Eureka 源码解析 —— EndPoint 与 解析器
������关注 微信公众号:【芋道源码】 有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有 源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言 都 将得到 认真 回复。 甚至不知道如何读源码也可以请教噢 。
- 新的 源码解析文章 实时 收到通知。 每周更新一篇左右 。
- 认真的 源码交流微信群。
1. 概述
本文主要分享 EndPoint 与 解析器 。
- EndPoint ,服务端点。例如,Eureka-Server 的访问地址。
- EndPoint 解析器,将配置的 Eureka-Server 的访问地址解析成 EndPoint 。
目前有多种 Eureka-Server 访问地址的配置方式, 本文只分享 Eureka 1.x 的配置 ,不包含 Eureka 1.x 对 Eureka 2.x 的兼容配置:
- 第一种,直接配置实际访问地址。例如,
eureka.serviceUrl.defaultZone=http://127.0.0.1:8080/v2。 - 第二种,基于 DNS 解析出访问地址。例如,
eureka.shouldUseDns=true并且eureka.eurekaServer.domainName=eureka.iocoder.cn。
本文涉及类在 com.netflix.discovery.shared.resolver 包下,涉及到主体类的类图如下(打开大图 ):
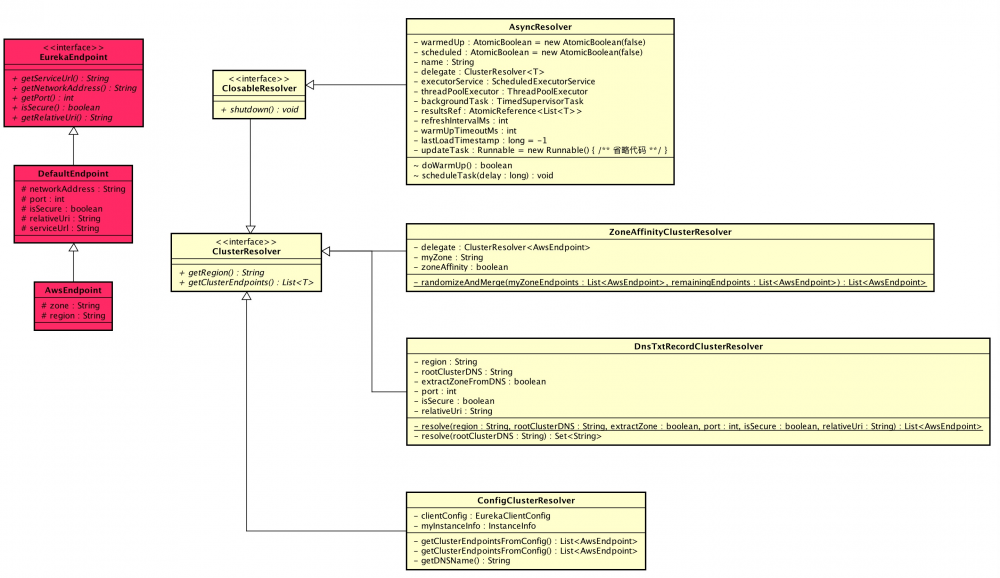
- 红色部分 —— EndPoint
- 黄色部分 —— EndPoint 解析器
推荐 Spring Cloud 书籍:
- 请支持正版。下载盗版, 等于主动编写低级 BUG 。
- 程序猿DD —— 《Spring Cloud微服务实战》
- 周立 —— 《Spring Cloud与Docker微服务架构实战》
- 两书齐买,京东包邮。
2. EndPoint
2.1 EurekaEndpoint
com.netflix.discovery.shared.resolver.EurekaEndpoint ,Eureka 服务端点 接口 ,实现代码如下:
public interface EurekaEndpoint extends Comparable<Object>{
/**
* @return 完整的服务 URL
*/
String getServiceUrl();
/**
* @deprecated use {@link #getNetworkAddress()}
*/
@Deprecated
String getHostName();
/**
* @return 网络地址
*/
String getNetworkAddress();
/**
* @return 端口
*/
int getPort();
/**
* @return 是否安全( https )
*/
boolean isSecure();
/**
* @return 相对路径
*/
String getRelativeUri();
}
2.2 DefaultEndpoint
com.netflix.discovery.shared.resolver.DefaultEndpoint ,默认 Eureka 服务端点 实现类 。实现代码如下:
public class DefaultEndpoint implements EurekaEndpoint{
/**
* 网络地址
*/
protected final String networkAddress;
/**
* 端口
*/
protected final int port;
/**
* 是否安全( https )
*/
protected final boolean isSecure;
/**
* 相对地址
*/
protected final String relativeUri;
/**
* 完整的服务 URL
*/
protected final String serviceUrl;
public DefaultEndpoint(String serviceUrl){
this.serviceUrl = serviceUrl;
// 将 serviceUrl 分解成 几个属性
try {
URL url = new URL(serviceUrl);
this.networkAddress = url.getHost();
this.port = url.getPort();
this.isSecure = "https".equals(url.getProtocol());
this.relativeUri = url.getPath();
} catch (Exception e) {
throw new IllegalArgumentException("Malformed serviceUrl: " + serviceUrl);
}
}
public DefaultEndpoint(String networkAddress, int port, boolean isSecure, String relativeUri){
this.networkAddress = networkAddress;
this.port = port;
this.isSecure = isSecure;
this.relativeUri = relativeUri;
// 几个属性 拼接成 serviceUrl
StringBuilder sb = new StringBuilder().append(isSecure ? "https" : "http").append("://").append(networkAddress);
if (port >= 0) {
sb.append(':').append(port);
}
if (relativeUri != null) {
if (!relativeUri.startsWith("/")) {
sb.append('/');
}
sb.append(relativeUri);
}
this.serviceUrl = sb.toString();
}
}
- 重写了
#equals(...)和#hashCode(...)方法,标准实现方式,这里就不贴代码了。 - 重写了
#compareTo(...)方法,基于serviceUrl属性做比较。
2.3 AwsEndpoint
com.netflix.discovery.shared.resolver.aws.AwsEndpoint ,基于 region 、 zone 的 Eureka 服务端点 实现类 ( 请不要在意 AWS 开头 )。实现代码如下:
