【源码解析】你真的了解ArrayDeque嘛?
积千里跬步,汇万里江河;每天进步一点点,终有一天将成大佬
前言
上篇文章说LinkedList也可以实现 队列 和 栈 的功能,但是我们一般要用队列功能的话推荐使用 ArrayDeque ,因为他层是 数组 ,而队列和栈都是只要 操作头部或尾部 ,所以这样的话数组的性能就比链表快一点,因为它不要找,可以直接通过数组下标获取元素,而链表操作头部或尾部都要通过 二分查找算法 先找到头部或尾部,然后再进行操作。
LinkedList 和 ArrayDeque 都是通过实现了 Deque 这个接口来获得 队列 和 栈 的功能。而 Deque 这个接口通过继承 Queue 这个接口来取得队列功能,然后在这个基础进行扩展,实现了 双端队列 ,由此可以获得 栈 的功能。为了空间能得到充分利用, ArrayDeque 使用了 循环队列 ;还有LinkedList可以插入 null 值,而 ArrayDeque 是不能插入 null 的。
什么是双端队列?
简单来说,就是两端都可以操作的队列(:new_moon_with_face:说了和没说一样…)。哈哈,还是看图吧
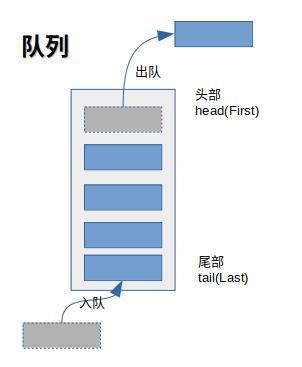
一般队列是这样的:
双端队列是这样的
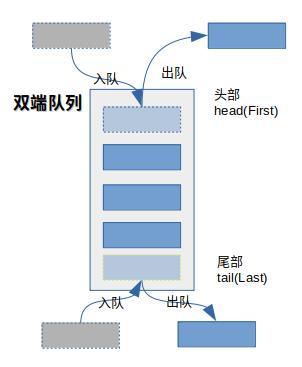
总的来说,普通队列只可在头部删除元素和尾部添加元素,而双端队列头部和尾部都可以添加和删除元素
什么是循环队列?
不如说你定了个5容量大小的数组,你第一次插入的位置是下标为2,当你添加第4个元素的时候,他不会进行扩容,而是通过 头尾指针 进行对比,然后把数据插入到下标为0的位置上。当 头尾指针相等时 ,表示这个队列数组已经满了,这时才会扩容。
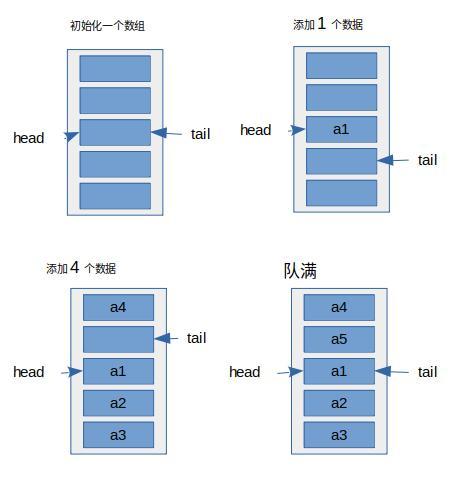
这里的数组从上向下的顺序,有人会问为什么头尾指针都指向第三个方格呢?因为这边演示的是第一个元素插入到下标为2的位置嘛。。当然, ArrayDeque 是从0开始的,所以初始化时头尾指针都是指向下标为0的位置上。
Deque有什么?
话不多说,看图:

ArrayDeque 具体实现的方法主要在蓝色的方框里,其他两个颜色的方框都是通过调用蓝色方框里的这些方法来实现相关功能的,可以再看一张我画的脑图:
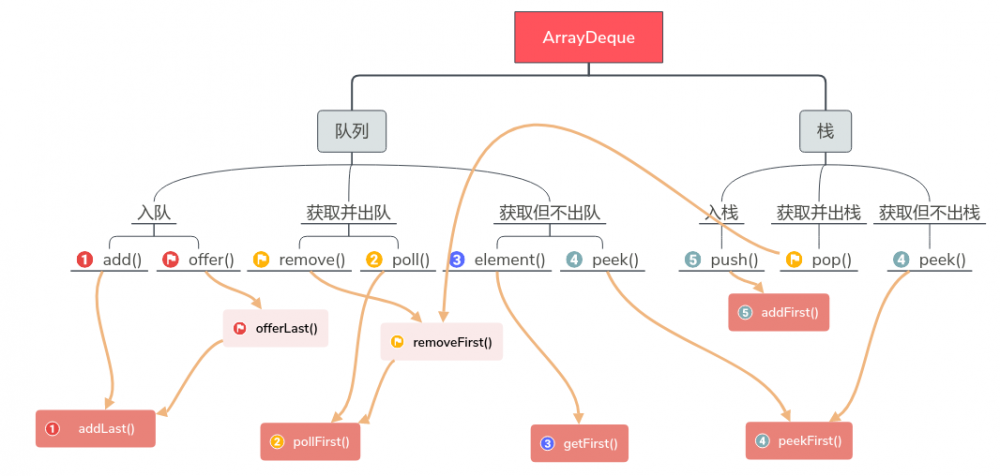
这边队列的每种功能都有两个方法,其中 add() , remove() , element() 如果操作失败会 报异常 , offer() , poll() , peek() 操作失败会 返回null或者false
其实真正用到的就 深红色方框 里写的这些方法,所以本文我就说这四个方法, addLast() , pollFirst , getFirst() , addFirst() , peekFirst ;
内部变量
ArrayDeque内部就只有4个变量, 对象数组element[] , 头指针head , 尾指针tail , MIN_INITIAL_CAPACITY表示最小初始化容量为8
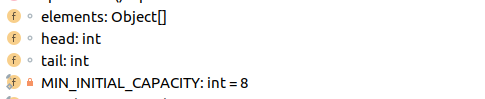
构造方法
构造方法和其他集合一样,有 有参构造 和 无参构造
无参构造
很简单,直接初始化一个 容量为16 的对象数组
public ArrayDeque() {
elements = new Object[16];
}
复制代码
有参构造
传入参数为int数
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
复制代码
- allocateElements(int numElements) 分配空数组以容纳给定数量的元素。
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
复制代码
- calculateSize(int numElements) 调整传入的值大小

上面的算法中用到了位运算,如果不了解位运算的话,可以看位运算这篇文章。这里把数值设置成2的n次方(是整数次),是为了满足下面要说的 循环队列 这个算法
传入的参数为集合对象
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size());
addAll(c);
}
复制代码
第一步调用了和上面一样的方法,这里多了个 addAll() 方法
- addAll(Collection c)
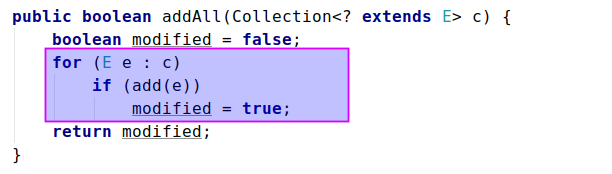
这边复制时并没有用和 ArrayList 一样的 System.arraycopy() 方法,而是采用 for循环 来调用 add() 方法进行一个一个添加的;为什么这么做呢?因为 ArrayDeque 和其他集合不一样,它里面是不能有 null 值的,而其他集合里面有的是可以传 null 的,所以这边采用 add() 一个一个的加, add() 方法如果传入的值为空的话,就会 报异常 ;(add()实际调用的是addLast(),下面再讲)
addLast()
源码解析
这个方法的意思是添加数据到尾部,下面图片方框中的位与算法是实现循环队列这个功能的 核心算法
还记得上面初始化时候,不管传入的是什么数值,最后出来的都是 (整数次)方。这个算法就是 当 & 右边为 时, & 左边的数为正整数时,不管有多大,最后的结果永远<= ;当 & 左边的数为0时,结果为0;当 & 左边的数为负数时,-1=
举一些例子:当 ,
- 4&7=4 9&7=1 22&7=6
- 0&7=0
- -1&7=7 -2&7=6 -8&7=0

