基于DB time的调优分析
继昨天使用DB time能够快速灵活的定位sql语句之后,发现分析问题更快捷,高效了。今天就牛刀小试,把一个数据库从500%的负载调到不到100%的负载。前提是确实有可提升可改进的空间。
首先查看了在快照57611的时间段里DB time很快,也收到了zabbix的邮件通知,
$ ksh showsnapsql.sh 57611
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------- ---------------- ---------- ----------
57611 8tmf11fvxy09j 30 2451s 32%
57611 cy55p6nrd31db 30 2346s 31%
57611 4rhpc838qfsmy 143 655s 8%
57611 c7k4g2urpu1sc 0 426s 5%
57611 29tdwfv5d9s4f 30 441s 5%
可以看到在快照57611的时间段内,有两个sql是尤其需要关注的,占用了60%多的DB time,也就意味着如果这两个语句能够改进,对于DB time的提升就很高了,同理,对于系统的负载也会减轻很多。
我们来看看sql_id 8tmf11fvxy09j这个语句。这个语句一个快照时间范围内执行了近30次,每次执行大概是80秒左右。发现这个语句是一个看似简单的查询。
$ ksh showsql.sh 8tmf11fvxy09j
SQL_FULLTEXT
----------------------------------------------------------------------------------------------------
SELECT ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_BILLDETAIL WHERE END_TIME >
TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME)
而查看执行计划发现,指标还是正常的,可以看到这个表TES_BILLDETAIL是一个分区表,分区有900多个。
Plan hash value: 2129377450
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 13 (100)
| 1 | SORT AGGREGATE | | 1 | 32 | 13 (8)
| 2 | HASH GROUP BY | | 1 | 32 | 13 (8)
| 3 | PARTITION RANGE ITERATOR | | 1 | 32 | 12 (0)
|* 4 | TABLE ACCESS BY LOCAL INDEX ROWID| TES_BILLDETAIL | 1 | 32 | 12 (0)
|* 5 | INDEX RANGE SCAN | IND_TES_BILLDETAIL_END_TIME | 49 | | 1 (0)
--------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$1
4 - SEL$1 / TES_BILLDETAIL@SEL$1
5 - SEL$1 / TES_BILLDETAIL@SEL$1
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("CN"=:1)
5 - access("END_TIME">TRUNC(SYSDATE@!-30))
通过谓词信息可以看到走了end_date相关的索引。
执行计划看起来还是不错的,但是执行的情况确实还是不够理想,那么我们怎么查看执行的细节呢,如果是11g的库,sqlmonitor就是一个利器,使用下面的语句抓取了正在执行的sql情况。
set pages 0
set long 99999999
set linesize 150
col comm format a200
set long 99999
SELECT dbms_sqltune.report_sql_monitor(
sql_id => '8tmf11fvxy09j',
report_level => 'ALL',
type=>'HTML'
) comm
FROM dual;
可以看到
SQL Plan Monitoring Details (Plan Hash Value=2129377450)
绑定变量值也能抓取到。
带着疑问查看了下数据的情况,发现使用字段CN来过滤,只有1000多条记录,相比通过时间来过滤的900多万记录来说差别实在是太大了。
SQL> select count(*)from TES_BILLDETAIL where cn='582891946';
1052
Elapsed: 00:00:00.01
关于这个表的索引情况如下:
INDEX_NAME TABLESPACE INDEX_TYPE UNIQUENES PAR COLUMN_LIST TABLE_TYPE STATUS NUM_ROWS LAST_ANALYZED G
------------------------------ ---------- ---------- --------- --- ------------------------------ ---------- ------ ---------- ------------------- -
IND_TES_BILLDETAIL_CN NORMAL NONUNIQUE YES CN TABLE N/A 3145619347 2015-06-26 04:52:11 N
IND_TES_BILLDETAIL_END_TIME NORMAL NONUNIQUE YES END_TIME TABLE N/A 2926456256 2015-06-26 04:52:23 N
在字段CN上也是有索引的,同时还有一个索引是end_time上,但是通过end_time过滤的数据实在是有点多,尽管相比整张表几十亿的记录来说确实是很大的改进,但是相比于字段CN过滤的数据结果来说,差别更加的悬殊。