public class AwsEndpoint extends DefaultEndpoint{
/**
* 区域
*/
protected final String region;
/**
* 可用区
*/
protected final String zone;
}
- 重写了
#equals(...)和#hashCode(...)方法,标准实现方式,这里就不贴代码了。
3. 解析器
EndPoint 解析器使用 委托设计模式 实现。所以,上文图片中我们看到好多个解析器, 实际代码非常非常非常清晰 。
FROM 《委托模式》
委托模式是软件设计模式中的一项基本技巧。在委托模式中,有两个对象参与处理同一个请求,接受请求的对象将请求委托给另一个对象来处理。委托模式是一项基本技巧,许多其他的模式,如状态模式、策略模式、访问者模式本质上是在更特殊的场合采用了委托模式。委托模式使得我们可以用聚合来替代继承,它还使我们可以模拟mixin。
我们在上图的基础上, 增加委托的关系 ,如下图:
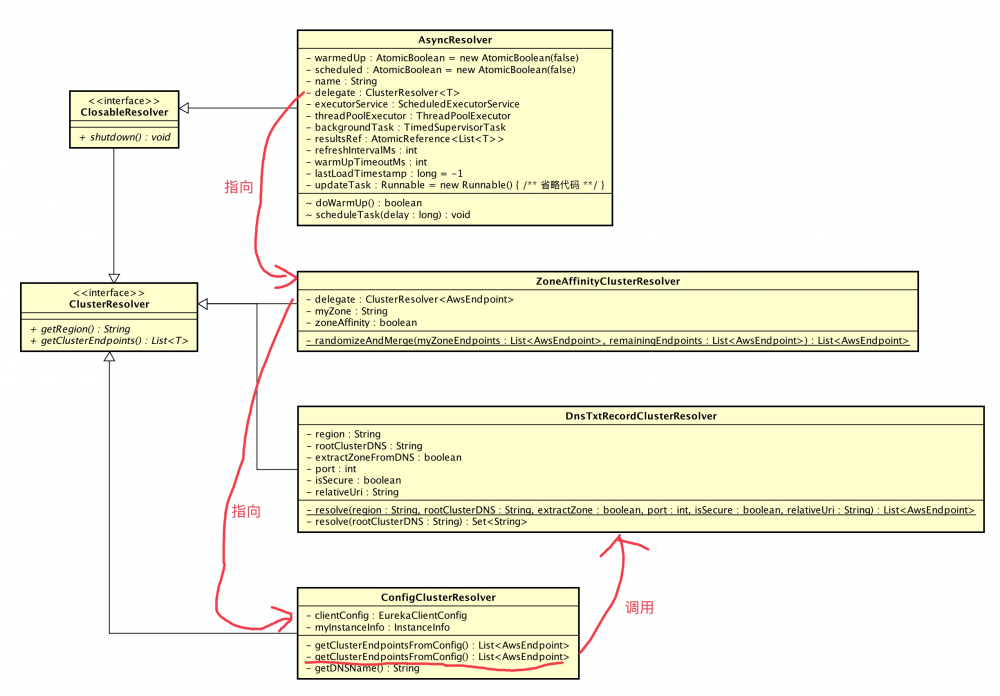
3.1 ClusterResolver
com.netflix.discovery.shared.resolver.ClusterResolver ,集群解析器 接口 。接口代码如下:
public interface ClusterResolver<T extends EurekaEndpoint>{
/**
* @return 地区
*/
String getRegion();
/**
* @return EndPoint 集群( 数组 )
*/
List<T> getClusterEndpoints();
}
3.2 ClosableResolver
com.netflix.discovery.shared.resolver.ClosableResolver , 可关闭 的解析器 接口 ,继承自 ClusterResolver 接口 。接口代码如下:
public interface ClosableResolver<T extends EurekaEndpoint> extends ClusterResolver<T>{
/**
* 关闭
*/
void shutdown();
}
3.3 DnsTxtRecordClusterResolver
com.netflix.discovery.shared.resolver.aws.DnsTxtRecordClusterResolver ,基于 DNS TXT 记录类型的集群解析器。 类属性 代码如下:
public class DnsTxtRecordClusterResolver implements ClusterResolver<AwsEndpoint>{
/**
* 地区
*/
private final String region;
/**
* 集群根地址,例如 txt.default.eureka.iocoder.cn
*/
private final String rootClusterDNS;
/**
* 是否解析可用区( zone )
*/
private final boolean extractZoneFromDNS;
/**
* 端口
*/
private final int port;
/**
* 是否安全
*/
private final boolean isSecure;
/**
* 相对地址
*/
private final String relativeUri;
}
-
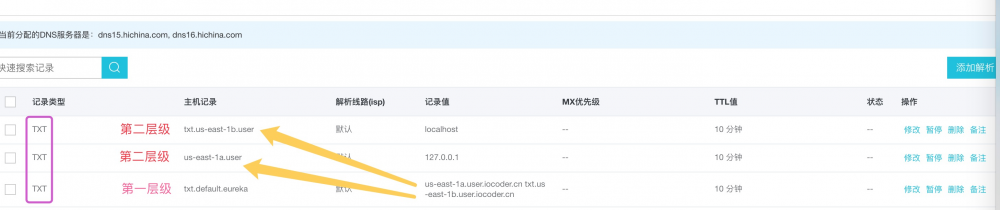
DnsTxtRecordClusterResolver 通过集群根地址(
rootClusterDNS) 解析出 EndPoint 集群。需要在 DNS 配置 两层 解析记录:- 第一层 :
- 主机记录 :格式为
TXT.${REGION}.${自定义二级域名}。 - 记录类型 : TXT 记录类型 。
- 记录值 :第二层的 主机记录 。如有多个第二层级,使用 空格 分隔。
- 主机记录 :格式为
- 第二层:
- 主机记录 :格式为
TXT.${ZONE}.${自定义二级域名}或者${ZONE}.${自定义二级域名}。 - 记录类型 : TXT 记录类型 。
- 记录值 :EndPoint 的网络地址。如有多个 EndPoint,使用 空格 分隔。
-
举个例子:
-
- 主机记录 :格式为
- 第一层 :
-
rootClusterDNS,集群根地址。例如:txt.default.eureka.iocoder.cn,其·txt.default.eureka为 DNS 解析记录的第一层的 主机记录 。 -
region:地区。需要和rootClusterDNS的${REGION}一致。 -
extractZoneFromDNS:是否解析 DNS 解析记录的第二层级的 主机记录 的${ZONE}可用区。
#getClusterEndpoints(...) 方法,实现代码如下:
1: @Override
2: public List<AwsEndpoint> getClusterEndpoints(){
3: List<AwsEndpoint> eurekaEndpoints = resolve(region, rootClusterDNS, extractZoneFromDNS, port, isSecure, relativeUri);
4: if (logger.isDebugEnabled()) {
5: logger.debug("Resolved {} to {}", rootClusterDNS, eurekaEndpoints);
6: }
7: return eurekaEndpoints;
8: }
9:
10: private static List<AwsEndpoint> resolve(String region, String rootClusterDNS, boolean extractZone, int port, boolean isSecure, String relativeUri){
11: try {
12: // 解析 第一层 DNS 记录
13: Set<String> zoneDomainNames = resolve(rootClusterDNS);
14: if (zoneDomainNames.isEmpty()) {
15: throw new ClusterResolverException("Cannot resolve Eureka cluster addresses; there are no data in TXT record for DN " + rootClusterDNS);
