快速使用组件-spring batch(3)读文件数据到数据库
上一篇文章 《快速了解组件-spring batch(2)之helloworld》 对 Spring Batch 进行了入门级的开发,也对基本的组件有了一定的了解。但实际开发过程中,更多的是涉及文件及数据库的操作,以定时后台运行的方式,实现批处理操作。典型操作是从文本数据( csv/txt 等文件)中读取数据,然后写入到数据库存储。如下图所示:
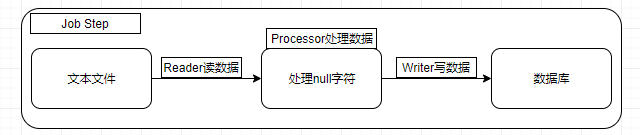
若需要开发此过程,可以按照上一篇文章所写的,自定义 ItemReader 和 ItemWriter 来实现,但是 Spring Batch 其实已经提供现成的文件读取和数据库写入的组件,开发人员可以直接使用,提高开发效率。本文将会对文件读取和数据库写入进行实战介绍。
2.开发环境
- JDK: jdk1.8
- Spring Boot: 2.1.4.RELEASE
- Spring Batch:4.1.2.RELEASE
- 开发IDE: IDEA
- 构建工具Maven: 3.3.9
- 日志组件logback:1.2.3
- lombok:1.18.6
3.Spring Batch提供的读-处理-写组件一览
在使用 Spring Batch 内置的读写组件时,首先我们先弄清楚有哪些组件可以用,按读、写、处理,见下面说明。 Spring Batch 已提供了比较全面的支持。
3.1 ItemReader
| ItemReader | 说明 |
|---|---|
| ListItemReader | 读取List类型数据,只能读一次 |
| ItemReaderAdapter | ItemReader适配器,可以复用现有的读操作 |
| FlatFileItemReader | 读Flat类型文件 |
| StaxEventItemReader | 读XML类型文件 |
| JdbcCursorItemReader | 基于JDBC游标方式读数据库 |
| HibernateCursorItemReader | 基于Hibernate游标方式读数据库 |
| StoredProcedureItemReader | 基于存储过程读数据库 |
| JpaPagingItemReader | 基于Jpa方式分页读数据库 |
| JdbcPagingItemReader | 基于JDBC方式分页读数据库 |
| HibernatePagingItemReader | 基于Hibernate方式分页读取数据库 |
| JmsItemReader | 读取JMS队列 |
| IteratorItemReader | 迭代方式的读组件 |
| MultiResourceItemReader | 多文件读组件 |
| MongoItemReader | 基于分布式文件存储的数据库 MongoDB读组件 |
| Neo4jItemReader | 面向网络的数据库Neo4j的读组件 |
| ResourcesItemReader | 基于批量资源的读组件,每次读取返回资源对象 AmqpItemReader读取AMQP队列组件 |
| RepositoryItemReader | 基于 Spring Data的读组件 |
3.2 ItemWriter
| ItemWriter | 说明 |
|---|---|
| FlatFileItemWriter | 写Flat类型文件 |
| MultiResourceItemWriter | 多文件写组件 |
| StaxEventItemWriter | 写XML类型文件 |
| AmqpItemWriter | 写AMQP类型消息 |
| ClassifierCompositeItemWriter | 根据 Classifier路由不同的Item到特定的ItemWriter处理 |
| HiberateItemWriter | 基于Hibernate方式写数据库 |
| ItemWriterAdapter | ItemWriter适配器,可以复用现有的写服务 |
| JdbcBatchItemWriter | 基于JDBC方式写数据库 |
| JmsItemWriter | 写JMS队列 JpaItemWriter基于Jpa方式写数据库 |
| GemfireItemWriter | 基于分布式数据库Gemfire的写组件 |
| SpELMappingGemfireItemWriter | 基于Spring表达式语言写分布式数据库Gemfire的写组件 |
| MimeMessageItemWriter | 发送邮件的写组件 |
| MongoItemWriter | 基于分布式文件存储的数据库MongoDB写组件 |
| Neo4jItemWriter | 面向网络的数据库Neo4j的读组件 |
| PropertyExtractingDelegatingItemWriter | 属性抽取代理写组件:通过调用给定的 Spring Bean方法执行写入,参数由Item中指定的属性字段获取作为参数 |
| RepositoryItemWriter基于 | Spring Data的写组件 |
| SimpleMailMessageItemWriter | 发送邮件的写组件 |
| CompositeItemWriter | 条目写的组合模式,支持组装多个ItemWriter |
3.3 ItemProcessor
| ItemProcessor | 说明 |
|---|---|
| CompositeItemProcessor | 组合处理器,可以封装多个业务处理服务 |
| ItemProcessorAdapter | ItemProcessor适配器,可以复用现有的业务处理服务 |
| PassThroughItemProcessor | 不做任何业务处理,直接返回读到的数据 |
| ValidatingItemProcessor | 数据校验处理器,支持对数据的校验,如果校验不通过可以进行过滤掉或者通过skip的方式跳过对记录的处理 |
4.开发流程
