Java日志-Log4j源码分析
Log4j是一个历史非常悠久的库首次发布与2001年1月,有17年历史了,那个时候Java才发布1.3版本,所以也可以从Log4j的代码中看到他使用了很多古老的JDK类,比如Hashtable,可能是因为兼容性的考虑,后续的版本也一直没有升级这些地方。虽然Log4j历史悠久,但是应该还是使用最广泛的日志实现,我们分析其实现,还是能学到很多东西的,对于后续分析Log4j2或者Logback,都是有帮助的。
在读源码之前有几个疑问:
- Log4j支持什么类型的配置文件?这些配置文件同时存在于classpath中是什么效果?
- Log4j是如何实现其日志继承的模型的?
- Log4j是输出日志是写入内存缓存,还是直接写入操作系统?刷新到文件中的时机是如何的?
我们分为几个部分来了解Log4j的实现:
- Log4j的整体结构
- Log4j初始化读取配置的流程
- Log4j打印日志的流程
Log4j的整体结构
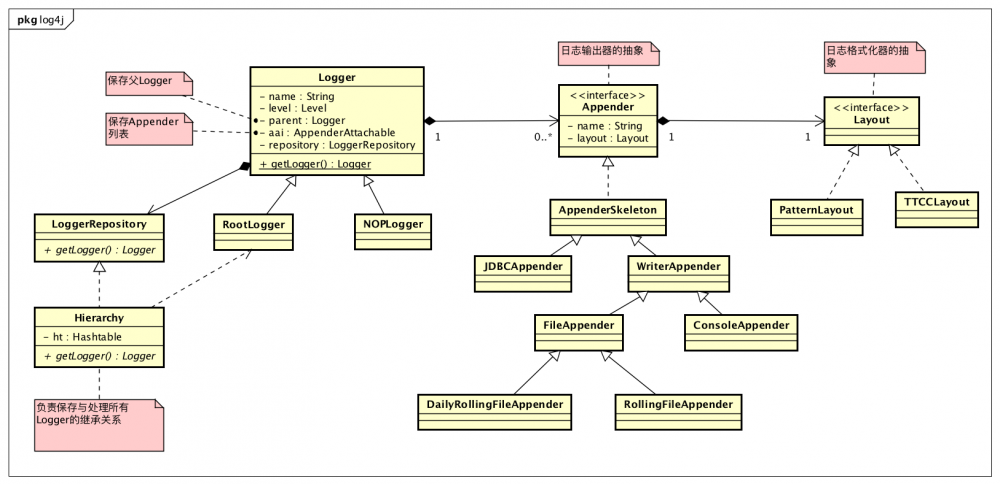
上图为Log4j的整体结构。Log4j中最重要的三个角色:
- Logger:日志类,用户操作的入口,提供获取日志类的静态方法与打印日志的方法
- Appender:日志输出器,根据配置,可以输出日志到不同的地方,比如文件,数据库
- Layout:日志格式化器,根据配置,可以按不同的方式格式化日志
这几个关键类和Log4j的配置项是一一对应的。Log4j在初始化时会解析配置,生成具体的Appender和Layout实现类,关联到指定的Logger上。同理,我们也可以在代码中直接配置。
比如 BasicConfigurator.configure() 这个Log4j提供的简化配置方法,可以在没有配置文件的情况下,把日志输出到控制台中,他就是直接使用代码配置的:
static public void configure() {
Logger root = Logger.getRootLogger();
// 设置RootLogger的Appender为ConsoleAppender
// 设置Layout为PatternLayout
root.addAppender(new ConsoleAppender(
new PatternLayout(PatternLayout.TTCC_CONVERSION_PATTERN)));
}
Logger是一个树结构的关系。根节点是RootLogger,这个是固定的。这个树结构和我们数据结构中学的树有一点不一样的地方,不是父节点中保存子节点的连接,而是子节点中保存父节点的连接。这和Logger的场景是匹配的,打印日志时, x.y 的Logger,首先查看自己身上是否配置有日志级别和Appender,如果有输出,然后查看其父Logger x ,查看是否配置有日志级别和Appender,如果有输出,然后再查看 x 的父Logger,也就是RootLogger,RootLogger一定会配置有日志级别,根据级别与Appender进行相应的操作。日志的继承关系是Log4j的核心。
除了每个Logger通过 parent 属性管理父Logger之外。还需要一个地方来保存所有的Logger,否则在新建Logger的时候,没法去查询对应的父Logger实例了。保存所有Logger的地方就在日志仓库LoggerRepository中,具体的实现类为Hierachy,这个类如其名,就是根据继承关系来管理Logger的日志仓库。其中有一个Hashtable来保存所有的Logger,key为Logger的name,value为Logger实例。
大致的结构说完了,我们来看一下一些场景的具体实现。
Log4j初始化加载日志的流程
Log4j的初始化过程发生在LogManager的静态代码块中:
static final String DEFAULT_CONFIGURATION_FILE = "log4j.properties";
static final String DEFAULT_XML_CONFIGURATION_FILE = "log4j.xml";
static {
// 实例化Hierarchy,设置RootLogger,并关联到LogManager上
