AbstractQueuedSynchronizer 原理分析
AQS ,AbstractQueuedSynchronizer ,即队列同步器。它是构建锁或者其他同步组件的基础框架(如 ReentrantLock、ReentrantReadWriteLock、Semaphore 等),J.U.C 并发包的作者(Doug Lea)期望它能够成为实现大部分同步需求的基础。
它是 J.U.C 并发包中的核心基础组件。
AQS 优势
AQS 解决了在实现同步器时涉及当的大量细节问题,例如获取同步状态、FIFO 同步队列。
基于 AQS 来构建同步器可以带来很多好处。它不仅能够极大地减少实现工作,而且也不必处理在多个位置上发生的竞争问题。
在基于 AQS 构建的同步器中,只能在一个时刻发生阻塞,从而降低上下文切换的开销,提高了吞吐量。同时在设计 AQS 时充分考虑了可伸缩性,因此 J.U.C 中,所有基于 AQS 构建的同步器均可以获得这个优势。
同步状态
AQS 的主要使用方式是继承,子类通过继承同步器,并实现它的抽象方法来管理同步状态。
AQS 使用一个 int 类型的成员变量 state 来表示同步状态:
当 state > 0 时,表示已经获取了锁。 当 state = 0 时,表示释放了锁。 复制代码
它提供了三个方法,来对同步状态 state 进行操作,并且 AQS 可以确保对 state 的操作是安全的:
#getState() #setState(int newState) #compareAndSetState(int expect, int update) 复制代码
同步队列
AQS 通过内置的 FIFO 同步队列来完成资源获取线程的排队工作:
如果当前线程获取同步状态失败(锁)时,AQS 则会将当前线程以及等待状态等信息构造成一个节点(Node)并将其加入同步队列,同时会阻塞当前线程 当同步状态释放时,则会把节点中的线程唤醒,使其再次尝试获取同步状态。
主要内置方法
AQS 主要提供了如下方法:
- #getState():返回同步状态的当前值
- #setState(int newState):设置当前同步状态。
- #compareAndSetState(int expect, int update):使用 CAS 设置当前状态,该方法能够保证状态设置的原子性。
- 【可重写】#tryAcquire(int arg):独占式获取同步状态,获取同步状态成功后,其他线程需要等待该线程释放同步状态才能获取同步状态。
- 【可重写】#tryRelease(int arg):独占式释放同步状态。
- 【可重写】#tryAcquireShared(int arg):共享式获取同步状态,返回值大于等于 0 ,则表示获取成功;否则,获取失败。
- 【可重写】#tryReleaseShared(int arg):共享式释放同步状态。
- 【可重写】#isHeldExclusively():当前同步器是否在独占式模式下被线程占用,一般该方法表示是否被当前线程所独占。
- acquire(int arg):独占式获取同步状态。如果当前线程获取同步状态成功,则由该方法返回;否则,将会进入同步队列等待。该方法将会调用可重写的 #tryAcquire(int arg) 方法;不响应中断
- #acquireInterruptibly(int arg):与 #acquire(int arg) 相同,但是该方法响应中断。当前线程为获取到同步状态而进入到同步队列中,如果当前线程被中断,则该方法会抛出InterruptedException 异常并返回。
- #tryAcquireNanos(int arg, long nanos):超时获取同步状态。如果当前线程在 nanos 时间内没有获取到同步状态,那么将会返回 false ,已经获取则返回 true 。
- #acquireShared(int arg):共享式获取同步状态,如果当前线程未获取到同步状态,将会进入同步队列等待,与独占式的主要区别是在同一时刻可以有多个线程获取到同步状态;
- #acquireSharedInterruptibly(int arg):共享式获取同步状态,响应中断。
- #tryAcquireSharedNanos(int arg, long nanosTimeout):共享式获取同步状态,增加超时限制。
- #release(int arg):独占式释放同步状态,该方法会在释放同步状态之后,将同步队列中第一个节点包含的线程唤醒。
- #releaseShared(int arg):共享式释放同步状态。
从上面的方法看下来,基本上可以分成 3 类:
独占式获取与释放同步状态 共享式获取与释放同步状态 查询同步队列中的等待线程情况 复制代码
CLH 同步队列
CLH简介
CLH 同步队列是一个 FIFO 双向队列,AQS 依赖它来完成同步状态的管理:
当前线程如果获取同步状态失败时,AQS则会将当前线程已经等待状态等信息构造成一个节点(Node)并将其加入到CLH同步队列,同时会阻塞当前线程
当同步状态释放时,会把首节点唤醒(公平锁),使其再次尝试获取同步状态。
Node
Node 是 AbstractQueuedSynchronizer 的内部静态类。
static final class Node {
// 共享
static final Node SHARED = new Node();
// 独占
