SpringBoot 2.x ShardingSphere分库分表实战
在之前我做项目的时候,数据量比较大,单表千万级别的,需要分库分表,于是在网上搜索这方面的开源框架,最常见的就是mycat,sharding-sphere,最终我选择后者,用它来做分库分表比较容易上手。
二. 简介sharding-sphere
官网地址: shardingsphere.apache.org/
- ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
- ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
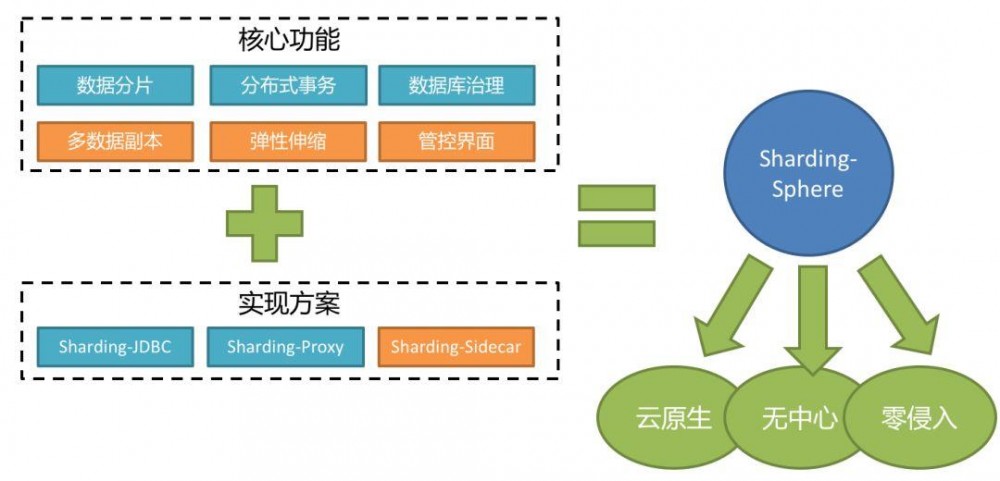
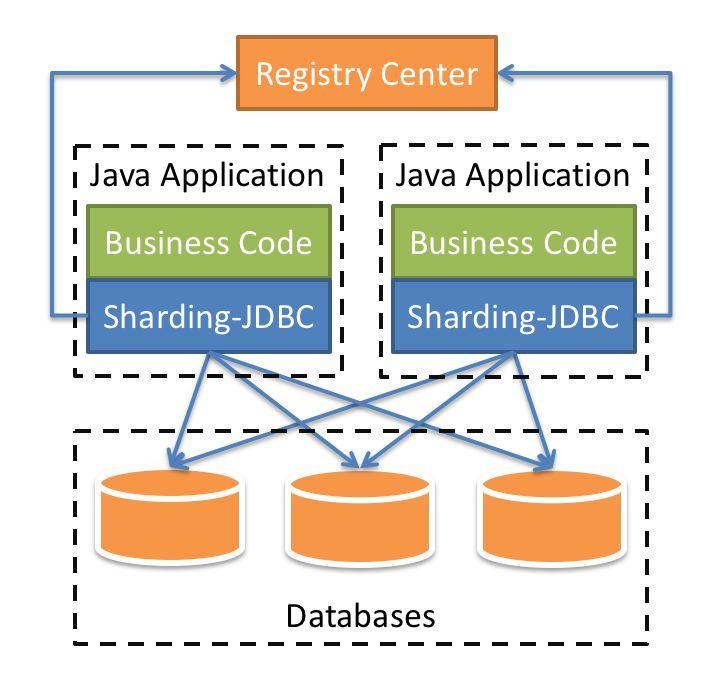
- sharding-jdbc 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
三. 项目实战
本项目基于 Spring Boot 2.1.5 使用sharding-sphere + Mybatis-Plus 实现分库分表
1. pom.xml引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.5.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.xd</groupId>
<artifactId>spring-boot-sharding-table</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-boot-sharding-table</name>
<description>基于 Spring Boot 2.1.5 使用sharding-sphere + Mybatis-Plus 实现分库分表</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--Mybatis-Plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.1</version>
</dependency>
<!--shardingsphere start-->
<!-- for spring boot -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>3.1.0</version>
</dependency>
<!--shardingsphere end-->
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.8</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
复制代码
2. 创建数据库和表
ds0 ├── user_0 └── user_1 ds1 ├── user_0 └── user_1 复制代码
既然是分库分表 库结构与表结构一定是一致的 数据库: ds0
CREATE DATABASE IF NOT EXISTS `ds0` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci */; USE `ds0`; SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for user_0 -- ---------------------------- DROP TABLE IF EXISTS `user_0`; CREATE TABLE `user_0` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- ---------------------------- -- Table structure for user_1 -- ---------------------------- DROP TABLE IF EXISTS `user_1`; CREATE TABLE `user_1` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; SET FOREIGN_KEY_CHECKS = 1; 复制代码
数据库: ds1
CREATE DATABASE IF NOT EXISTS `ds1` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci */; USE `ds1`; SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for user_0 -- ---------------------------- DROP TABLE IF EXISTS `user_0`; CREATE TABLE `user_0` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- ---------------------------- -- Table structure for user_1 -- ---------------------------- DROP TABLE IF EXISTS `user_1`; CREATE TABLE `user_1` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; SET FOREIGN_KEY_CHECKS = 1; 复制代码
3. application.properties (重点)
# 数据源 ds0,ds1
sharding.jdbc.datasource.names=ds0,ds1