// 这里新建RootLogger设置的日志级别为DEBUG,也就是说如果你在日志中没有配置RootLogger,则他的日志级别为DEBUG
Hierarchy h = new Hierarchy(new RootLogger((Level) Level.DEBUG));
repositorySelector = new DefaultRepositorySelector(h);
// 从classpath中获取log4j.xml文件
// 如果不存在,则尝试获取log4j.properties文件
URL url = null;
url = Loader.getResource(DEFAULT_XML_CONFIGURATION_FILE);
if (url == null) {
url = Loader.getResource(DEFAULT_CONFIGURATION_FILE);
}
if (url != null) {
try {
// 配置文件存在,进入配置文件解析流程
OptionConverter.selectAndConfigure(url, configuratorClassName,
LogManager.getLoggerRepository());
} catch (NoClassDefFoundError e) {
LogLog.warn("Error during default initialization", e);
}
} else {
LogLog.debug("Could not find resource: [" + configurationOptionStr + "].");
}
}
初始化的过程,先实例化Hierarchy类,设置好RootLogger,后续就是尝试读取两种可能的配置文件了,可以看出 log4j.xml 的优先级是要高于 log4j.properties 的。
OptionConverter.selectAndConfigure() 方法根据不同的配置文件类型,使用 PropertyConfigurator 或者 DOMConfigurator 类对配置文件进行处理:
static public void selectAndConfigure(URL url, String clazz, LoggerRepository hierarchy) {
Configurator configurator = null;
String filename = url.getFile();
// 如果是xml文件,使用DOMConfigurator类
if (clazz == null && filename != null && filename.endsWith(".xml")) {
clazz = "org.apache.log4j.xml.DOMConfigurator";
}
if (clazz != null) {
LogLog.debug("Preferred configurator class: " + clazz);
configurator = (Configurator) instantiateByClassName(clazz,
Configurator.class,
null);
if (configurator == null) {
LogLog.error("Could not instantiate configurator [" + clazz + "].");
return;
}
} else {
// 其他情况使用PropertyConfigurator类
configurator = new PropertyConfigurator();
}
configurator.doConfigure(url, hierarchy);
}
配置处理器的类图:
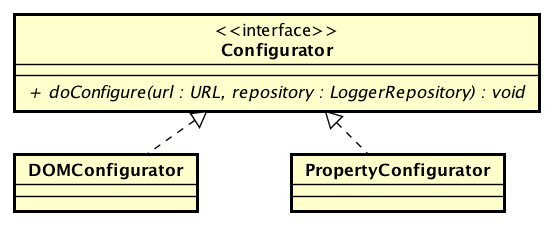
这里以 PropertyConfigutator为 例:
public void doConfigure(Properties properties, LoggerRepository hierarchy) {
// ...