所以采用CN来过滤着实是一个不错的选择。可以简单打一个比方,比如我去网上购物,购物的所以记录都存放在一张表里,如果需要把我最近这些天的消费记录抓取出来,肯定是通过我的id号直接关联,然后再过滤时间要好一些,如果直接来过滤时间,先把全国人民购物的这些天的数据都抓出来再过滤,这样的差别着实很大,也不高效。
为什么走了end_time的索引而不是CN字段的索引,一个原因就是分区字段是根据end_time来做的,刚好有prefix的local index,加上直方图的信息,所以优化器做评判的时候根据这些信息分析觉得还是end_time的索引要好一些,而CN字段的信息是non-prefix的,CN的信息在各个分区中就很难评估,这个时候优化器评判的基准也有一定的限制了。
当然,查看这个索引的并行度的时候发现竟然是12,可见之前也有同学尝试改进过这个问题,似乎从并行上下工夫了。
SQL> SELECT DEGREE FROM DBA_INDEXES WHERE INDEX_NAME='IND_TES_BILLDETAIL_CN';
12
当然这个的效果也有,但是解决的力度还是不大。
我们加入hint先来看看效果。
EXPLAIN PLAN FOR SELECT /*+INDEX(TES_BILLDETAIL IND_TES_BILLDETAIL_CN)*/ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_BILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME)
发现索引能够正常启用,而且cost也不高,就按照这个方子来试试。
如果想有一种更好更全面的改进,就是添加复合索引,但是有一些隐患,一来这个表实在太大了,加索引时间,资源都是很大的消耗,二来更重要的是不确定添加索引之后会对其它的语句有很大的影响,所以为了保险起见,我先修改这两个相关的sql,修改它的执行计划,在线就可以做,如果不合适,撤销就可以。
修改执行计划可以使用sqlt来做,coe提供的这套工具还是很不错的。
因为里面有绑定变量,所以尝试用下面的方式来做。
declare
cursor temp_cur is select '582891946' id from dual;
begin
for i in temp_cur loop
execute immediate 'SELECT /*+INDEX(TES_BILLDETAIL IND_TES_BILLDETAIL_CN)*/ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_BILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME) '
using i.id;
end loop;
end;
/
SQL> @a.sql
PL/SQL procedure successfully completed.
然后从v$sql里面去抓取,可以找到修改后的sql的sql_id
SQL_ID SQL_FULLTEXT
------------- ----------------------------------------------------------------------------------------------------
9h0kr4s3365mt SELECT /*+INDEX(TES_BILLDETAIL IND_TES_BILLDETAIL_CN)*/ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG
FROM TES_BILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME)
所以sql_id 9h0kr4s3365mt就是我们努力的目标,使用提供的脚本来得到执行计划的profile信息。输入sql_id和hash_value即可。
SQL>@coe_xfr_sql_profile.sql
Parameter 1:
SQL_ID (required)
Enter value for 1: 8tmf11fvxy09j
PLAN_HASH_VALUE AVG_ET_SECS
--------------- -----------
2129377450 70.743
Parameter 2:
PLAN_HASH_VALUE (required)
Enter value for 2: 2129377450
Values passed to coe_xfr_sql_profile:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
SQL_ID : "8tmf11fvxy09j"
PLAN_HASH_VALUE: "2129377450"
然后输入修改后的sql_id,也得到一个执行计划的proifle信息,我们需要做一个置换。
SQL> @coe_xfr_sql_profile.sql
Parameter 1:
SQL_ID (required)
Enter value for 1: 9h0kr4s3365mt
PLAN_HASH_VALUE AVG_ET_SECS
--------------- -----------
3361841277 .003
Parameter 2:
PLAN_HASH_VALUE (required)
Enter value for 2: 3361841277
Values passed to coe_xfr_sql_profile:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
SQL_ID : "9h0kr4s3365mt"
PLAN_HASH_VALUE: "3361841277"
得到的关于hint部分的信息如下,原来的sql中的信息为:
h := SYS.SQLPROF_ATTR(
q'[BEGIN_OUTLINE_DATA]',
q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
q'[OPTIMIZER_FEATURES_ENABLE('11.2.0.3')]',