static final Node EXCLUSIVE = null;
/**
* 因为超时或者中断,节点会被设置为取消状态,被取消的节点时不会参与到竞争中的,他会一直保持取消状态不会转变为其他状态
*/
static final int CANCELLED = 1;
/**
* 后继节点的线程处于等待状态,而当前节点的线程如果释放了同步状态或者被取消,将会通知后继节点,使后继节点的线程得以运行
*/
static final int SIGNAL = -1;
/**
* 节点在等待队列中,节点线程等待在Condition上,当其他线程对Condition调用了signal()后,该节点将会从等待队列中转移到同步队列中,加入到同步状态的获取中
*/
static final int CONDITION = -2;
/**
* 表示下一次共享式同步状态获取,将会无条件地传播下去
*/
static final int PROPAGATE = -3;
/** 等待状态 */
volatile int waitStatus;
/** 前驱节点,当节点添加到同步队列时被设置(尾部添加) */
volatile Node prev;
/** 后继节点 */
volatile Node next;
/** 等待队列中的后续节点。如果当前节点是共享的,那么字段将是一个 SHARED 常量,也就是说节点类型(独占和共享)和等待队列中的后续节点共用同一个字段 */
Node nextWaiter;
/** 获取同步状态的线程 */
volatile Thread thread;
final boolean isShared() {
return nextWaiter == SHARED;
}
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
复制代码
- waitStatus 字段
等待状态,用来控制线程的阻塞和唤醒,并且可以避免不必要的调用LockSupport的 #park(...) 和 #unpark(...) 方法。。目前有 4 种:CANCELLED SIGNAL CONDITION PROPAGATE 。实际上,有第 5 种,INITAL ,值为 0 ,初始状态。每个等待状态代表的含义,它不仅仅指的是 Node 自己的线程的等待状态, 也可以是下一个节点的线程的等待状态 。
- CLH 同步队列
head 和 tail 字段,是 AbstractQueuedSynchronizer 的字段,分别指向同步队列的头和尾。再配合上 prev 和 next 字段,快速定位到同步队列的头尾。
prev 和 next 字段,分别指向 Node 节点的前一个和后一个 Node 节点,从而实现链式双向队列。
-
thread 字段,Node 节点对应的线程 Thread 。
-
nextWaiter 字段,Node 节点获取同步状态的模型( Mode )。#tryAcquire(int args) 和 #tryAcquireShared(int args) 方法,分别是独占式和共享式获取同步状态。在获取失败时,它们都会调用 #addWaiter(Node mode) 方法入队。而 nextWaiter 就是用来表示是哪种模式:
SHARED 静态 + 不可变字段,枚举共享模式。 EXCLUSIVE 静态 + 不可变字段,枚举独占模式。 #isShared() 方法,判断是否为共享式获取同步状态。 复制代码
-
#predecessor() 方法,获得 Node 节点的前一个 Node 节点。在方法的内部,Node p = prev 的本地拷贝,是为了避免并发情况下,prev 判断完 == null 时,恰好被修改,从而保证线程安全。
-
构造方法有 3 个,分别是:
#Node() 方法:用于 SHARED 的创建。 #Node(Thread thread, Node mode) 方法:用于 #addWaiter(Node mode) 方法。 从 mode 方法参数中,我们也可以看出它代表获取同步状态的模式。 #Node(Thread thread, int waitStatus) 方法,用于 #addConditionWaiter() 方法。 复制代码
入列
CLH 队列入列很简单: tail 指向新节点。 新节点的 prev 指向当前最后的节点。 当前最后一个节点的 next 指向当前节点。
但是,实际上,入队逻辑实现的 #addWaiter(Node) 方法,需要考虑并发的情况。它通过 CAS 的方式,来保证正确的添加 Node 。代码如下:
private Node addWaiter(Node mode) {
// 新建节点
Node node = new Node(Thread.currentThread(), mode);
// 记录原尾节点
Node pred = tail;
// 快速尝试,添加新节点为尾节点
//当原尾节点非空,才执行快速尝试的逻辑. 在下面的 #enq(Node node) 方法中,我们会看到,首节点未初始化的时,head 和 tail 都为空。
if (pred != null) {
// 设置新 Node 节点的尾节点为原尾节点
node.prev = pred;
// CAS 设置新的尾节点
if (compareAndSetTail(pred, node)) {
// 成功,原尾节点的下一个节点为新节点
pred.next = node;
return node;