根据当前示例,从 csv 文件中读数据,写入到 mysql 数据库,只需要使用 FlatFileItemReader 和 JdbcBatchItemWriter 即可。下面对开发流程作简要说明。示例工程可以在 这里获取 ,里面有文件 resources/user-data.csv 及相应的目标数据库脚本 mytest.sql 。
4.1 创建spring batch数据库
4.1.1 创建数据库并执行sql脚本
Spring Batch 的运行需要数据库的支持,以保存任务的运行状态及结果。因此需要先创建数据库。在 mysql 中创建名为 my_spring_batch 的数据库。并在此数据库中执行 Spring Batch 的数据库脚本,脚本位置在 spring-batch-core-4.1.2.RELEASE.jar 的jar包中的 /org/springframework/batch/core/schema-mysql.sql (也可以在 示例工程 的 sql 文件夹中获取)。执行完成后,数据库表如下图所示:
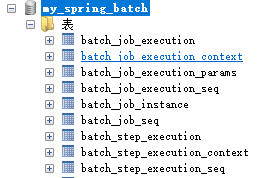
4.1.2 数据库表说明
数据库共9张表,以 seq 结尾的是用于生成主键的。其它6张表,以 batch_job 开头的是存储任务的相关信息, batch_step 开头的存储步骤相关信息。
-
job与job instance与job execution关系 任务job是我们说的逻辑概念,即完整的一个批处理工作,它的实例就是job instance,此任务信息是存储在batch_job_instance表中。有点类似java中的类和类实例的概念,是一对多的关系。对于每一个job instance,执行的时候会生成记录存储在batch_job_execution中,表示每一个job执行的实际情况。注意,这里job instance和job execution也是一对多的关系,即同一个实例有可能会执行多次(如上一次执行失败了,后面重新再执行)。 -
batch_job_execution_context及batch_job_execution_params存储任务执行时需要用到的上下文(以json格式存储)及运行时使用的参数。 -
batch_step_execution及batch_step_execution_context存储任务执行过程中的作业步骤及运行时上下文。
4.1.3 创建示例目标数据库
本示例只涉及一个 test_user 表。创建 mytest 数据库库,执行 mytest.sql 脚本即可。
4.2 配置多数据源
一般来说,我们会把 Spring Batch 的数据存储在独立的数据库中,而实际的应用使用的则是目标数据库,因此需要配置多数据源访问。基于上一篇文章的工程进行开发。
4.2.1 添加mysql数据库依赖
<!-- 数据库相关依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> 复制代码
4.2.2 配置多数据源访问
Spring Boot 对多数据源的支持比较友好,配置也很简单,先在配置文件中添加数据库配置,然后在java配置文件中添加相应的注解即可。如下:
-
application.properties配置内容
# spring batch db spring.datasource.jdbc-url=jdbc:mysql://localhost:3310/my_spring_batch?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&useSSL=false spring.datasource.username=root spring.datasource.password=111111 # target db spring.target-datasource.jdbc-url=jdbc:mysql://localhost:3310/mytest?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&useSSL=false spring.target-datasource.username=root spring.target-datasource.password=111111 复制代码
-
DataSourceConfig配置内容 新建DataSourceConfig.java文件,配置多数据源,如下:
@Configuration
public class DataSourceConfig {
@Bean("datasource")
@ConfigurationProperties(prefix="spring.datasource")
@Primary
public DataSource batchDatasource() {
return DataSourceBuilder.create().build();
}
@Bean("targetDatasource")
@ConfigurationProperties(prefix="spring.target-datasource")
public DataSource targetDatasource() {
return DataSourceBuilder.create().build();
}
}
复制代码
这样,后面就可以直接使用 datasource 及 targetDatasource 两个Bean进行数据库访问。
4.3 添加User实体
本实例中,读取 csv 文件,转为 User 实体,然后存储到数据库,因此需要先把 User 这个实体作一个定义。使用了 lombok 和 jpa 的注解,如下:
@Entity
@Data
@Table(name="test_user")
public class User{
@Id
@GeneratedValue
/**
* id
*/
private Long id;
/**
* 姓名
*/
private String name;
/**
* 手机号
*/
