemix 仪表板中单击您的应用程序。您会看到一个如下所示的屏幕:
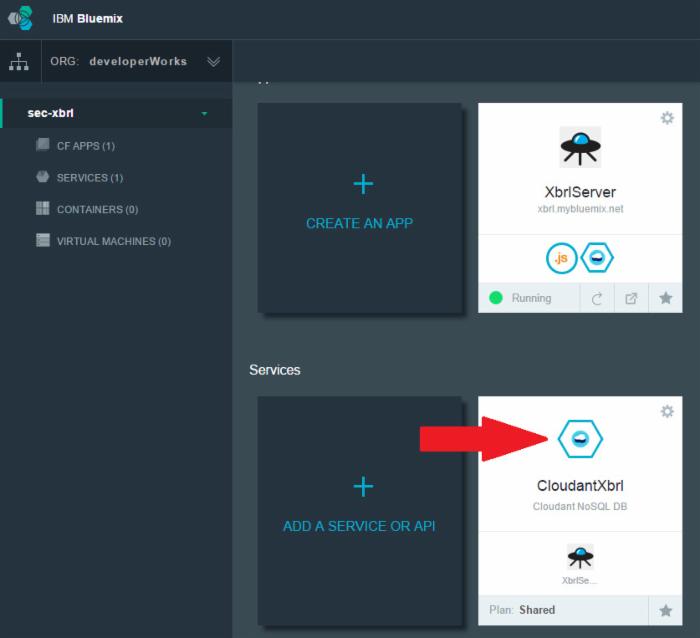
点击查看大图
关闭 [x]
- 单击 Cloudant 图标。
- 在下一个屏幕中,单击 Launch 按钮。
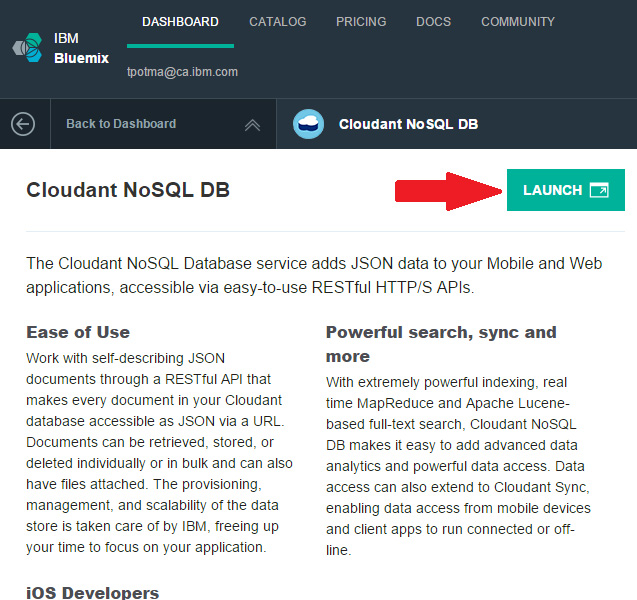
点击查看大图
关闭 [x]
- Cloudant NoSQL 服务,提供了对一个总处于在线状态的完全托管 NoSQL JSON 数据层的访问。
正文到此结束
- 本文标签: web ip find 网站 IDE App value zip db tar cat 数据 CTO key java node 产品 UI 空间 XML 目录 remote CDN 互联网 金融 时间 json IBM js 线程 安装 代码 实例 tab https 美国 map GitHub Select 企业 测试 git 数据库 NOSQL Node.js parse 开发 服务器 struct description sql API 解析 参数
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