}
}
// 失败,多次尝试,直到成功
enq(node);
return node;
}
复制代码
- 创建新节点 node 。在创建的构造方法,mode 方法参数,传递获取同步状态的模式。
- 记录原尾节点 tail 。
- 快速尝试,添加新节点为尾节点。
- enq添加失败,多次尝试,直到成功添加。
调用 #enq(Node node) 方法,多次尝试,直到成功添加
private Node enq(final Node node) {
// 多次尝试,直到成功为止
for (;;) {
// 记录原尾节点
Node t = tail;
// 原尾节点不存在,创建首尾节点都为 new Node()
if (t == null) {
if (compareAndSetHead(new Node()))
tail = head;
// 原尾节点存在,添加新节点为尾节点
} else {
//设置为尾节点
node.prev = t;
// CAS 设置新的尾节点
if (compareAndSetTail(t, node)) {
// 成功,原尾节点的下一个节点为新节点
t.next = node;
return t;
}
}
}
}
复制代码
- “死”循环,多次尝试,直到成功添加为止
- 记录原尾节点 t 。和 #addWaiter(Node node) 方法的相同。
- 原尾节点存在,添加新节点为尾节点。和 #addWaiter(Node node) 方法的相同。
- 原尾节点不存在,则首节点也不存在了,创建首尾节点都为 new Node() 。
- #compareAndSetHead(Node update) 方法,使用 Unsafe 来 CAS 设置尾节点 head 为新节点。
出列
CLH 同步队列遵循 FIFO,首节点的线程释放同步状态后,将会唤醒它的下一个节点(Node.next)。而后继节点将会在获取同步状态成功时,将自己设置为首节点( head )。
这个过程非常简单,head 执行该节点并断开原首节点的 next 和当前节点的 prev 即可。注意,在这个过程是不需要使用 CAS 来保证的,因为只有一个线程,能够成功获取到同步状态。
setHead(Node node) 方法,实现上述的出列逻辑。代码如下:
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
复制代码
AQS:同步状态的获取与释放
AQS 的设计模式采用的模板方法模式,子类通过继承的方式,实现它的抽象方法来管理同步状态。
对于子类而言,它并没有太多的活要做,AQS 已经提供了大量的模板方法来实现同步,主要是分为三类:
独占式获取和释放同步状态 共享式获取和释放同步状态 查询同步队列中的等待线程情况。 复制代码
自定义子类使用 AQS 提供的模板方法,就可以实现自己的同步语义。
独占式
独占式,同一时刻,仅有一个线程持有同步状态。
独占式同步状态获取
acquire(int arg)
acquire(int arg) 方法,为 AQS 提供的模板方法。该方法为独占式获取同步状态,但是该方法对中断不敏感。也就是说,由于线程获取同步状态失败而加入到 CLH 同步队列中,后续对该线程进行中断操作时,线程不会从 CLH 同步队列中移除。代码如下:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
复制代码
调用 #tryAcquire(int arg) 方法,去尝试获取同步状态,获取成功则设置锁状态并返回 true ,否则获取失败,返回 false 。
若tryAcquire获取成功,则acquire(int arg) 方法直接返回,不用线程阻塞
若 tryAcquire 获取失败调用 addWaiter(Node mode) 方法,将当前线程加入到 CLH 同步队列尾部,并且, mode 方法参数为 Node.EXCLUSIVE ,表示独占模式。然后调用 boolean #acquireQueued(Node node, int arg) 方法,自旋直到获得同步状态成功。
另外,该 acquireQueued 方法的返回值类型为 boolean ,当返回 true 时,表示在这个过程中,发生过线程中断。但是呢,这个方法又会清理线程中断的标识,所以在种情况下,需要调用 #selfInterrupt() 方法,恢复线程中断的标识,代码如下:
static void selfInterrupt() {
Thread.currentThread().interrupt();
}
复制代码
tryAcquire(int arg)
tryAcquire(int arg)方法,需要自定义同步组件自己实现,该方法必须要保证线程安全的获取同步状态。AQS里代码如下:
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
复制代码
直接抛出 UnsupportedOperationException 异常。
acquireQueued
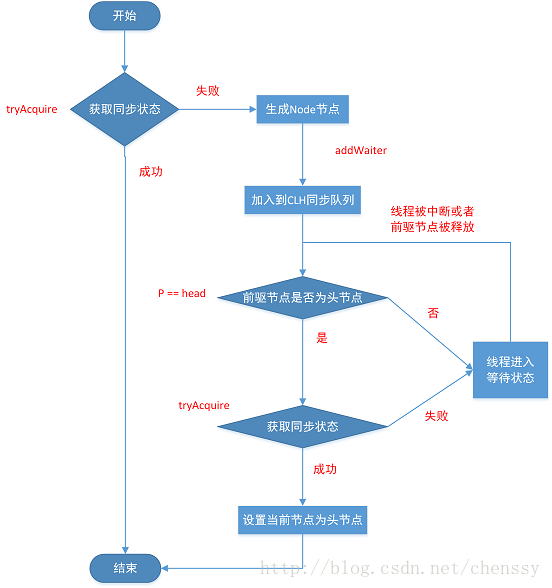
boolean #acquireQueued(Node node, int arg) 方法,为一个自旋的过程,也就是说,当前线程(Node)进入同步队列后,就会进入一个自旋的过程,每个节点都会自省地观察,当条件满足,获取到同步状态后,就可以从这个自旋过程中退出,否则会一直执行下去。
