Graphviz-Gdot语言学习
GVEdit这个绘图软件呢我也是刚接触的,感觉画起图来还是很爽的。。。尤其很熟悉c++后很容易上手这门dot语言。
先看一下十分清新的编程界面:

没有天下最邪恶的语法加亮,没有缩进行。。。这又算什么!我们可是有编译环境的,像这样。。。

所以呢如果不是很习惯它的编程环境自己开一个c++就挺好的。。。(在线的很支持coding.net)
注意,这个编译环境语法不是准确性语法,也就是说你输入的无效字符会自动忽略而不是报一大堆错。。。其实感觉上还是很爽呢!
当然了,一些关键性语法还是会报错的啦。。。(比如像主函数不写这样的。。)
编译命令是F5,生成命令是加上shift
好啦,熟悉了编译环境后,让我们开始Gdot之旅吧(好吧我管这门语言叫做Gdot)
一 .基本语句
前面也提到了Gdot这门语言实在是一种非常简单的描述性语言。如果有其他语言的一定基础再看一两个例子就能很轻松的上手。
我觉得似乎还是跟c比较像?(雾
首先,Gdot非强制面向对象(这不废话吗?怎么可能?),它有一个主函数像这样:
digraph G{ } G是自己命名的,比如我还可以:
digraph HelloWolrd{ } 我们在里面写图即可了。
首先让我们画一个a->b
digraph G{ a->b; }

可以看到,只是a->b;这一条语句我们就画出了一个a到b的流程图。。。(这在画图里需要很久啊。。。。)
哦顺便提一句:Gdot句尾是不需要分号的,作为一名c_er我很手贱。。。
事实上,如果一切按照默认设置,我们将画出一个内容为a的椭圆形用黑色实线箭头指向另一个内容为b的椭圆形,就是这样。
似乎很简单的样子,我们画一个自动机好了:
digraph G{ s->s; s->a; s->b; s->c; a->a; b->c; c->d; d->d; a->e; e->d; }

恩恩还是很不错的。顺便提一句,Graphviz强大之处就在于它的随机布局上面,面对大量的结构它可以做得很好看(而对于画图似乎只能靠人手?)
但是这样看起来很单调对不对?不急,我们给它装饰一下,比如颜色,请注意这个语法:
digraph G{ s->s; s[color=blue]; s->a; a[color=red]; s->b; s->c; a->a; b->c; c->d; d->d; a->e; e->d; }

在对应变量的后面注上中括号[]可以叫做修饰语句,中括号内的语句起到修饰的作用。
对于上面那个例子,我们在s和a的修饰框内注上了颜色,它们的外框颜色就如愿以偿了。
那我想要填充颜色呢?也好说:
digraph G{ s->s; s[style="filled",fillcolor=green]; s->a; a[style="filled"]; s->b; s->c; a->a; b->c; c->d; d->d; a->e; e->d; }

语句似乎有了一些不同,注意到我们修饰了它的状态:fill,意味着是填充状态,也就是我们选中了它的填充面积。那么对于a,可以看到它的填充面积变成了灰色标出。而对于s,由于我们声明了它的填充颜色fillcolor=green它就变成绿色的了。
对于框线的颜色修饰,我们可以这么写:
digraph G{ s->s; s[style="filled",fillcolor=green,color=blue]; s->a; a[style="filled"]; s->b; b[color=blue] s->c; a->a; b->c; c->d; d->d; a->e; e->d; }

在修饰框里只要写上color=...就好了,注意到b的颜色变化,也就是说color是不需要状态filled的,而fillcolor是需要状态filled的,看下面的例子。
digraph G{ a;b; a[style="filled",color=blue,fillcolor=purple]; b[color=blue,fillcolor=purple]; }

状态为filled的a获得了fillcolor的命令,而b则没有。
当然了,如果我们有好多个对象想要都赋成红色我们还每个都加上修饰框吗?当然不是了,我们有一个叫做全局修饰的神奇的东东:
digraph G{ node[style="filled",fillcolor="red"]; a;b;c; }