private String phone;
...略
复制代码
4.4 添加文件读取组件ItemReader
使用内置的 FlatFileItemReader 即可。如下:
@Bean
public ItemReader file2DbItemReader(){
String funcName = Thread.currentThread().getStackTrace()[1].getMethodName();
return new FlatFileItemReaderBuilder<User>()
.name(funcName)
.resource(new ClassPathResource("user-data.csv"))
// .linesToSkip(1)
.delimited()
.names(new String[]{"id","name","phone","title","email","gender","date_of_birth","sys_create_time","sys_create_user","sys_update_time","sys_update_user"})
.fieldSetMapper(new UserFieldSetMapper())
.build();
}
复制代码
说明:
-
FlatFileItemReaderBuilder用于创建FlatFileItemReader,设置相应的行为,包括使用它来设置读取文件的位置(resource),文件分隔符(默认是','),是否跳过前面几行(linesToSkip),标识每一列对应的列名称(可与数据库的字段名一致)。设置文件字段与数据库实体字段的对应关系。 - 设置文件字段与数据库实体字段的对应关系,使用
FieldSetMapper来实现,其中FieldSet代表每一行文本数据,返回值即为实体对象。如下所示:
public class UserFieldSetMapper implements FieldSetMapper<User> {
@Override
public User mapFieldSet(FieldSet fieldSet) throws BindException {
String patternYmd = "yyyy-MM-dd";
String patternYmdHms = "yyyy-MM-dd HH:mm:ss";
User user = new User();
user.setId(fieldSet.readLong("id"));
user.setName(fieldSet.readString("name"));
user.setPhone(fieldSet.readString("phone"));
user.setTitle(fieldSet.readString("title"));
user.setEmail(fieldSet.readString("email"));
user.setGender(fieldSet.readString("gender"));
//此字段有可能为null
String dataOfBirthStr = fieldSet.readString("date_of_birth");
if(SyncConstants.STR_CSV_NULL.equals(dataOfBirthStr)){
user.setDateOfBirth(null);
}else{
DateTime dateTime = DateUtil.parse(dataOfBirthStr, patternYmd);
user.setDateOfBirth(dateTime.toJdkDate());
}
user.setSysCreateTime(fieldSet.readDate("sys_create_time",patternYmdHms));
user.setSysCreateUser(fieldSet.readString("sys_create_user"));
user.setSysUpdateTime(fieldSet.readDate("sys_update_time",patternYmdHms));
user.setSysUpdateUser(fieldSet.readString("sys_update_user"));
return user;
}
}
复制代码
4.5 添加处理组件ItemProcessor
由于 csv 文本文件中的数据 null 值数据标识符为 /N ,因此可以在处理组件中进行处理,把标识符 /N 设置为 null 值。如下所示:
@Slf4j
public class File2DbItemProcessor implements ItemProcessor<User,User> {
@Override
public User process(User user) throws Exception {
user.setPhone(checkStr(user.getPhone()));
user.setTitle(checkStr(user.getTitle()));
user.setEmail(checkStr(user.getEmail()));
user.setGender(checkStr(user.getGender()));
log.info(LogConstants.LOG_TAG + "item process: " +user.getName());
return user;
}
public String checkStr(String dataToCheck){
if(SyncConstants.STR_CSV_NULL.equals(dataToCheck)){
return null;
}
return dataToCheck;
}
}
复制代码
4.6 添加数据库写入组件ItemWriter
数据库写入组件使用 JdbcBatchItemWriter 即可,如下:
@Bean
public ItemWriter file2DbWriter(@Qualifier("targetDatasource") DataSource datasource){