q'[DB_VERSION('11.2.0.3')]',
q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
q'[OPT_PARAM('optimizer_index_caching' 90)]',
q'[ALL_ROWS]',
q'[OUTLINE_LEAF(@"SEL$1")]',
q'[INDEX_RS_ASC(@"SEL$1" "TES_BILLDETAIL"@"SEL$1" ("TES_BILLDETAIL"."CN"))]',
q'[USE_HASH_AGGREGATION(@"SEL$1")]',
q'[END_OUTLINE_DATA]');
添加了hint之后启用了CN相关的索引的hint信息如下:
h := SYS.SQLPROF_ATTR(
q'[BEGIN_OUTLINE_DATA]',
q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
q'[OPTIMIZER_FEATURES_ENABLE('11.2.0.3')]',
q'[DB_VERSION('11.2.0.3')]',
q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
q'[OPT_PARAM('optimizer_index_caching' 90)]',
q'[ALL_ROWS]',
q'[OUTLINE_LEAF(@"SEL$1")]',
q'[INDEX_RS_ASC(@"SEL$1" "TES_BILLDETAIL"@"SEL$1" ("TES_BILLDETAIL"."CN"))]',
q'[USE_HASH_AGGREGATION(@"SEL$1")]',
q'[END_OUTLINE_DATA]');
需要把这部分内容替换原来sqlprofile中的hint部分。
拷贝替换之后,就可以生成sqlprofile了,运行脚本的结果如下:
SQL> DECLARE
2 sql_txt CLOB;
3 h SYS.SQLPROF_ATTR;
4 PROCEDURE wa (p_line IN VARCHAR2) IS
5 BEGIN
6 DBMS_LOB.WRITEAPPEND(sql_txt, LENGTH(p_line), p_line);
7 END wa;
8 BEGIN
9 DBMS_LOB.CREATETEMPORARY(sql_txt, TRUE);
10 DBMS_LOB.OPEN(sql_txt, DBMS_LOB.LOB_READWRITE);
11 -- SQL Text pieces below do not have to be of same length.
12 -- So if you edit SQL Text (i.e. removing temporary Hints),
13 -- there is no need to edit or re-align unmodified pieces.
14 wa(q'[ SELECT ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_B]');
15 wa(q'[ILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN ]');
16 wa(q'[= :1 GROUP BY TRUNC(END_TIME) ]');
17 DBMS_LOB.CLOSE(sql_txt);
18 h := SYS.SQLPROF_ATTR(
19 q'[BEGIN_OUTLINE_DATA]',
20 q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
21 q'[OPTIMIZER_FEATURES_ENABLE('11.2.0.3')]',
22 q'[DB_VERSION('11.2.0.3')]',
23 q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
24 q'[OPT_PARAM('optimizer_index_caching' 90)]',
25 q'[ALL_ROWS]',
26 q'[OUTLINE_LEAF(@"SEL$1")]',
27 q'[INDEX_RS_ASC(@"SEL$1" "TES_BILLDETAIL"@"SEL$1" ("TES_BILLDETAIL"."CN"))]',
28 q'[USE_HASH_AGGREGATION(@"SEL$1")]',
29 q'[END_OUTLINE_DATA]');
30 :signature := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt);
31 :signaturef := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt, TRUE);
32 DBMS_SQLTUNE.IMPORT_SQL_PROFILE (
33 sql_text => sql_txt,
34 profile => h,
35 name => 'coe_8tmf11fvxy09j_2129377450',
36 description => 'coe 8tmf11fvxy09j 2129377450 '||:signature||' '||:signaturef||'',
37 category => 'DEFAULT',
38 validate => TRUE,
39 replace => TRUE,
40 force_match => FALSE /* TRUE:FORCE (match even when different literals in SQL). FALSE:EXACT (similar to CURSOR_SHARING) */ );
41 DBMS_LOB.FREETEMPORARY(sql_txt);
42 END;
43 /
PL/SQL procedure successfully completed.