16: }
17: // 记录 第二层 DNS 记录
18: List<AwsEndpoint> endpoints = new ArrayList<>();
19: for (String zoneDomain : zoneDomainNames) {
20: String zone = extractZone ? ResolverUtils.extractZoneFromHostName(zoneDomain) : null; //
21: Set<String> zoneAddresses = resolve(zoneDomain);
22: for (String address : zoneAddresses) {
23: endpoints.add(new AwsEndpoint(address, port, isSecure, relativeUri, region, zone));
24: }
25: }
26: return endpoints;
27: } catch (NamingException e) {
28: throw new ClusterResolverException("Cannot resolve Eureka cluster addresses for root: " + rootClusterDNS, e);
29: }
30: }
-
第 12 至 16 行 :调用
#resolve(rootClusterDNS)解析 第一层 DNS 记录。实现代码如下:1: private static Set<String> resolve(String rootClusterDNS) throws NamingException{ 2: Set<String> result; 3: try { 4: result = DnsResolver.getCNamesFromTxtRecord(rootClusterDNS); 5: // TODO 芋艿:这块是bug,不需要这一段 6: if (!rootClusterDNS.startsWith("txt.")) { 7: result = DnsResolver.getCNamesFromTxtRecord("txt." + rootClusterDNS); 8: } 9: } catch (NamingException e) { 10: if (!rootClusterDNS.startsWith("txt.")) { 11: result = DnsResolver.getCNamesFromTxtRecord("txt." + rootClusterDNS); 12: } else { 13: throw e; 14: } 15: } 16: return result; 17: }- 第 4 行 : 调用
DnsResolver#getCNamesFromTxtRecord(...)方法,解析 TXT 主机记录。点击 链接 查看带中文注释的 DnsResolver 的代码,比较解析,笔者就不啰嗦了。 - 第 5 至 8 行 :当传递参数
rootClusterDNS不以txt.开头时,即使第 4 行解析成功,也会报错,此时是个 Eureka 的 BUG 。因此,配置 DNS 解析记录时,主机记录暂时必须以txt.开头。
- 第 4 行 : 调用
-
第 17 至 25 行 :循环第一层 DNS 记录的解析结果,进一步解析第二层 DNS 记录。
- 第 20 行 :解析可用区(
zone)。 - 第 21 行 :调用
#resolve(rootClusterDNS)解析 第二层 DNS 记录。
- 第 20 行 :解析可用区(
3.4 ConfigClusterResolver
com.netflix.discovery.shared.resolver.aws.ConfigClusterResolver ,基于 配置文件 的集群解析器。 类属性 代码如下:
public class ConfigClusterResolver implements ClusterResolver<AwsEndpoint>{
private final EurekaClientConfig clientConfig;
private final InstanceInfo myInstanceInfo;
public ConfigClusterResolver(EurekaClientConfig clientConfig, InstanceInfo myInstanceInfo){
this.clientConfig = clientConfig;
this.myInstanceInfo = myInstanceInfo;
}
}
#getClusterEndpoints(...) 方法,实现代码如下:
1: @Override
2: public List<AwsEndpoint> getClusterEndpoints(){
3: // 使用 DNS 获取 EndPoint
4: if (clientConfig.shouldUseDnsForFetchingServiceUrls()) {
5: if (logger.isInfoEnabled()) {
6: logger.info("Resolving eureka endpoints via DNS: {}", getDNSName());
7: }
8: return getClusterEndpointsFromDns();
9: } else {
10: // 直接配置实际访问地址
11: logger.info("Resolving eureka endpoints via configuration");
12: return getClusterEndpointsFromConfig();
13: }
14: }
-
第 3 至 8 行 :基于 DNS 获取 EndPoint 集群,调用