# 第一个数据库
sharding.jdbc.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0?characterEncoding=utf-8
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=root
# 第二个数据库
sharding.jdbc.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ds1?characterEncoding=utf-8
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=root
# 水平拆分的数据库(表) 配置分库 + 分表策略 行表达式分片策略
# 分库策略
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{id % 2}
# 分表策略 其中user为逻辑表 分表主要取决于age行
sharding.jdbc.config.sharding.tables.user.actual-data-nodes=ds$->{0..1}.user_$->{0..1}
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.sharding-column=age
# 分片算法表达式
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{age % 2}
# 主键 UUID 18位数 如果是分布式还要进行一个设置 防止主键重复
#sharding.jdbc.config.sharding.tables.user.key-generator-column-name=id
# 打印执行的数据库以及语句
sharding.jdbc.config.props..sql.show=true
spring.main.allow-bean-definition-overriding=true
复制代码
我这次使用配置文件方式实现分库以及分表
以上配置说明:
逻辑表 user
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:用户数据根据主键尾数拆分为2张表,分别是user_0到user_1,他们的逻辑表名为user。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的user_0到user_1
分片算法:
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
分片策略:
行表达式分片策略 对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: user_$->{id % 2} 表示user表根据id模2,而分成2张表,表名称为user_0到user_1。
自增主键生成策略
通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。 采用UUID.randomUUID()的方式产生分布式主键。或者 SNOWFLAKE
4. 实体类
package com.xd.springbootshardingtable.entity;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import groovy.transform.EqualsAndHashCode;
import lombok.Data;
import lombok.experimental.Accessors;
/**
* @Classname User
* @Description 用户实体类
* @Author 李号东 lihaodongmail@163.com
* @Date 2019-05-26 17:24
* @Version 1.0
*/
@Data
@EqualsAndHashCode(callSuper = true)
@Accessors(chain = true)
@TableName("user")
public class User extends Model<User> {
/**
* 主键Id
*/
private int id;
/**
* 名称
*/
private String name;
/**
* 年龄
*/
private int age;
}
复制代码
5. dao层
package com.xd.springbootshardingtable.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.xd.springbootshardingtable.entity.User;
/**
* user dao层
* @author lihaodong
*/
public interface UserMapper extends BaseMapper<User> {
}
复制代码
6. service层以及实现类
UserService
package com.xd.springbootshardingtable.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.xd.springbootshardingtable.entity.User;
import java.util.List;
/**
* @Classname UserService
* @Description 用户服务类
* @Author 李号东 lihaodongmail@163.com
* @Date 2019-05-26 17:31
* @Version 1.0
*/
public interface UserService extends IService<User> {
/**
* 保存用户信息