SQL> WHENEVER SQLERROR CONTINUE
SQL> SET ECHO OFF;
SIGNATURE
---------------------
4228059721940760383
SIGNATUREF
---------------------
4228059721940760383
... manual custom SQL Profile has been created
COE_XFR_SQL_PROFILE_8tmf11fvxy09j_2129377450 completed
sql profile已经启用了,再次查看就可以看到已经生效了。
SQL> SELECT *FROM TABLE(DBMS_XPLAN.DISPLAY);
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------
Plan hash value: 3361841277
------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 32 | 41 (3)| 00:00:01 | | |
| 1 | SORT AGGREGATE | | 1 | 32 | 41 (3)| 00:00:01 | | |
| 2 | HASH GROUP BY | | 1 | 32 | 41 (3)| 00:00:01 | | |
| 3 | PARTITION RANGE ITERATOR | | 1 | 32 | 40 (0)| 00:00:01 | KEY | 970 |
|* 4 | TABLE ACCESS BY LOCAL INDEX ROWID| TES_BILLDETAIL | 1 | 32 | 40 (0)| 00:00:01 | KEY | 970 |
|* 5 | INDEX RANGE SCAN | IND_TES_BILLDETAIL_CN | 42 | | 35 (0)| 00:00:01 | KEY | 970 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("END_TIME">TRUNC(SYSDATE@!-30))
5 - access("CN"=:1)
Note
-----
- SQL profile "coe_8tmf11fvxy09j_2129377450" used for this statement
按照这个思路,又对另外两个sql进行类类似的分析,结果也是使用Hint来调整,使用sql monitor来查看实时的执行计划情况,使用sqlt来修改执行计划。
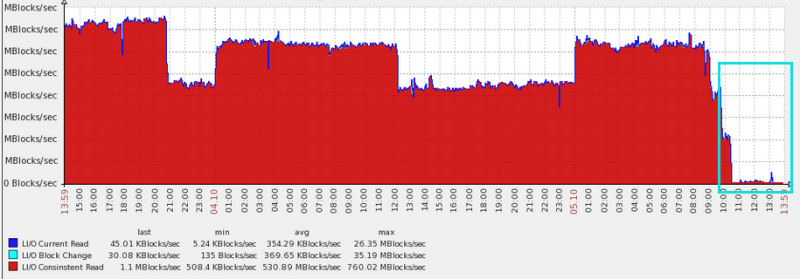
调优之后的效果还是很明显的。DB time大大降低,逻辑读的效果更加明显。
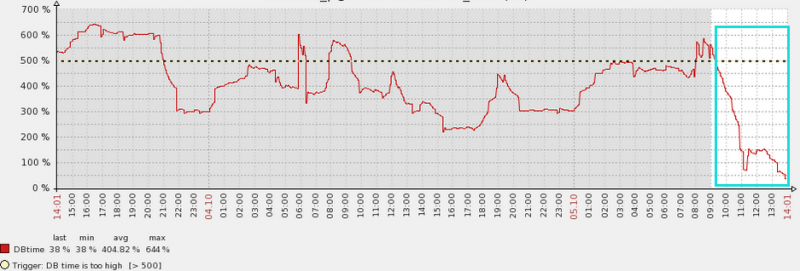
首先查看了在快照57611的时间段里DB time很快,也收到了zabbix的邮件通知,
ZABBIX-监控系统:
------------------------------------
报警内容: DB time is too high
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: DBtime:530 %
------------------------------------
报警时间:2015.10.04-07:58:55
$ ksh showsnapsql.sh 57611
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------- ---------------- ---------- ----------
57611 8tmf11fvxy09j 30 2451s 32%
57611 cy55p6nrd31db 30 2346s 31%
57611 4rhpc838qfsmy 143 655s 8%
57611 c7k4g2urpu1sc 0 426s 5%
57611 29tdwfv5d9s4f 30 441s 5%
可以看到在快照57611的时间段内,有两个sql是尤其需要关注的,占用了60%多的DB time,也就意味着如果这两个语句能够改进,对于DB time的提升就很高了,同理,对于系统的负载也会减轻很多。
我们来看看sql_id 8tmf11fvxy09j这个语句。这个语句一个快照时间范围内执行了近30次,每次执行大概是80秒左右。发现这个语句是一个看似简单的查询。
$ ksh showsql.sh 8tmf11fvxy09j
SQL_FULLTEXT
----------------------------------------------------------------------------------------------------
SELECT ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_BILLDETAIL WHERE END_TIME >
TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME)
而查看执行计划发现,指标还是正常的,可以看到这个表TES_BILLDETAIL是一个分区表,分区有900多个。
Plan hash value: 2129377450
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 13 (100)