#getClusterEndpointsFromDns()方法,实现代码如下:private List<AwsEndpoint> getClusterEndpointsFromDns(){ String discoveryDnsName = getDNSName(); // 获取 集群根地址 int port = Integer.parseInt(clientConfig.getEurekaServerPort()); // 端口 // cheap enough so just re-use DnsTxtRecordClusterResolver dnsResolver = new DnsTxtRecordClusterResolver( getRegion(), discoveryDnsName, true, // 解析 zone port, false, clientConfig.getEurekaServerURLContext() ); // 调用 DnsTxtRecordClusterResolver 解析 EndPoint List<AwsEndpoint> endpoints = dnsResolver.getClusterEndpoints(); if (endpoints.isEmpty()) { logger.error("Cannot resolve to any endpoints for the given dnsName: {}", discoveryDnsName); } return endpoints; } private String getDNSName(){ return "txt." + getRegion() + '.' + clientConfig.getEurekaServerDNSName(); }- 必须配置
eureka.shouldUseDns=true,开启基于 DNS 获取 EndPoint 集群。 - 必须配置
eureka.eurekaServer.domainName=${xxxxx},配置集群根地址。 - 选填配
eureka.eurekaServer.port,eureka.eurekaServer.context。 - 从代码中我们可以看出,使用 DnsTxtRecordClusterResolver 解析出 EndPoint 集群。
- 必须配置
-
第 9 至 13 行 :直接 配置文件 填写实际 EndPoint 集群,调用
#getClusterEndpointsFromConfig()方法,实现代码如下:
1: private List<AwsEndpoint> getClusterEndpointsFromConfig(){
2: // 获得 可用区
3: String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion());
4: // 获取 应用实例自己 的 可用区
5: String myZone = InstanceInfo.getZone(availZones, myInstanceInfo);
6: // 获得 可用区与 serviceUrls 的映射
7: Map<String, List<String>> serviceUrls = EndpointUtils.getServiceUrlsMapFromConfig(clientConfig, myZone, clientConfig.shouldPreferSameZoneEureka());
8: // 拼装 EndPoint 集群结果
9: List<AwsEndpoint> endpoints = new ArrayList<>();
10: for (String zone : serviceUrls.keySet()) {
11: for (String url : serviceUrls.get(zone)) {
12: try {
13: endpoints.add(new AwsEndpoint(url, getRegion(), zone));
14: } catch (Exception ignore) {
15: logger.warn("Invalid eureka server URI: {}; removing from the server pool", url);
16: }
17: }
18: }
19:
20: // 打印日志,EndPoint 集群
21: if (logger.isDebugEnabled()) {
22: logger.debug("Config resolved to {}", endpoints);
23: }
24: // 打印日志,解析结果为空
25: if (endpoints.isEmpty()) {
26: logger.error("Cannot resolve to any endpoints from provided configuration: {}", serviceUrls);
27: }
28:
29: return endpoints;
30: }
- 第 3 行 :获得可用区数组。通过
eureka.${REGION}.availabilityZones配置。 - 第 5 行 :调用
InstanceInfo#getZone(...)方法,获得 应用实例自己所在的可用区 (zone)。非亚马逊 AWS 环境下,可用区数组的第一个元素就是 应用实例自己所在的可用区 。 -
第 7 行 :调用
EndpointUtils#getServiceUrlsMapFromConfig(...)方法,获得可用区与serviceUrls的映射。实现代码如下:// EndpointUtils.java 1: public static Map<String, List<String>> getServiceUrlsMapFromConfig(EurekaClientConfig clientConfig, String instanceZone, boolean preferSameZone) { 2: Map<String, List<String>> orderedUrls = new LinkedHashMap<>(); // key:zone;value:serviceUrls 3: // 获得 应用实例的 地区( region ) 4: String region = getRegion(clientConfig); 5: // 获得 应用实例的 可用区 6: String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion()); 7: if (availZones == null || availZones.length == 0) { 8: availZones = new String[1]; 9: availZones[0] = DEFAULT_ZONE; 10: } 11: logger.debug("The availability zone for the given region {} are {}", region, Arrays.toString(availZones)); 12: // 获得 开始位置 13: int myZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones); 14: // 将 开始位置 的 serviceUrls 添加到结果 15: String zone = availZones[myZoneOffset]; 16: List<String> serviceUrls = clientConfig.getEurekaServerServiceUrls(zone); 17: if (serviceUrls != null) { 18: orderedUrls.put(zone, serviceUrls); 19: } 20: // 从开始位置顺序遍历剩余的 serviceUrls 添加到结果 21: int currentOffset = myZoneOffset == (availZones.length - 1) ? 