// 设置RootLogger
configureRootCategory(properties, hierarchy);
// 设置LoggerFactory,基本用不上
configureLoggerFactory(properties);
// 设置其他Logger
parseCatsAndRenderers(properties, hierarchy);
}
从配置设置Logger的细节很多这里就不看了,主要的步骤就是根据Log4j的配置规则,读取配置,新建Logger,设置Logger的name,level,appender,layout等,新建后的Logger会存入LogRepository中。
上面的初始化过程发生在LogManager第一次被加载时。而用户一般是不用与LogManager直接打交道的,用户通过 Logger.getLogger() 来获取Logger,这个方法代理调用 LogManger.getLogger() ,时序图如下:
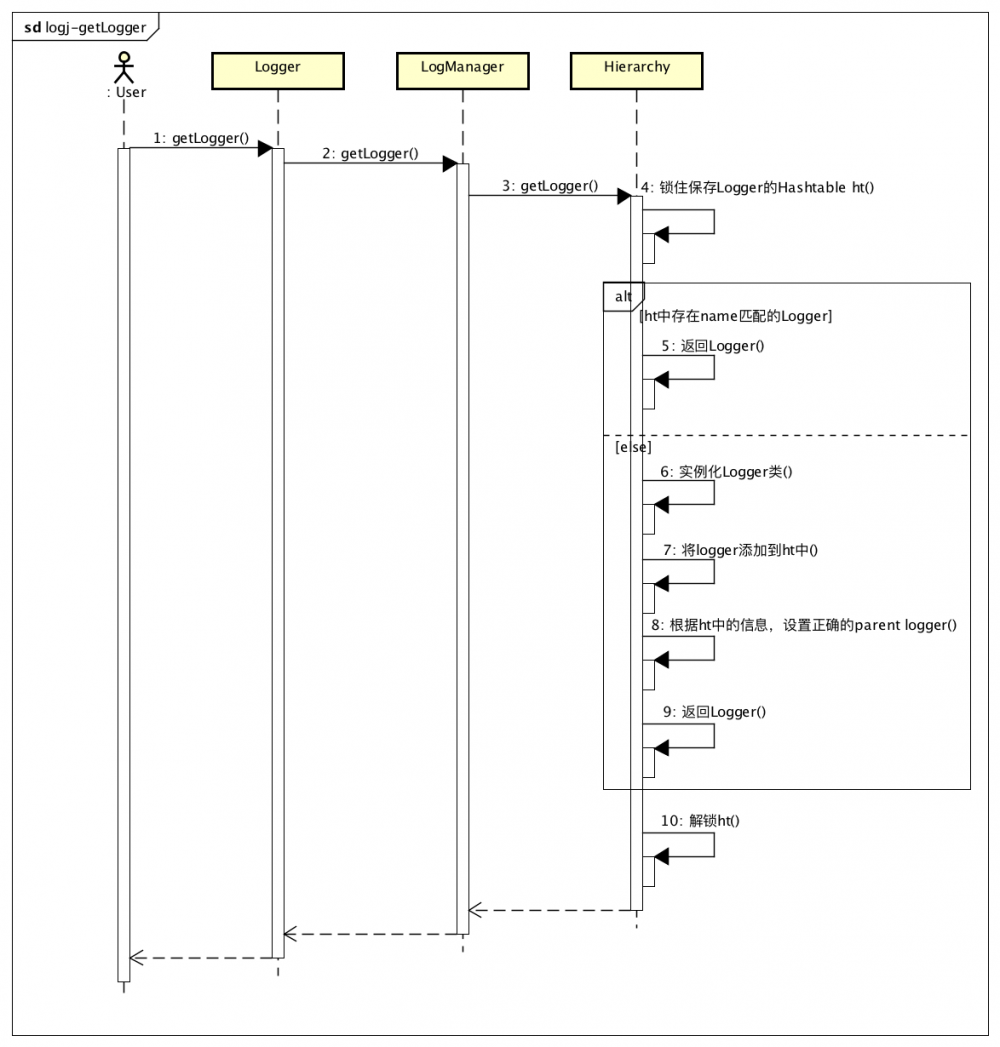
// org.apache.log4j.LogManager#getLogger(java.lang.Class)
public static Logger getLogger(final Class clazz) {
// 获取日志仓库,通过日志仓库获取Logger
return getLoggerRepository().getLogger(clazz.getName());
}
// org.apache.log4j.Hierarchy#getLogger(java.lang.String, org.apache.log4j.spi.LoggerFactory)
public Logger getLogger(String name, LoggerFactory factory) {
// 保存在Hashtable中的Key对象
CategoryKey key = new CategoryKey(name);
Logger logger;
// 获取ht的锁,串行化getLogger流程
synchronized (ht) {
Object o = ht.get(key);
if (o == null) {
// 1. Hashtable中没有该Logger,新建Logger
// 新建后的Logger需要关联好其父Logger,
// 如果没有发现父Logger配置,则其父Logger为RootLogger
logger = factory.makeNewLoggerInstance(name);
logger.setHierarchy(this);
ht.put(key, logger);
updateParents(logger);
return logger;
} else if (o instanceof Logger) {
// 2. Hashtable中已经有缓存该Logger,直接返回
return (Logger) o;
} else if (o instanceof ProvisionNode) {
// 3. Hashtable中存在该name的ProvisionNode对象