流程图如下:
代码如下:
final boolean acquireQueued(final Node node, int arg) {
// 记录是否获取同步状态成功
boolean failed = true;
try {
// 记录过程中,是否发生线程中断
boolean interrupted = false;
/*
* 自旋过程,其实就是一个死循环而已
*/
for (;;) {
// 当前线程的前驱节点
final Node p = node.predecessor();
// 当前线程的前驱节点是头结点,且同步状态成功
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// 获取失败,线程等待--具体后面介绍
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
// 获取同步状态发生异常,取消获取。
if (failed)
cancelAcquire(node);
}
}
复制代码
- failed 变量,记录是否获取同步状态成功。
- interrupted 变量,记录获取过程中,是否发生线程中断。
- 调用 Node#predecessor() 方法,获得当前线程的前一个节点 p 。
- p == head 代码块,若满足,则表示当前线程的前一个节点为头节点,因为 head 是最后一个获得同步状态成功的节点,此时调用 #tryAcquire(int arg) 方法,尝试获得同步状态
- 当前节点( 线程 )获取同步状态成功:
- 设置当前节点( 线程 )为新的 head 。
- 设置老的头节点 p 不再指向下一个节点,让它自身更快的被 GC 。
- 标记 failed = false ,表示获取同步状态成功。
- 返回记录获取过程中,是否发生线程中断。
- 调用 #shouldParkAfterFailedAcquire(Node pre, Node node) 方法,判断获取失败后,是否当前线程需要阻塞等待。
- 调用 #cancelAcquire(Node node) 方法,取消获取同步状态。
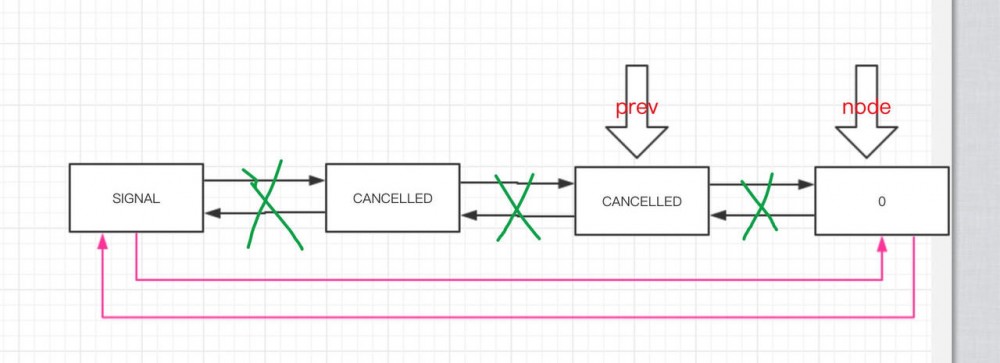
shouldParkAfterFailedAcquire
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获得前一个节点的等待状态
int ws = pred.waitStatus;
if (ws == Node.SIGNAL) // Node.SIGNAL
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
if (ws > 0) { // Node.CANCEL
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else { // 0 或者 Node.PROPAGATE
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
复制代码
- pred 和 node 方法参数,传入时,要求前者必须是后者的前一个节点。
- 获得前一个节点( pre )的等待状态。下面会根据这个状态有三种情况的处理。
- 等待状态为 Node.SIGNAL 时,表示 pred 的下一个节点 node 的线程需要阻塞等待。
- 在 pred 的线程释放同步状态时,会对 node 的线程进行唤醒通知。所以返回 true ,表明当前线程可以被 park,安全的阻塞等待。
- 等待状态为 0 或者 Node.PROPAGATE 时,通过 CAS 设置,将状态修改为 Node.SIGNAL ,即下一次重新执行 #shouldParkAfterFailedAcquire(Node pred, Node node) 方法时,满足条件。但是,对于本次执行,返回 false 。
- 另外,等待状态不会为 Node.CONDITION ,因为它用在 ConditonObject 中。
- 等待状态为 NODE.CANCELLED 时,则表明该线程的前一个节点已经等待超时或者被中断了,则需要从 CLH 队列中将该前一个节点删除掉,循环回溯,直到前一个节点状态 <= 0 。 对于本次执行,返回 false ,需要下一次再重新执行 #shouldParkAfterFailedAcquire(Node pred, Node node) 方法,看看满足哪个条件。
整个过程如下图:
cancelAcquire
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
if (node == null)
return;
node.thread = null;
// Skip cancelled predecessors
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// predNext is the apparent node to unsplice. CASes below will
// fail if not, in which case, we lost race vs another cancel
// or signal, so no further action is necessary.