0 : (myZoneOffset + 1); 22: while (currentOffset != myZoneOffset) { 23: zone = availZones[currentOffset]; 24: serviceUrls = clientConfig.getEurekaServerServiceUrls(zone); 25: if (serviceUrls != null) { 26: orderedUrls.put(zone, serviceUrls); 27: } 28: if (currentOffset == (availZones.length - 1)) { 29: currentOffset = 0; 30: } else { 31: currentOffset++; 32: } 33: } 34: 35: // 为空,报错 36: if (orderedUrls.size() < 1) { 37: throw new IllegalArgumentException("DiscoveryClient: invalid serviceUrl specified!"); 38: } 39: return orderedUrls; 40: }-
第 13 行 :获得 开始位置 。实现代码如下:
private static int getZoneOffset(String myZone, boolean preferSameZone, String[] availZones){ for (int i = 0; i < availZones.length; i++) { if (myZone != null && (availZones[i].equalsIgnoreCase(myZone.trim()) == preferSameZone)) { return i; } } logger.warn("DISCOVERY: Could not pick a zone based on preferred zone settings. My zone - {}," + " preferSameZone- {}. Defaulting to " + availZones[0], myZone, preferSameZone); return 0; }- 当方法参数
preferSameZone=true,即eureka.preferSameZone=true( 默认值 :true) 时, 开始位置 为可用区数组(availZones)的 第一个 和应用实例所在的可用区(myZone)【 相等 】元素的位置。 - 当方法参数
preferSameZone=false,即eureka.preferSameZone=false( 默认值 :true) 时, 开始位置 为可用区数组(availZones)的 第一个 和应用实例所在的可用区(myZone)【 不相等 】元素的位置。
- 当方法参数
-
第 20 至 33 行 :从开始位置 顺序 将剩余的可用区的
serviceUrls添加到结果。 顺序 理解如下图: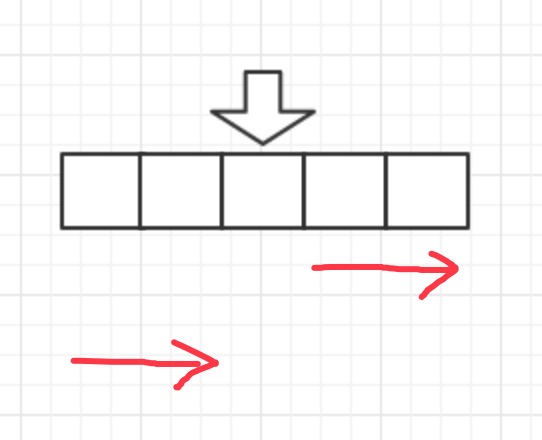
-
-
第 9 至 18 行 :拼装 EndPoint 集群结果。
3.5 ZoneAffinityClusterResolver
com.netflix.discovery.shared.resolver.aws.ZoneAffinityClusterResolver ,使用可用区亲和的集群解析器。 类属性 代码如下:
public class ZoneAffinityClusterResolver implements ClusterResolver<AwsEndpoint>{
private static final Logger logger = LoggerFactory.getLogger(ZoneAffinityClusterResolver.class);
/**
* 委托的解析器
* 目前代码里为 {@link ConfigClusterResolver}
*/
private final ClusterResolver<AwsEndpoint> delegate;
/**
* 应用实例的可用区
*/
private final String myZone;
/**
* 是否可用区亲和
*/
private final boolean zoneAffinity;
public ZoneAffinityClusterResolver(ClusterResolver<AwsEndpoint> delegate, String myZone, boolean zoneAffinity){
this.delegate = delegate;
this.myZone = myZone;
this.zoneAffinity = zoneAffinity;
}
}
- 属性
delegate,委托的解析器。目前代码里使用的是 ConfigClusterResolver 。 - 属性
zoneAffinity,是否可用区亲和。-
true:EndPoint 可用区为 本地 的优先被放在前面。 -
false:EndPoint 可用区 非本地 的优先被放在前面。
-
#getClusterEndpoints(...) 方法,实现代码如下:
1: @Override
2: public List<AwsEndpoint> getClusterEndpoints(){
3: // 拆分成 本地的可用区和非本地的可用区的 EndPoint 集群
4: List<AwsEndpoint>[] parts = ResolverUtils.splitByZone(delegate.getClusterEndpoints(), myZone);
5: List<AwsEndpoint> myZoneEndpoints = parts[0];
6: List<AwsEndpoint> remainingEndpoints = parts[1];
7: // 随机打乱 EndPoint 集群并进行合并