// ProvisionNode对象是一个占位对象,比如配置了x.y Logger,
// 在初始化这个Logger时,会去寻找x Logger,但是x Logger不存在,
// 这个时候就会新建一个ProvisionNode对象,保存x对应的所有子Logger,
// 如果后续配置上x Logger,则可以通过ProvisionNode中的信息,建立x Logger
// 与所有其子Logger的父子关系
logger = factory.makeNewLoggerInstance(name);
logger.setHierarchy(this);
ht.put(key, logger);
updateChildren((ProvisionNode) o, logger);
updateParents(logger);
return logger;
} else {
// 不会进入的分支
return null;
}
}
}
如果日志文件中配置了 x.y Logger,则在读取配置时,这个Logger就新建好了, Logger.getLogger("x.y") 会直接从Hashtable中获取到。如果 Logger.getLogger("x.y.z") ,则会新建这个Logger,并设置Parent Logger为 x.y ,然后返回。
Log4j打印日志的流程
Log4j打印日志一般是使用具体的日志级别方法,比如 logger.debug("hello") ,这背后是什么流程呢?
public void debug(Object message) {
// 判断全局日志级别,全局日志级别由配置项log4j.threshold设置
if (repository.isDisabled(Level.DEBUG_INT))
return;
// 判断该Logger的日志级别,如果该Logger没有设置level,则查询父Logger的level,直到RootLogger
if (Level.DEBUG.isGreaterOrEqual(this.getEffectiveLevel())) {
forcedLog(FQCN, Level.DEBUG, message, null);
}
}
protected void forcedLog(String fqcn, Priority level, Object message, Throwable t) {
callAppenders(new LoggingEvent(fqcn, this, level, message, t));
}
public void callAppenders(LoggingEvent event) {
int writes = 0;
// 遍历处理该Logger,与其父Logger
for (Category c = this; c != null; c = c.parent) {
synchronized (c) {
if (c.aai != null) {
// 调用Logger关联的所有Appender进行输出
writes += c.aai.appendLoopOnAppenders(event);
}
// 如果设置additivity=false,则不会调用父Logger!