Node predNext = pred.next;
// Can use unconditional write instead of CAS here.
// After this atomic step, other Nodes can skip past us.
// Before, we are free of interference from other threads.
node.waitStatus = Node.CANCELLED;
// If we are the tail, remove ourselves.
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
// If successor needs signal, try to set pred's next-link
// so it will get one. Otherwise wake it up to propagate.
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
复制代码
-
若传入参数 node 为空。
-
将节点的等待线程置空。
-
获得 node 节点的前一个节点 pred 。
-
获得 pred 的下一个节点 predNext 。predNext 从表面上看,和 node 是等价的。 但是实际上,存在多线程并发的情况,所以我们调用 #compareAndSetNext(...) 方法,使用 CAS 的方式,设置 pred 的下一个节点。 如果设置失败,说明当前线程和其它线程竞争失败,不需要做其它逻辑,因为 pred 的下一个节点已经被其它线程设置成功。
-
设置 node 节点的为取消的等待状态 Node.CANCELLED 。 这里可以使用直接写,而不是 CAS 。 在这个操作之后,其它 Node 节点可以忽略 node 。 Before, we are free of interference from other threads. 如何理解。
-
下面开始开始修改 pred 的新的下一个节点,一共分成三种情况。
- 如果 node 是尾节点,调用 #compareAndSetTail(...) 方法,CAS 设置 pred 为新的尾节点。若上述操作成功,调用 #compareAndSetNext(...) 方法,CAS 设置 pred 的下一个节点为空( null )。
- pred 非首节点。pred 的等待状态为 Node.SIGNAL ,或者可被 CAS 为 Node.SIGNAL 。pred 的线程非空。若 node 的 下一个节点 next 的等待状态非 Node.CANCELLED ,则调用 #compareAndSetNext(...) 方法,CAS 设置 pred 的下一个节点为 next 。
- 如果 pred 为首节点,调用 #unparkSuccessor(Node node) 方法,唤醒 node 的下一个节点的线程等待。为什么此处需要唤醒呢?因为,pred 为首节点,node 的下一个节点的阻塞等待,需要 node 释放同步状态时进行唤醒。但是,node 取消获取同步状态,则不会再出现 node 释放同步状态时进行唤醒 node 的下一个节点。因此,需要此处进行唤醒。
独占式获取响应中断
AQS 提供了acquire(int arg) 方法,以供独占式获取同步状态,但是该方法对中断不响应,对线程进行中断操作后,该线程会依然位于CLH同步队列中,等待着获取同步状态。
为了响应中断,AQS 提供了 #acquireInterruptibly(int arg) 方法。该方法在等待获取同步状态时,如果当前线程被中断了,会立刻响应中断,并抛出 InterruptedException 异常。
public final void acquireInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
复制代码
- 首先,校验该线程是否已经中断了,如果是,则抛出InterruptedException 异常。
- 然后,调用 #tryAcquire(int arg) 方法,尝试获取同步状态,如果获取成功,则直接返回。
- 最后,调用 #doAcquireInterruptibly(int arg) 方法,自旋直到获得同步状态成功,或线程中断抛出 InterruptedException 异常。
doAcquireInterruptibly
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException(); // <1>
}
} finally {
if (failed)
cancelAcquire(node);
}
}
复制代码
它与 #acquire(int arg) 方法仅有两个差别:
-
方法声明抛出 InterruptedException 异常。
-
在中断方法处不再是使用 interrupted 标志,而是直接抛出 InterruptedException 异常。
独占式超时获取