可以看到,当我们设置了一个全局修饰node后所有的点都设置成了同一个颜色。
当然了,如果要对其中的一个进行修改直接加修饰框覆盖掉全局修饰即可:
digraph G{ node[style="filled",fillcolor="red"]; a;b;c;d[style="null",color=blue]; }

注意,一个style如果仅仅是想要覆盖我想怎么编就怎么编,真的不一定是null。。。
当然了,没有覆盖到的则会保留原有的全局修饰:
digraph G{ node[style="filled",fillcolor="red"]; a;b;c;d[color=blue]; }

那么颜色大概就是这样了,我们可以看一下它的形状,都是椭圆形其实很丑的。。。。
比如说呢,矩形?
digraph G{ a[shape="box",style="filled",fillcolor="red"]; }

只要在修饰框中修饰shape=box就好了,似乎好简单。。。(其实应该写record的我懒。。。shape的默认值应该就是矩形)
当然了,我们还可以让它变得奇怪一点:
digraph G{ a[shape="record",style="dashed"]; }
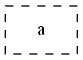
style=dashed就修饰了它的框框变成虚的,但是貌似就不能再filled了。。。(当然了,虚框你怎么fill啊。。。)
不过呢我们还是可以修饰它的线的颜色的,像这样:
digraph G{ a[shape="record",style="dashed",color="purple"]; }
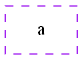
然后我突然发现我后面写的东西都丢了妈呀,瞬间就不想再写了= =(博客园的编辑器实在需要改进= =)
之后就是一些数据结构之类的东西了,感兴趣可以看看这些大神的,写的都比我好= =:
http://www.cnblogs.com/sld666666/archive/2010/06/25/1765510.html
http://www.cnblogs.com/CoolJie/archive/2012/07/17/graphviz.html
事实上graphviz的子图以及结构师最重要的组成部分了,那我转一点来弥补这个遗漏吧,以下【转】:
子图的绘制
graphviz支持子图,即图中的部分节点和边相对对立(软件的模块划分经常如此)。比如,我们可以将顶点c和d归为一个子图:
1: digraph abc{ 2: 3: node [shape="record"]; 4: edge [style="dashed"]; 5: 6: a [style="filled", color="black", fillcolor="chartreuse"]; 7: b; 8: 9: subgraph cluster_cd{ 10: label="c and d"; 11: bgcolor="mintcream"; 12: c; 13: d; 14: } 15: 16: a -> b; 17: b -> d; 18: c -> d [color="red"]; 19: } 将c和d划分到cluster_cd这个子图中,标签为”c and d”,并添加背景色,以方便与主图区分开,绘制结果如下:

应该注意的是,子图的名称必须以cluster开头,否则graphviz无法设别。
数据结构的可视化
实际开发中,经常要用到的是对复杂数据结构的描述,graphviz提供完善的机制来绘制此类图形。
一个hash表的数据结构
比如一个hash表的内容,可能具有下列结构:
1: struct st_hash_type { 2: int (*compare) (); 3: int (*hash) (); 4: }; 5: 6: struct st_table_entry { 7: unsigned int hash; 8: char *key; 9: char *record; 10: st_table_entry *next; 11: }; 12: 13: struct st_table { 14: struct st_hash_type *type; 15: int num_bins; /* slot count */ 16: int num_entries; /* total number of entries */ 17: struct st_table_entry **bins; /* slot */ 18: }; 绘制hash表的数据结构
从代码上看,由于结构体存在引用关系,不够清晰,如果层次较多,则很难以记住各个结构之间的关系,我们可以通过下图来更清楚的展示:

脚本如下:
1: digraph st2{ 2: fontname = "Verdana"; 3: fontsize = 10; 4: rankdir=TB; 5: 6: node [fontname = "Verdana", fontsize = 10, color="skyblue", shape="record"]; 7: 8: edge [fontname = "Verdana", fontsize = 10, color="crimson", style="solid"]; 9: 10: st_hash_type [label="{<head>st_hash_type|(*compare)|(*hash)}"]; 11: st_table_entry [label="{<head>st_table_entry|hash|key|record|<next>next}"]; 12: st_table [label="{st_table|<type>type|num_bins|num_entries|<bins>bins}"]; 13: 14: st_table:bins -> st_table_entry:head; 15: st_table:type -> st_hash_type:head; 16: st_table_entry:next -> st_table_entry:head [style="dashed", color="forestgreen"]; 17: } 应该注意到,在顶点的形状为”record”的时候,label属性的语法比较奇怪,但是使用起来非常灵活。比如,用竖线”|”隔开的串会在绘制出来的节点中展现为一条分隔符。用”<>”括起来的串称为锚点,当一个节点具有多个锚点的时候,这个特性会非常有用,比如节点st_table的type属性指向st_hash_type,第4个属性指向st_table_entry等,都是通过锚点来实现的。
我们发现,使用默认的dot布局后,绿色的这条边覆盖了数据结构st_table_entry,并不美观,因此可以使用别的布局方式来重新布局,如使用circo算法:

则可以得到更加合理的布局结果。
hash表的实例
另外,这个hash表的一个实例如下:

脚本如下:
1: digraph st{ 2: 3: fontname = "Verdana"; 4: fontsize = 10; 5: rankdir = LR; 6: rotate = 90; 7: 8: node [ shape="record", width=.1, height=.1]; 9: node [fontname = "Verdana", fontsize = 10, color="skyblue", shape="record"]; 10: 11: edge [fontname = "Verdana", fontsize = 10, color="crimson", style="solid"]; 12: node [shape="plaintext"]; 13: 14: st_table [label=< 15: <table border="0" cellborder="1" cellspacing="0" align="left"> 16: <tr> 17: <td>st_table</td> 18: </tr> 19: <tr> 20: <td>num_bins=5</td> 21: </tr> 22: <tr> 23: <td>num_entries=3</td> 24: </tr> 25: <tr> 26: <td port="bins">bins</td> 27: </tr> 28: </table> 29: >]; 30: 31: node [shape="record"]; 32: num_bins [label=" <b1> | <b2> | <b3> | <b4> | <b5> ", height=2]; 33: node[ width=2 ]; 34: 35: entry_1 [label="{<e>st_table_entry|<next>next}"]; 36: entry_2 [label="{<e>st_table_entry|<next>null}"]; 37: entry_3 [label="{<e>st_table_entry|<next>null}"]; 38: 39: st_table:bins -> num_bins:b1; 40: num_bins:b1 -> entry_1:e; 41: entry_1:next -> entry_2:e; 42: num_bins:b3 -> entry_3:e; 43: 44: } 上例中可以看到,节点的label属性支持类似于HTML语言中的TABLE形式的定义,通过行列的数目来定义节点的形状,从而使得节点的组成更加灵活。
软件模块组成图
Apache httpd模块关系

IDPV2后台的模块组成关系
在实际的开发中,随着系统功能的完善,软件整体的结构会越来越复杂,通常开发人员会将软件划分为可理解的多个子模块,各个子模块通过协作,完成各种各样的需求。
下面有个例子,是在IDPV2设计时的一个草稿:

IDP支持层为一个相对独立的子系统,其中包括如数据库管理器,配置信息管理器等模块,另外为了提供更大的灵活性,将很多其他的模块抽取出来作为外部模块,而支持层提供一个模块管理器,来负责加载/卸载这些外部的模块集合。
这些模块间的关系较为复杂,并且有部分模块关系密切,应归类为一个子系统中,上图对应的dot脚本为:
1: digraph idp_modules{ 2: 3: rankdir = TB; 4: fontname = "Microsoft YaHei"; 5: fontsize = 12; 6: 7: node [ fontname = "Microsoft YaHei", fontsize = 12, shape = "record" ]; 8: edge [ fontname = "Microsoft YaHei", fontsize = 12 ]; 9: 10: subgraph cluster_sl{ 11: label="IDP支持层"; 12: bgcolor="mintcream"; 13: node [shape="Mrecord", color="skyblue", style="filled"]; 14: network_mgr [label="网络管理器"]; 15: log_mgr [label="日志管理器"]; 16: module_mgr [label="模块管理器"]; 17: conf_mgr [label="配置管理器"]; 18: db_mgr [label="数据库管理器"]; 19: }; 20: 21: subgraph cluster_md{ 22: label="可插拔模块集"; 23: bgcolor="lightcyan"; 24: node [color="chartreuse2", style="filled"]; 25: mod_dev [label="开发支持模块"]; 26: mod_dm [label="数据建模模块"]; 27: mod_dp [label="部署发布模块"]; 28: }; 29: 30: mod_dp -> mod_dev [label="依赖..."]; 31: mod_dp -> mod_dm [label="依赖..."]; 32: mod_dp -> module_mgr [label="安装...", color="yellowgreen", arrowhead="none"]; 33: mod_dev -> mod_dm [label="依赖..."]; 34: mod_dev -> module_mgr [label="安装...", color="yellowgreen", arrowhead="none"]; 35: mod_dm -> module_mgr [label="安装...", color="yellowgreen", arrowhead="none"]; 36: 37: } 38: 状态图
有限自动机示意图