return new JdbcBatchItemWriterBuilder<User>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO test_user(id,name,phone,title,email,gender,date_of_birth,sys_create_time,sys_create_user,sys_update_time,sys_update_user) " +
"VALUES (:id,:name,:phone,:title,:email,:gender,:dateOfBirth,:sysCreateTime,:sysCreateUser,:sysUpdateTime,:sysUpdateUser)")
.dataSource(datasource)
.build();
}
复制代码
说明:
- 使用
JdbcBatchItemWriterBuilder进行JdbcBatchItemWriter的创建,设置插入数据库的sql语句,同时指定数据源即可。 -
@Qualifier("targetDatasource") DataSource datasource用于指定数据源 - 使用
BeanPropertyItemSqlParameterSourceProvider可以直接把读取的数据实体的属性数据作为参数填充到sql语句中,从而实现数据插入操作。
4.7 组装完整任务
经过上面的操作,可以使用一个java配置,把读、写、处理组装成完整的 step 和 job ,如下所示(详细可见示例工程文件):
File2DbBatchConfig.java
@Bean
public Job file2DbJob(Step file2DbStep,JobExecutionListener file2DbListener){
String funcName = Thread.currentThread().getStackTrace()[1].getMethodName();
return jobBuilderFactory.get(funcName)
.listener(file2DbListener)
.flow(file2DbStep)
.end().build();
}
@Bean
public Step file2DbStep(ItemReader file2DbItemReader , ItemProcessor file2DbProcessor
,ItemWriter file2DbWriter){
String funcName = Thread.currentThread().getStackTrace()[1].getMethodName();
return stepBuilderFactory.get(funcName)
.<User,User>chunk(10)
.reader(file2DbItemReader)
.processor(file2DbProcessor)
.writer(file2DbWriter)
.build();
}
复制代码
4.8 编写测试
参考上一文章的 ConsoleJobTest ,编写 File2DbJobTest 文件。
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {MainBootApplication.class,File2DbBatchConfig.class})
@Slf4j
public class File2DbJobTest {
@Autowired
private JobLauncherService jobLauncherService;
@Autowired
private Job file2DbJob;
@Test
public void testFile2DbJob() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
//构建任务运行参数
JobParameters jobParameters = JobUtil.makeJobParameters();
//执行并显示结果
Map<String, Object> stringObjectMap = jobLauncherService.startJob(file2DbJob, jobParameters);
Assert.assertEquals(ExitStatus.COMPLETED,stringObjectMap.get(SyncConstants.STR_RETURN_EXITSTATUS));
}
}
复制代码
执行后结果输出如下( exitCode=COMPLETED ):
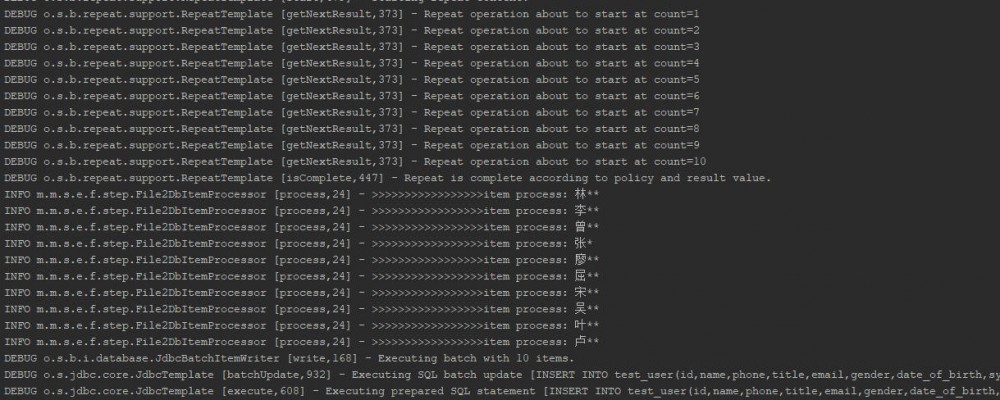
正文到此结束
- 本文标签: springboot 测试 参数 Logback js entity 数据 Job IO spring XML amqp maven DBCP cat ACE App Property 分布式 ssl 分页 适配器 https src UI JPA mapper 游标 json 数据库访问 db provider 数据库 Word CTO 处理器 Spring Boot root REST Qualifier git build 配置 Spring Batch bean mysql 实例 mongo tab 开发 GMT tar http 代码 message id update list JDBC ip schema map 文章 parse constant Mysql数据库 classpath 一对多 tag core IDE JMS MQ java value equals mail dataSource sql 1111 MongoDB Service
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