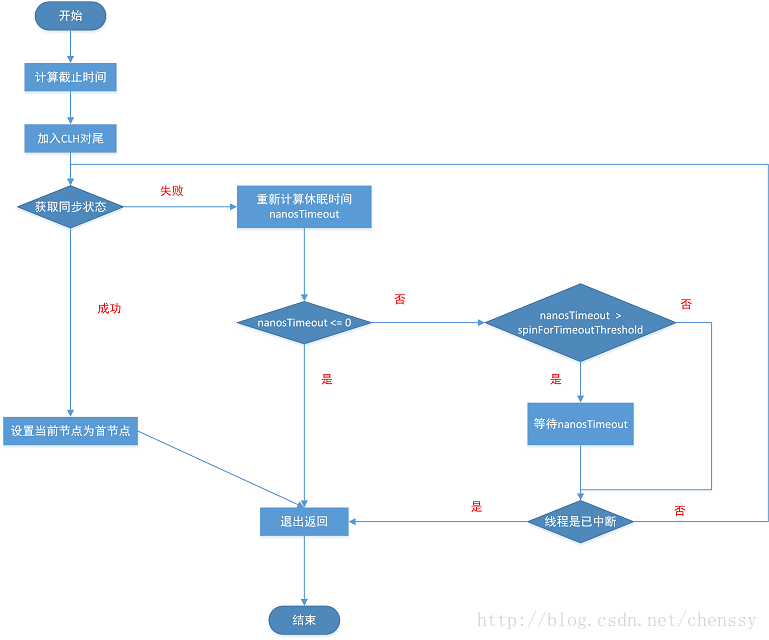
AQS 除了提供上面两个方法外,还提供了一个增强版的方法 #tryAcquireNanos(int arg, long nanos) 。该方法为 #acquireInterruptibly(int arg) 方法的进一步增强,它除了响应中断外,还有超时控制。即如果当前线程没有在指定时间内获取同步状态,则会返回 false ,否则返回 true 。
流程图如下:
代码如下:
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
复制代码
- 首先,校验该线程是否已经中断了,如果是,则抛出InterruptedException 异常。
- 然后,调用 #tryAcquire(int arg) 方法,尝试获取同步状态,如果获取成功,则直接返回。
- 最后,调用 #tryAcquireNanos(int arg) 方法,自旋直到获得同步状态成功,或线程中断抛出 InterruptedException 异常,或超过指定时间返回获取同步状态失败。
tryAcquireNanos
static final long spinForTimeoutThreshold = 1000L;
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
// nanosTimeout <= 0
if (nanosTimeout <= 0L)
return false;
// 超时时间
final long deadline = System.nanoTime() + nanosTimeout;
// 新增 Node 节点
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
// 自旋
for (;;) {
final Node p = node.predecessor();
// 获取同步状态成功
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
/*
* 获取失败,做超时、中断判断
*/
// 重新计算需要休眠的时间
nanosTimeout = deadline - System.nanoTime();
// 已经超时,返回false
if (nanosTimeout <= 0L)
return false;
// 如果没有超时,则等待nanosTimeout纳秒
// 注:该线程会直接从LockSupport.parkNanos中返回,
// LockSupport 为 J.U.C 提供的一个阻塞和唤醒的工具类,后面做详细介绍
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
// 线程是否已经中断了
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
复制代码
因为是在 #doAcquireInterruptibly(int arg) 方法的基础上,做了超时控制的增强,所以相同部分,我们直接跳过。
- 如果超时时间小于 0 ,直接返回 false ,已经超时。
- 计算最终超时时间 deadline 。
- 重新计算剩余可获取同步状态的时间 nanosTimeout 。
- 如果剩余时间小于 0 ,直接返回 false ,已经超时。
- 如果剩余时间大于 spinForTimeoutThreshold ,则调用 LockSupport#parkNanos(Object blocker, long nanos) 方法,休眠 nanosTimeout 纳秒。否则,就不需要休眠了,直接进入快速自旋的过程。原因在于,spinForTimeoutThreshold 已经非常小了,非常短的时间等待无法做到十分精确,如果这时再次进行超时等待,相反会让 nanosTimeout 的超时从整体上面表现得不是那么精确。所以,在超时非常短的场景中,AQS 会进行无条件的快速自旋。
- 若线程已经中断了,抛出 InterruptedException 异常。
独占式同步状态释放
当线程获取同步状态后,执行完相应逻辑后,就需要释放同步状态。AQS 提供了#release(int arg)方法,释放同步状态。代码如下:
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
复制代码
-
调用 #tryRelease(int arg) 方法,去尝试释放同步状态,释放成功则设置锁状态并返回 true ,否则获取失败,返回 false 。
-
tryRelease(int arg) 方法,需要自定义同步组件自己实现,该方法必须要保证线程安全的释放同步状态。代码如下:
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
复制代码
直接抛出 UnsupportedOperationException 异常。 3. 获得当前的 head ,避免并发问题。
-
头结点不为空,并且头结点状态不为 0 ( INITAL 未初始化)。为什么会出现 0 的情况呢?