8: List<AwsEndpoint> randomizedList = randomizeAndMerge(myZoneEndpoints, remainingEndpoints);
9: // 非可用区亲和,将非本地的可用区的 EndPoint 集群放在前面
10: if (!zoneAffinity) {
11: Collections.reverse(randomizedList);
12: }
13:
14: if (logger.isDebugEnabled()) {
15: logger.debug("Local zone={}; resolved to: {}", myZone, randomizedList);
16: }
17:
18: return randomizedList;
19: }
- 第 2 行 :调用
ClusterResolver#getClusterEndpoints()方法,获得 EndPoint 集群。再调用ResolverUtils#splitByZone(...)方法,拆分成 本地 和 非本地 的可用区的 EndPoint 集群,点击 链接 查看实现。 -
第 8 行 :调用
#randomizeAndMerge(...)方法, 分别 随机打乱 每个 EndPoint 集群,并进行 合并 数组,实现代码如下:// ZoneAffinityClusterResolver.java private static List<AwsEndpoint> randomizeAndMerge(List<AwsEndpoint> myZoneEndpoints, List<AwsEndpoint> remainingEndpoints){ if (myZoneEndpoints.isEmpty()) { return ResolverUtils.randomize(remainingEndpoints); // 打乱 } if (remainingEndpoints.isEmpty()) { return ResolverUtils.randomize(myZoneEndpoints); // 打乱 } List<AwsEndpoint> mergedList = ResolverUtils.randomize(myZoneEndpoints); // 打乱 mergedList.addAll(ResolverUtils.randomize(remainingEndpoints)); // 打乱 return mergedList; } // ResolverUtils.java public static <T extends EurekaEndpoint> List<T> randomize(List<T> list){ // 数组大小为 0 或者 1 ,不进行打乱 List<T> randomList = new ArrayList<>(list); if (randomList.size() < 2) { return randomList; } // 以本地IP为随机种子,有如下好处: // 多个主机,实现对同一个 EndPoint 集群负载均衡的效果。 // 单个主机,同一个 EndPoint 集群按照固定顺序访问。Eureka-Server 不是强一致性的注册中心,Eureka-Client 对同一个 Eureka-Server 拉取注册信息,保证两者之间增量同步的一致性。 Random random = new Random(LOCAL_IPV4_ADDRESS.hashCode()); int last = randomList.size() - 1; for (int i = 0; i < last; i++) { int pos = random.nextInt(randomList.size() - i); if (pos != i) { Collections.swap(randomList, i, pos); } } return randomList; }- 注意,
ResolverUtils#randomize(...)使用以本机IP为随机种子 ,有如下好处:- 多个主机,实现对同一个 EndPoint 集群负载均衡的效果。
- 单个主机,同一个 EndPoint 集群按照固定顺序访问。Eureka-Server 不是强一致性的注册中心,Eureka-Client 对同一个 Eureka-Server 拉取注册信息,保证两者之间增量同步的一致性。
- 注意,
-
第 10 至 12 行 :非可用区亲和,将非本地的可用区的 EndPoint 集群放在前面。
3.6 AsyncResolver
com.netflix.discovery.shared.resolver.AsyncResolver , 异步执行 解析的集群解析器。AsyncResolver 属性较多,而且复杂的多,我们拆分到具体方法里分享。
3.6.1 定时任务
AsyncResolver 内置定时任务, 定时 刷新 EndPoint 集群解析结果。
为什么要刷新?例如,Eureka-Server 的 serviceUrls 基于 DNS 配置。
定时任务代码如下:
/**
* 是否已经调度定时任务 {@link #updateTask}
*/
private final AtomicBoolean scheduled = new AtomicBoolean(false);
/**
* 委托的解析器
* 目前代码为 {@link com.netflix.discovery.shared.resolver.aws.ZoneAffinityClusterResolver}
*/
private final ClusterResolver<T> delegate;
/**
* 定时服务
*/
private final ScheduledExecutorService executorService;
/**
* 线程池执行器
*/
private final ThreadPoolExecutor threadPoolExecutor;
/**
* 后台任务
* 定时解析 EndPoint 集群
*/
private final TimedSupervisorTask backgroundTask;
/**
* 解析 EndPoint 集群结果
*/
private final AtomicReference<List<T>> resultsRef;
/**
* 定时解析 EndPoint 集群的频率
*/
private final int refreshIntervalMs;
/**
* 预热超时时间,单位:毫秒
*/
private final int warmUpTimeoutMs;
// Metric timestamp, tracking last time when data were effectively changed.