* @param entity
* @return
*/
@Override
boolean save(User entity);
/**
* 查询全部用户信息
* @return
*/
List<User> getUserList();
}
复制代码
UserServiceImpl
package com.xd.springbootshardingtable.service.Impl;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.xd.springbootshardingtable.entity.User;
import com.xd.springbootshardingtable.mapper.UserMapper;
import com.xd.springbootshardingtable.service.UserService;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @Classname UserServiceImpl
* @Description 用户服务实现类
* @Author 李号东 lihaodongmail@163.com
* @Date 2019-05-26 17:32
* @Version 1.0
*/
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Override
public boolean save(User entity) {
return super.save(entity);
}
@Override
public List<User> getUserList() {
return baseMapper.selectList(Wrappers.<User>lambdaQuery());
}
}
复制代码
####7. 测试控制类
package com.xd.springbootshardingtable.controller;
import com.xd.springbootshardingtable.entity.User;
import com.xd.springbootshardingtable.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* @Classname UserController
* @Description 用户测试控制类
* @Author 李号东 lihaodongmail@163.com
* @Date 2019-05-26 17:36
* @Version 1.0
*/
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/select")
public List<User> select() {
return userService.getUserList();
}
@GetMapping("/insert")
public Boolean insert(User user) {
return userService.save(user);
}
}
复制代码
四. 测试
启动项目
打开浏览器 分别访问:
http://localhost:8080/insert?id=1&name=lhd&age=12 http://localhost:8080/insert?id=2&name=lhd&age=13 http://localhost:8080/insert?id=3&name=lhd&age=14 http://localhost:8080/insert?id=4&name=lhd&age=15 复制代码
则执行插数据 然后查看控制台日志:
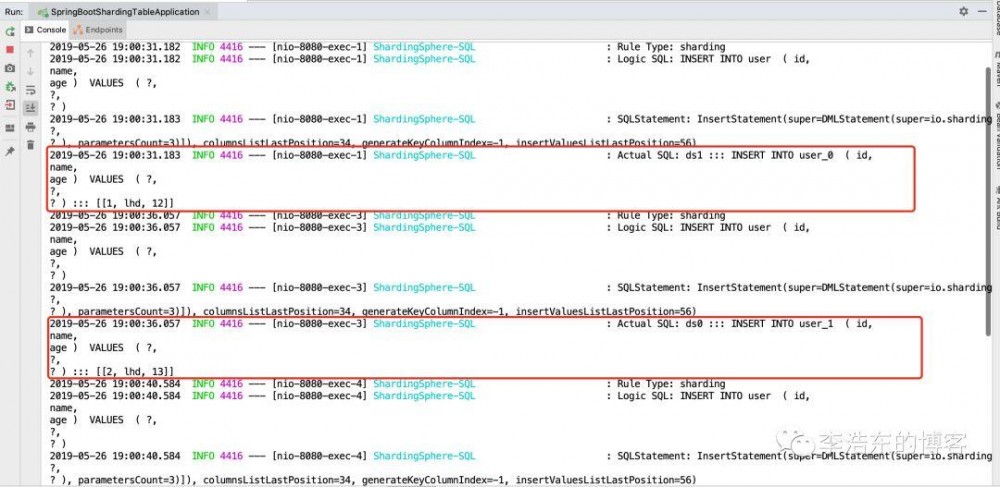
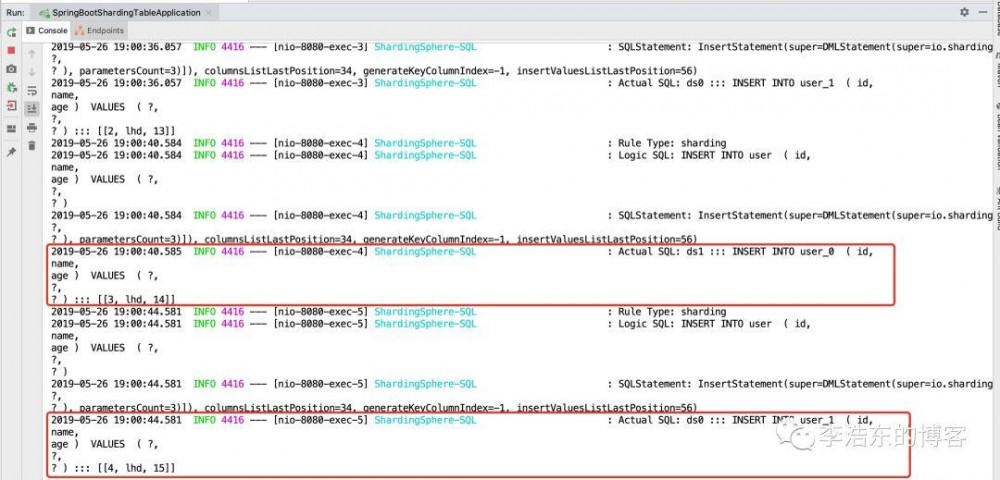
根据分片算法和分片策略 不同的id以及age取模落入不同的库表 达到了分库分表的结果
有的人说 查询的话 该怎么做呢 其实也帮我们做好了 打开浏览器 访问:
http://localhost:8080/select
控制台打印:

分别从ds0数据库两张表和ds1两张表查询结果 然后汇总结果返回给我们
之前有朋友问我单表数据量达千万,想做水平分割,不分库,也可以的吧?
是完全可以的 只要修改配置文件的配置即可 非常灵活
通过代码大家也可以看到,我的业务层代码和平时单表操作是一样的,只需要引入sh配置和逻辑表保持现有的不便即可,使用无侵入我们的代码 可以在原有的基础上改动即可 可以说是非常方便
后面更新如何读写分离以及分库分表结合使用
项目地址: github.com/LiHaodong88…

正文到此结束
- 本文标签: 2019 https dataSource map ACE DOM id apache Proxy mail 开发 数据库 entity IDE 业务层 key 本质 tab 部署 git C3P0 NOSQL Word App IO java JDBC pom dependencies Oracle src 数据 bean XML springboot 测试 rand struct DBCP sql http CTO plugin spring maven mybatis 连接池 description build UI Service 分布式事务 分布式 root druid ip 开源 cat 颠覆 代码 mapper 云 db REST equals tar schema 配置 JPA Select Spring Boot web lambda 总结 产品 core GitHub ORM mysql node list sharding
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