-
调用 #unparkSuccessor(Node node) 方法,唤醒下一个节点的线程等待。
总结
-
在 AQS 中维护着一个 FIFO 的同步队列。
-
当线程获取同步状态失败后,则会加入到这个 CLH 同步队列的对尾,并一直保持着自旋。
-
在 CLH 同步队列中的线程在自旋时,会判断其前驱节点是否为首节点,如果为首节点则不断尝试获取同步状态,获取成功则退出CLH同步队列。
-
当线程执行完逻辑后,会释放同步状态,释放后会唤醒其后继节点。
共享式
共享式与独占式的最主要区别在于,同一时刻:
独占式只能有一个线程获取同步状态。 共享式可以有多个线程获取同步状态。 复制代码
例如,读操作可以有多个线程同时进行,而写操作同一时刻只能有一个线程进行写操作,其他操作都会被阻塞。例子为 ReentrantReadWriteLock 。
共享式同步状态获取
acquireShared(int arg) 方法,对标 #acquire(int arg) 方法。
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
复制代码
调用 #tryAcquireShared(int arg) 方法,尝试获取同步状态,获取成功则设置锁状态并返回大于等于 0 ,否则获取失败,返回小于 0 。
若获取成功,直接返回,不用线程阻塞,获取失败则自旋直到获得同步状态成功。
tryAcquireShared(int arg) 方法
需要自定义同步组件自己实现,该方法必须要保证线程安全的获取同步状态。代码如下:
protected int tryAcquireShared(int arg) {
throw new UnsupportedOperationException();
}
复制代码
直接抛出 UnsupportedOperationException 异常。
doAcquireShared
private void doAcquireShared(int arg) {
// 共享式节点
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
// 前驱节点
final Node p = node.predecessor();
// 如果其前驱节点,获取同步状态
if (p == head) {
// 尝试获取同步
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
复制代码
因为和 #acquireQueued(int arg) 方法的基础上,所以相同部分,直接跳过。
-
调用 #addWaiter(Node mode) 方法,将当前线程加入到 CLH 同步队列尾部。并且, mode 方法参数为 Node.SHARED ,表示共享模式。
-
调用 #tryAcquireShared(int arg) 方法,尝试获得同步状态。
-
调用 #setHeadAndPropagate(Node node, int propagate) 方法,设置新的首节点,并根据条件,唤醒下一个节点。这里和独占式同步状态获取很大的不同:通过这样的方式,不断唤醒下一个共享式同步状态, 从而实现同步状态被多个线程的共享获取。
setHeadAndPropagate
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
/*
* Try to signal next queued node if:
* Propagation was indicated by caller,
* or was recorded (as h.waitStatus either before
* or after setHead) by a previous operation
* (note: this uses sign-check of waitStatus because
* PROPAGATE status may transition to SIGNAL.)
* and
* The next node is waiting in shared mode,
* or we don't know, because it appears null
*
* The conservatism in both of these checks may cause
* unnecessary wake-ups, but only when there are multiple
* racing acquires/releases, so most need signals now or soon
* anyway.
*/
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
复制代码
- 记录原来的首节点 h 。
- 调用 #setHead(Node node) 方法,设置 node 为新的首节点。
- propagate > 0 代码块,说明同步状态还能被其他线程获取。
- 判断原来的或者新的首节点,等待状态为 Node.PROPAGATE 或者 Node.SIGNAL 时,可以继续向下唤醒。
- 调用 Node#isShared() 方法,判断下一个节点为共享式获取同步状态。
- 调用 #doReleaseShared() 方法,唤醒后续的共享式获取同步状态的节点。
共享式获取响应中断
acquireSharedInterruptibly(int arg) 方法
代码如下:
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
复制代码
共享式超时获取
tryAcquireSharedNanos(int arg, long nanosTimeout) 方法
代码如下:
public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquireShared(arg) >= 0 ||
doAcquireSharedNanos(arg, nanosTimeout);
}
private boolean doAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (nanosTimeout <= 0L)
return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return true;
}
}
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0L)
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
复制代码
共享式同步状态释放
当线程获取同步状态后,执行完相应逻辑后,就需要释放同步状态。AQS 提供了#releaseShared(int arg)方法,释放同步状态。代码如下:
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
复制代码
调用 #tryReleaseShared(int arg) 方法,去尝试释放同步状态,释放成功则设置锁状态并返回 true ,否则获取失败,返回 false 。调用 #doReleaseShared() 方法,唤醒后续的共享式获取同步状态的节点。