private volatile long lastLoadTimestamp = -1;
AsyncResolver(String name,
ClusterResolver<T> delegate,
List<T> initialValue,
int executorThreadPoolSize,
int refreshIntervalMs,
int warmUpTimeoutMs) {
this.name = name;
this.delegate = delegate;
this.refreshIntervalMs = refreshIntervalMs;
this.warmUpTimeoutMs = warmUpTimeoutMs;
// 初始化 定时服务
this.executorService = Executors.newScheduledThreadPool(1, // 线程大小=1
new ThreadFactoryBuilder()
.setNameFormat("AsyncResolver-" + name + "-%d")
.setDaemon(true)
.build());
// 初始化 线程池执行器
this.threadPoolExecutor = new ThreadPoolExecutor(
1, // 线程大小=1
executorThreadPoolSize, 0, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), // use direct handoff
new ThreadFactoryBuilder()
.setNameFormat("AsyncResolver-" + name + "-executor-%d")
.setDaemon(true)
.build()
);
// 初始化 后台任务
this.backgroundTask = new TimedSupervisorTask(
this.getClass().getSimpleName(),
executorService,
threadPoolExecutor,
refreshIntervalMs,
TimeUnit.MILLISECONDS,
5,
updateTask
);
this.resultsRef = new AtomicReference<>(initialValue);
Monitors.registerObject(name, this);
}
-
backgroundTask,后台任务,定时解析 EndPoint 集群。- TimedSupervisorTask ,在 《Eureka 源码解析 —— 应用实例注册发现(二)之续租》「2.3 TimedSupervisorTask」 有详细解析。
-
updateTask实现代码如下:private final Runnable updateTask = new Runnable() { @Override public void run(){ try { List<T> newList = delegate.getClusterEndpoints(); // 调用 委托的解析器 解析 EndPoint 集群 if (newList != null) { resultsRef.getAndSet(newList); lastLoadTimestamp = System.currentTimeMillis(); } else { logger.warn("Delegate returned null list of cluster endpoints"); } logger.debug("Resolved to {}", newList); } catch (Exception e) { logger.warn("Failed to retrieve cluster endpoints from the delegate", e); } } };-
delegate,委托的解析器,目前代码为 ZoneAffinityClusterResolver。
-
-
后台任务的 发起 在
#getClusterEndpoints()方法,在「3.6.2 解析 EndPoint 集群」详细解析。
3.6.2 解析 EndPoint 集群
调用 #getClusterEndpoints() 方法,解析 EndPoint 集群,实现代码如下:
1: @Override
2: public List<T> getClusterEndpoints(){
3: long delay = refreshIntervalMs;
4: // 若未预热解析 EndPoint 集群结果,进行预热
5: if (warmedUp.compareAndSet(false, true)) {
6: if (!doWarmUp()) {
7: delay = 0; // 预热失败,取消定时任务的第一次延迟
8: }
9: }
10: // 若未调度定时任务,进行调度
11: if (scheduled.compareAndSet(false, true)) {
12: scheduleTask(delay);
13: }
14: // 返回 EndPoint 集群
15: return resultsRef.get();
16: }
-
第 5 至 9 行 : 若未预热解析 EndPoint 集群结果 ,调用
#doWarmUp()方法,进行预热。若预热失败,取消定时任务的第一次延迟。#doWarmUp()方法实现代码如下:boolean doWarmUp(){ Future future = null; try { future = threadPoolExecutor.submit(updateTask); future.get(warmUpTimeoutMs, TimeUnit.MILLISECONDS); // block until done or timeout return true; } catch (Exception e) { logger.warn("Best effort warm up failed", e); } finally { if (future != null) { future.cancel(true); } } return false; }- 调用
updateTask,解析 EndPoint 集群。
- 调用
-
第 10 至 13 行 : 若未调度定时任务,进行调度 ,调用
#scheduleTask()方法,实现代码如下:void scheduleTask(long delay){ executorService.schedule(backgroundTask, delay, TimeUnit.MILLISECONDS); } -
第 15 行 :返回 EndPoint 集群。 当第一次预热失败,会返回空,直到定时任务获得到结果 。
4. 初始化解析器
Eureka-Client 在初始化时,调用 DiscoveryClient#scheduleServerEndpointTask() 方法,初始化 AsyncResolver 解析器。实现代码如下:
private void scheduleServerEndpointTask(EurekaTransport eurekaTransport,
AbstractDiscoveryClientOptionalArgs args){
// ... 省略无关代码
// 创建 EndPoint 解析器
eurekaTransport.bootstrapResolver = EurekaHttpClients.newBootstrapResolver(
clientConfig,
transportConfig,
eurekaTransport.transportClientFactory,
applicationInfoManager.getInfo(),
applicationsSource
);
// ... 省略无关代码
}
-
调用