if (!c.additive) {
break;
}
}
}
if (writes == 0) {
repository.emitNoAppenderWarning(this);
}
}
Logger除了本身输出日志,还会调用父Logger进行输出,同时一些属性如果子Logger没有设置,也会使用父Logger的配置,Log4j官方的一张图片表示了这个关系:
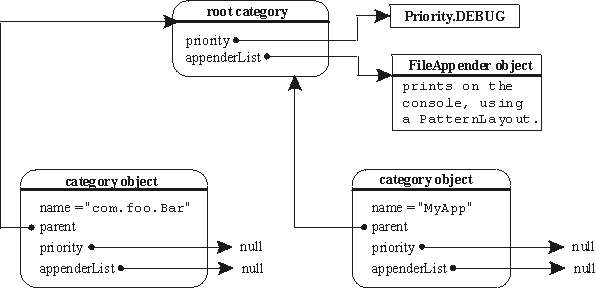
上面代码可以看到重要配置项 additivity 的作用,如果 additivity=true ,也就是默认不配置时的效果,Logger的所有父Logger都会进行输出,如果 additivity=false ,则处理完这个Logger,就直接返回了。
日志输出的任务是交给Appender来处理的,我们这里以常用的FileAppender为例子。从前文的类图中可以看出FileAppender继承于WriterAppender。FileAppender的输出使用WriterAppender的实现:
public class WriterAppender extends AppenderSkeleton {
protected QuietWriter qw;
// 每次输出日志,是否调用Writer的flush方法。默认是每次都会调用
protected boolean immediateFlush = true;
protected void subAppend(LoggingEvent event) {
// 使用layout格式化消息,然后调用Writer的write方法输出日志
this.qw.write(this.layout.format(event));
// 判断是否设置了每次都调用flush方法,如果设置了,则调用flush方法
if (shouldFlush(event)) {
this.qw.flush();
}
}
}
WriterAppender的逻辑很直接,就是调用Writer的wter方法,然后根据配置判断是否需要跟着调用flush方法,默认情况下是每次都会调用flush的,也就是说,默认情况下,我们不用担心日志被Java框架层的缓存缓存住而导致刷新到文件中的时间较为滞后。
public class FileAppender extends WriterAppender {
// 是否使用缓冲IO,默认为false
protected boolean bufferedIO = false;
public synchronized void setFile(String fileName, boolean append, boolean bufferedIO, int bufferSize)
throws IOException {
// 如果使用缓冲IO,就不需要每次flush
if (bufferedIO) {
setImmediateFlush(false);
}
reset();
FileOutputStream ostream = null;
try {
ostream = new FileOutputStream(fileName, append);
} catch (FileNotFoundException ex) {
// ...
}
// 用FileOutputStream新建Writer,核心逻辑是new OutputStreamWriter()
Writer fw = createWriter(ostream);
// 如果配置指定要使用缓冲IO,则使用BufferedWriter进行内存缓冲
if (bufferedIO) {
fw = new BufferedWriter(fw, bufferSize);
}
this.setQWForFiles(fw);
this.fileName = fileName;
this.fileAppend = append;
this.bufferedIO = bufferedIO;
this.bufferSize = bufferSize;
writeHeader();
}
}
根据上面的分析,我们得出以下结论:
- FileAppender及其子类,比如我们常用的
RollingFileAppender,DailyRollingFileAppender,会根据配置的文件名新建FileOutputStream,然后进一步新建OutputStreamWriter,后续的日志操作,就是调用Writer.write()进行的 - FileAppender系列Appender,默认没有开启缓冲IO,也就是说不会使用BufferedWriter。可以使用
log4j.appender.{appenderName}.bufferedIO=true配置项来开启缓冲区IO。开启缓冲区IO能提高打印日志的性能,但是会增加日志打印到日志写入文件的延迟。同时有一个需要关注的点是,如果开启缓冲区IO,如果程序异常退出,还未写入操作系统的日志就丢失了。而关闭缓冲IO的情况下,每次写入日志,都会调用操作系统的read系统调用,虽然这会儿日志内容不一定写到硬盘上,可能会存在于操作系统的页缓冲区中,但即使Java程序崩溃,只要操作系统不崩溃,日志是不会丢失的。这一块内容可以结合 Linux/UNIX编程如何保证文件落盘 和 Java如何保证文件落盘? 这两篇文章来学习。
根据以上分析,我们知道了日志打印时,Log4j先判断日志级别是否打开,然后交给Logger配置的Appender来输出日志。Appender先调用配置的Layout格式化日志,然后输出日志到具体的地方。比如FileAppender系列Appender会输出日志到文件,是通过OutputStreamWriter进行输出的。这个过程会在Logger的所有父Logger上进行,除非Logger本身配置了 additivity=false
正文到此结束
- 本文标签: 静态方法 管理 DOM src classpath IO 数据库 Logback CTO key linux message node HashTable 数据 parse final root 图片 grep stream CEO XML Logging tab bug UI category 遍历 锁 apache ORM find 缓存 时间 实例 文章 unix 模型 配置 类图 解析 操作系统 update Property synchronized 代码 Select http 源码 id cat log4j2 App value java 处理器 https
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