- doubleCapacity() 扩容为原来的 2倍
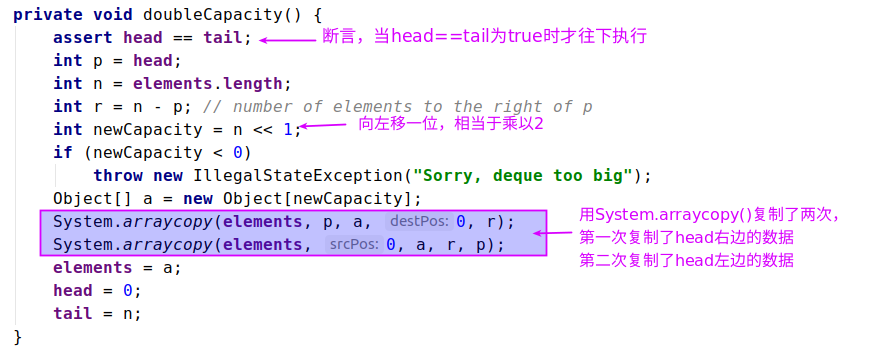
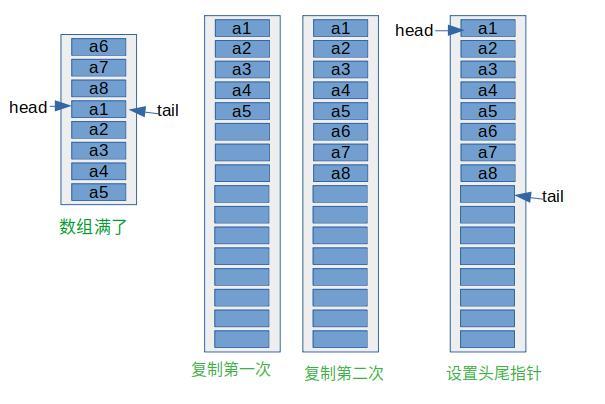
流程图
方便理解,我画下上扩容的流程图,比如head在中间:
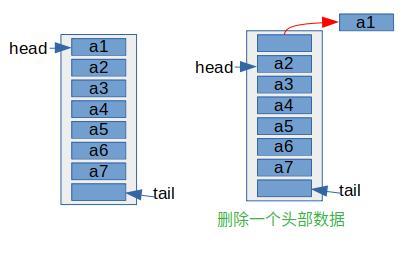
pollFirst()
移除头部数据
源码解析

删除的时候并没有像 ArrayList 一样移动数据,而只是移动了 head 指向的位置
流程图
getFirst()和peekFirst()
这两个方法都是一样的,都是直接返回 head 指向的数据,区别就是一个会抛异常,一个不会
源码分析
- getFirst()
public E getFirst() {
@SuppressWarnings("unchecked")
E result = (E) elements[head];
if (result == null)
throw new NoSuchElementException();
return result;
}
复制代码
- peekFirst()
public E peekFirst() {
// elements[head] is null if deque empty
return (E) elements[head];
}
复制代码
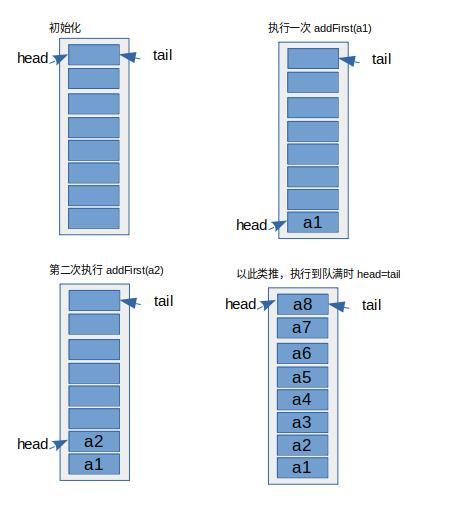
addFirst()
源码解析

这里还是用了上面讲了位与算法,算出 head 的值,然后插入数据
流程图
clear()
源码解析
清空这个操作是从 head 指向的元素开始删除,直到 head = tail ,清空完成;

size()
这个获取队列的大小也是用了上面讲的位与算法,用尾部减去了头部,然后位与数组的长度-1。为什么要这么弄呢?直接向 ArrayList 和 LinkedList 一样定义个size不好嘛? 你不觉得这样更方便吗?少了一个变量,就少维护了一个变量,就少了一个安全隐患啊
public int size() {
return (tail - head) & (elements.length - 1);
}
复制代码
总结
上面的方法基本上有 位与 这个算法的身影,可见这个是核心了;如果不了解位运算的话,可以看位运算这篇文章;
核心算法:
当 & 右边为 时, & 左边的数为正整数时,不管有多大,最后的结果永远<= ;当 & 左边的数为0时,结果为0;当 & 左边的数为负数时,-1=
ArrayDeque 无参构造方法是直接初始化一个容量为16的空数组,而上篇ArrayList文章里,它无参构造方法是初始化了一个 空数组 ,在第一次添加数据的时候才进行扩容到10;
ArrayDeque 每次扩容为原来数组长度的 2倍
ArrayDeque 不能插入 null 值
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