EurekaHttpClients#newBootstrapResolver(...)方法,创建 EndPoint 解析器,实现代码如下:1: public static final String COMPOSITE_BOOTSTRAP_STRATEGY = "composite"; 2: 3: public static ClosableResolver<AwsEndpoint> newBootstrapResolver( 4: final EurekaClientConfig clientConfig, 5: final EurekaTransportConfig transportConfig, 6: final TransportClientFactory transportClientFactory, 7: final InstanceInfo myInstanceInfo, 8: final ApplicationsResolver.ApplicationsSource applicationsSource) 9:{ 10: if (COMPOSITE_BOOTSTRAP_STRATEGY.equals(transportConfig.getBootstrapResolverStrategy())) { 11: if (clientConfig.shouldFetchRegistry()) { 12: return compositeBootstrapResolver( 13: clientConfig, 14: transportConfig, 15: transportClientFactory, 16: myInstanceInfo, 17: applicationsSource 18: ); 19: } else { 20: logger.warn("Cannot create a composite bootstrap resolver if registry fetch is disabled." + 21: " Falling back to using a default bootstrap resolver."); 22: } 23: } 24: 25: // if all else fails, return the default 26: return defaultBootstrapResolver(clientConfig, myInstanceInfo); 27: } 28: 29: /** 30: * @return a bootstrap resolver that resolves eureka server endpoints based on either DNS or static config, 31: * depending on configuration for one or the other. This resolver will warm up at the start. 32: */ 33: static ClosableResolver<AwsEndpoint> defaultBootstrapResolver(final EurekaClientConfig clientConfig, 34: final InstanceInfo myInstanceInfo){ 35: // 获得 可用区集合 36: String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion()); 37: // 获得 应用实例的 可用区 38: String myZone = InstanceInfo.getZone(availZones, myInstanceInfo); 39: 40: // 创建 ZoneAffinityClusterResolver 41: ClusterResolver<AwsEndpoint> delegateResolver = new ZoneAffinityClusterResolver( 42: new ConfigClusterResolver(clientConfig, myInstanceInfo), 43: myZone, 44: true 45: ); 46: 47: // 第一次 EndPoint 解析 48: List<AwsEndpoint> initialValue = delegateResolver.getClusterEndpoints(); 49: 50: // 解析不到 Eureka-Server EndPoint ,快速失败 51: if (initialValue.isEmpty()) { 52: String msg = "Initial resolution of Eureka server endpoints failed. Check ConfigClusterResolver logs for more info"; 53: logger.error(msg); 54: failFastOnInitCheck(clientConfig, msg); 55: } 56: 57: // 创建 AsyncResolver 58: return new AsyncResolver<>( 59: EurekaClientNames.BOOTSTRAP, 60: delegateResolver, 61: initialValue, 62: 1, 63: clientConfig.getEurekaServiceUrlPollIntervalSeconds() * 1000 64: ); 65: }
* 第 10 至 23 行 :组合解析器,用于 Eureka 1.x 对 Eureka 2.x 的兼容配置,暂时不需要了解。TODO[0028]写入集群和读取集群 * 第 26 行 :调用 `#defaultBootstrapResolver()` 方法,创建默认的解析器 AsyncResolver 。 * 第 40 至 45 行 :创建 ZoneAffinityClusterResolver 。在 ZoneAffinityClusterResolver 构造方法的参数,我们看到创建 ConfigClusterResolver 作为 `delegate` 参数。 * 第 48 行 :调用 `ZoneAffinityClusterResolver#getClusterEndpoints()` 方法,**第一次 Eureka-Server EndPoint 集群解析**。 * 第 51 至 55 行 :解析不到 Eureka-Server EndPoint 集群时,可以通过配置( `eureka.experimental.clientTransportFailFastOnInit=true` ),使 Eureka-Client 初始化失败。`#failFastOnInitCheck(...)` 方法,实现代码如下:
// potential future feature, guarding with experimental flag for now
private static void failFastOnInitCheck(EurekaClientConfig clientConfig, String msg){
if ("true".equals(clientConfig.getExperimental("clientTransportFailFastOnInit"))) {
throw new RuntimeException(msg);
}
}
* x
-
第 58 至 64 行 :创建 AsyncResolver 。从代码上,我们可以看到,
AsyncResolver.resultsRef属性一开始已经用initialValue传递给 AsyncResolver 构造方法。实现代码如下:public AsyncResolver(String name, ClusterResolver<T> delegate, List<T> initialValues, int executorThreadPoolSize, int refreshIntervalMs){ this( name, delegate, initialValues, executorThreadPoolSize, refreshIntervalMs, 0 ); // 设置已经预热 warmedUp.set(true); }
666. 彩蛋
T T 一开始看解析器,没反应过来是委托设计模式,一脸懵逼+一脸懵逼+一脸懵逼。后面理顺了,发现超级奈斯( Nice ) 啊 !!!!
胖友,你学会了么?
胖友,分享我的公众号( 芋道源码 ) 给你的胖友可好?
正文到此结束
- 本文标签: ORM ip DOM Eureka 一致性 cat src IDE queue root CTO Collection 负载均衡 Collections final 安全 ACE 代码 ioc parse 软件 RocketMQ 线程 client UI 微信公众号 update 域名 IO DNS Docker volatile apr http GitHub Service db 遍历 list id swap build Region 线程池 java 设计模式 图片 https 实例 参数 本质 京东 主机 亚马逊 Atom 端口 解析 服务端 tar value ThreadPoolExecutor 配置 下载 spring 注释 executor git URLs 程序猿 bug 集群 ask Bootstrap Transport 源码 App MQ key 同步 map 文章 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