上图是一个简易有限自动机,接受a及a结尾的任意长度的串。其脚本定义如下:
1: digraph automata_0 { 2: 3: size = "8.5, 11"; 4: fontname = "Microsoft YaHei"; 5: fontsize = 10; 6: 7: node [shape = circle, fontname = "Microsoft YaHei", fontsize = 10]; 8: edge [fontname = "Microsoft YaHei", fontsize = 10]; 9: 10: 0 [ style = filled, color=lightgrey ]; 11: 2 [ shape = doublecircle ]; 12: 13: 0 -> 2 [ label = "a " ]; 14: 0 -> 1 [ label = "other " ]; 15: 1 -> 2 [ label = "a " ]; 16: 1 -> 1 [ label = "other " ]; 17: 2 -> 2 [ label = "a " ]; 18: 2 -> 1 [ label = "other " ]; 19: 20: "Machine: a" [ shape = plaintext ]; 21: } 形状值为plaintext的表示不用绘制边框,仅展示纯文本内容,这个在绘图中,绘制指示性的文本时很有用,如上图中的”Machine: a”。
OSGi中模块的生命周期图
OSGi中,模块具有生命周期,从安装到卸载,可能的状态具有已安装,已就绪,正在启动,已启动,正在停止,已卸载等。如下图所示:

对应的脚本如下:
1: digraph module_lc{ 2: 3: rankdir=TB; 4: fontname = "Microsoft YaHei"; 5: fontsize = 12; 6: 7: node [fontname = "Microsoft YaHei", fontsize = 12, shape = "Mrecord", color="skyblue", style="filled"]; 8: edge [fontname = "Microsoft YaHei", fontsize = 12, color="darkgreen" ]; 9: 10: installed [label="已安装状态"]; 11: resolved [label="已就绪状态"]; 12: uninstalled [label="已卸载状态"]; 13: starting [label="正在启动"]; 14: active [label="已激活(运行)状态"]; 15: stopping [label="正在停止"]; 16: start [label="", shape="circle", width=0.5, fixedsize=true, style="filled", color="black"]; 17: 18: start -> installed [label="安装"]; 19: installed -> uninstalled [label="卸载"]; 20: installed -> resolved [label="准备"]; 21: installed -> installed [label="更新"]; 22: resolved -> installed [label="更新"]; 23: resolved -> uninstalled [label="卸载"]; 24: resolved -> starting [label="启动"]; 25: starting -> active [label=""]; 26: active -> stopping [label="停止"]; 27: stopping -> resolved [label=""]; 28: 29: } 其他实例
一棵简单的抽象语法树(AST)
表达式 (3+4)*5 在编译时期,会形成一棵语法树,一边在计算时,先计算3+4的值,最后与5相乘。

对应的脚本如下:
1: digraph ast{ 2: fontname = "Microsoft YaHei"; 3: fontsize = 10; 4: 5: node [shape = circle, fontname = "Microsoft YaHei", fontsize = 10]; 6: edge [fontname = "Microsoft YaHei", fontsize = 10]; 7: node [shape="plaintext"]; 8: 9: mul [label="mul(*)"]; 10: add [label="add(+)"]; 11: 12: add -> 3 13: add -> 4; 14: mul -> add; 15: mul -> 5; 16: } 17: 简单的UML类图
下面是一简单的UML类图,Dog和Cat都是Animal的子类,Dog和Cat同属一个包,且有可能有联系(0..n)。