tryReleaseShared(int arg) 方法
需要自定义同步组件自己实现,该方法必须要保证线程安全的释放同步状态。代码如下:
protected boolean tryReleaseShared(int arg) {
throw new UnsupportedOperationException();
}
复制代码
直接抛出 UnsupportedOperationException 异常。
doReleaseShared
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
复制代码
AQS:阻塞和唤醒线程
parkAndCheckInterrupt
在线程获取同步状态时,如果获取失败,则加入 CLH 同步队列,通过通过自旋的方式不断获取同步状态,但是在自旋的过程中,则需要判断当前线程是否需要阻塞,其主要方法在acquireQueued(int arg) ,代码如下:
// ... 省略前面无关代码
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
// ... 省略前面无关代码
复制代码
通过这段代码我们可以看到,在获取同步状态失败后,线程并不是立马进行阻塞,需要检查该线程的状态,检查状态的方法为 #shouldParkAfterFailedAcquire(Node pred, Node node)方法,该方法主要靠前驱节点判断当前线程是否应该被阻塞。
如果 #shouldParkAfterFailedAcquire(Node pred, Node node) 方法返回 true ,则调用parkAndCheckInterrupt() 方法,阻塞当前线程。代码如下:
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
复制代码
开始,调用 LockSupport#park(Object blocker) 方法,将当前线程挂起,此时就进入阻塞等待唤醒的状态。
然后,在线程被唤醒时,调用 Thread#interrupted()方法,返回当前线程是否被打断,并清理打断状态。
public static boolean interrupted() {
return currentThread().isInterrupted(true);
}
private native boolean isInterrupted(boolean ClearInterrupted);
复制代码
所以,实际上,线程被唤醒有两种情况:
第一种,当前节点(线程)的前序节点释放同步状态时,唤醒了该线程 。 第二种,当前线程被打断导致唤醒。 复制代码
unparkSuccessor
当线程释放同步状态后,则需要唤醒该线程的后继节点。代码如下:
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h); // 唤醒后继节点
return true;
}
return false;
}
复制代码
调用 unparkSuccessor(Node node) 方法,唤醒后继节点:
private void unparkSuccessor(Node node) {
//当前节点状态
int ws = node.waitStatus;
//当前状态 < 0 则设置为 0
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
//当前节点的后继节点
Node s = node.next;
//后继节点为null或者其状态 > 0 (超时或者被中断了)
if (s == null || s.waitStatus > 0) {
s = null;
//从tail节点来找可用节点
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
//唤醒后继节点
if (s != null)
LockSupport.unpark(s.thread);
}
复制代码
-
可能会存在当前线程的后继节点为 null,例如:超时、被中断的情况。如果遇到这种情况了,则需要跳过该节点。
-
但是,为何是从 tail 尾节点开始,而不是从 node.next 开始呢?原因在于,取消的 node.next.next 指向的是 node.next 自己。如果顺序遍历下去,会导致死循环。所以此时,只能采用 tail 回溯的办法,找到第一个( 不是最新找到的,而是最前序的 )可用的线程。
-
但是,为什么取消的 node.next.next 指向的是 node.next 自己呢?在 #cancelAcquire(Node node) 的末尾,node.next = node; 代码块,取消的 node 节点,将其 next 指向了自己。 最后,调用 LockSupport的unpark(Thread thread) 方法,唤醒该线程。
LockSupport
LockSupport 是用来创建锁和其他同步类的基本线程阻塞原语。
每个使用 LockSupport 的线程都会与一个许可与之关联:
如果该许可可用,并且可在进程中使用,则调用 #park(...) 将会立即返回,否则可能阻塞。 如果许可尚不可用,则可以调用 #unpark(...) 使其可用。 但是,注意许可不可重入,也就是说只能调用一次 park(...) 方法,否则会一直阻塞。 LockSupport 定义了一系列以 park 开头的方法来阻塞当前线程,unpark(Thread thread) 方法来唤醒一个被阻塞的线程。 复制代码
如下图所示:

park(Object blocker)
方法的blocker参数,主要是用来标识当前线程在等待的对象,该对象主要用于问题排查和系统监控。
park 方法和 unpark(Thread thread) 方法,都是成对出现的。同时 unpark(Thread thread) 方法,必须要在 park 方法执行之后执行。当然,并不是说没有调用 unpark(Thread thread) 方法的线程就会一直阻塞
park 有一个方法,它是带了时间戳的 #parkNanos(long nanos) 方法:为了线程调度禁用当前线程,最多等待指定的等待时间,除非许可可用。
public static void park() {
UNSAFE.park(false, 0L);
}
复制代码
unpark
public static void unpark(Thread thread) {
if (thread != null)
UNSAFE.unpark(thread);
}
复制代码
实现原理
从上面可以看出,其内部的实现都是通过 sun.misc.Unsafe 来实现的,其定义如下:
// UNSAFE.java public native void park(boolean var1, long var2); public native void unpark(Object var1); 复制代码
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