脚本:
1: digraph G{ 2: 3: fontname = "Courier New" 4: fontsize = 10 5: 6: node [ fontname = "Courier New", fontsize = 10, shape = "record" ]; 7: edge [ fontname = "Courier New", fontsize = 10 ]; 8: 9: Animal [ label = "{Animal |+ name : Stringl+ age : intl|+ die() : voidl}" ]; 10: 11: subgraph clusterAnimalImpl{ 12: bgcolor="yellow" 13: Dog [ label = "{Dog||+ bark() : voidl}" ]; 14: Cat [ label = "{Cat||+ meow() : voidl}" ]; 15: }; 16: 17: edge [ arrowhead = "empty" ]; 18: 19: Dog->Animal; 20: Cat->Animal; 21: Dog->Cat [arrowhead="none", label="0..*"]; 22: } 状态图

脚本:
1: digraph finite_state_machine { 2: 3: rankdir = LR; 4: size = "8,5" 5: 6: node [shape = doublecircle]; 7: 8: LR_0 LR_3 LR_4 LR_8; 9: 10: node [shape = circle]; 11: 12: LR_0 -> LR_2 [ label = "SS(B)" ]; 13: LR_0 -> LR_1 [ label = "SS(S)" ]; 14: LR_1 -> LR_3 [ label = "S($end)" ]; 15: LR_2 -> LR_6 [ label = "SS(b)" ]; 16: LR_2 -> LR_5 [ label = "SS(a)" ]; 17: LR_2 -> LR_4 [ label = "S(A)" ]; 18: LR_5 -> LR_7 [ label = "S(b)" ]; 19: LR_5 -> LR_5 [ label = "S(a)" ]; 20: LR_6 -> LR_6 [ label = "S(b)" ]; 21: LR_6 -> LR_5 [ label = "S(a)" ]; 22: LR_7 -> LR_8 [ label = "S(b)" ]; 23: LR_7 -> LR_5 [ label = "S(a)" ]; 24: LR_8 -> LR_6 [ label = "S(b)" ]; 25: LR_8 -> LR_5 [ label = "S(a)" ]; 26: 27: } 附录
事实上,从dot的语法及上述的示例中,很容易看出,dot脚本很容易被其他语言生成。比如,使用一些简单的数据库查询就可以生成数据库中的ER图的dot脚本。
如果你追求高效的开发速度,并希望快速的将自己的想法 画 出来,那么graphviz是一个很不错的选择。
当然,graphviz也有一定的局限,比如绘制时序图(序列图)就很难实现。graphviz的节点出现在画布上的位置事实上是不确定的,依赖于所使用的布局算法,而不是在脚本中出现的位置,这可能使刚开始接触graphviz的开发人员有点不适应。graphviz的强项在于自动布局,当图中的顶点和边的数目变得很多的时候,才能很好的体会这一特性的好处:

比如上图,或者较上图更复杂的图,如果采用手工绘制显然是不可能的,只能通过graphviz提供的自动布局引擎来完成。如果仅用于展示模块间的关系,子模块与子模块间通信的方式,模块的逻辑位置等,graphviz完全可以胜任,但是如果图中对象的物理位置必须是准确的,如节点A必须位于左上角,节点B必须与A相邻等特性,使用graphviz则很难做到。毕竟,它的强项是自动布局,事实上,所有的节点对与布局引擎而言,权重在初始时都是相同的,只是在渲染之后,节点的大小,形状等特性才会影响权重。
本文只是初步介绍了graphviz的简单应用,如图的定义,顶点/边的属性定义,如果运行等,事实上还有很多的属性,如画布的大小,字体的选择,颜色列表等,大家可以通过graphviz的官网来找到更详细的资料。
graphviz真的是一个很好用的东西,希望大家喜欢。
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