| 1 | SORT AGGREGATE | | 1 | 32 | 13 (8)
| 2 | HASH GROUP BY | | 1 | 32 | 13 (8)
| 3 | PARTITION RANGE ITERATOR | | 1 | 32 | 12 (0)
|* 4 | TABLE ACCESS BY LOCAL INDEX ROWID| TES_BILLDETAIL | 1 | 32 | 12 (0)
|* 5 | INDEX RANGE SCAN | IND_TES_BILLDETAIL_END_TIME | 49 | | 1 (0)
--------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$1
4 - SEL$1 / TES_BILLDETAIL@SEL$1
5 - SEL$1 / TES_BILLDETAIL@SEL$1
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("CN"=:1)
5 - access("END_TIME">TRUNC(SYSDATE@!-30))
通过谓词信息可以看到走了end_date相关的索引。
执行计划看起来还是不错的,但是执行的情况确实还是不够理想,那么我们怎么查看执行的细节呢,如果是11g的库,sqlmonitor就是一个利器,使用下面的语句抓取了正在执行的sql情况。
set pages 0
set long 99999999
set linesize 150
col comm format a200
set long 99999
SELECT dbms_sqltune.report_sql_monitor(
sql_id => '8tmf11fvxy09j',
report_level => 'ALL',
type=>'HTML'
) comm
FROM dual;
可以看到
SQL Plan Monitoring Details (Plan Hash Value=2129377450)
| Id | Operation | Name | Estimated | Cost | Execs | Rows | |
| Rows | |||||||
| . | 0 | SELECT STATEMENT | . | . | . | 1 | . |
| . | 1 | . SORT AGGREGATE | . | 1 | 13 | 1 | . |
| -> | 2 | .. HASH GROUP BY | . | 1 | 13 | 1 | 0 |
| -> | 3 | ... PARTITION RANGE ITERATOR | . | 1 | 12 | 1 | 3 |
| -> | 4 | .... TABLE ACCESS BY LOCAL INDEX ROWID | TES_BILLDETAIL | 1 | 12 | 5 | 3 |
| -> | 5 | ..... INDEX RANGE SCAN | IND_TES_BILLDETAIL _END_TIME | 49 | 1 | 5 | 9M |
绑定变量值也能抓取到。
| Name | Position | Type | Value |
|---|---|---|---|
| :1 | 1 | VARCHAR2(128) | 582891946 |
SQL> select count(*)from TES_BILLDETAIL where cn='582891946';
1052
Elapsed: 00:00:00.01
关于这个表的索引情况如下:
INDEX_NAME TABLESPACE INDEX_TYPE UNIQUENES PAR COLUMN_LIST TABLE_TYPE STATUS NUM_ROWS LAST_ANALYZED G
------------------------------ ---------- ---------- --------- --- ------------------------------ ---------- ------ ---------- ------------------- -
IND_TES_BILLDETAIL_CN NORMAL NONUNIQUE YES CN TABLE N/A 3145619347 2015-06-26 04:52:11 N
IND_TES_BILLDETAIL_END_TIME NORMAL NONUNIQUE YES END_TIME TABLE N/A 2926456256 2015-06-26 04:52:23 N
在字段CN上也是有索引的,同时还有一个索引是end_time上,但是通过end_time过滤的数据实在是有点多,尽管相比整张表几十亿的记录来说确实是很大的改进,但是相比于字段CN过滤的数据结果来说,差别更加的悬殊。
所以采用CN来过滤着实是一个不错的选择。可以简单打一个比方,比如我去网上购物,购物的所以记录都存放在一张表里,如果需要把我最近这些天的消费记录抓取出来,肯定是通过我的id号直接关联,然后再过滤时间要好一些,如果直接来过滤时间,先把全国人民购物的这些天的数据都抓出来再过滤,这样的差别着实很大,也不高效。
为什么走了end_time的索引而不是CN字段的索引,一个原因就是分区字段是根据end_time来做的,刚好有prefix的local index,加上直方图的信息,所以优化器做评判的时候根据这些信息分析觉得还是end_time的索引要好一些,而CN字段的信息是non-prefix的,CN的信息在各个分区中就很难评估,这个时候优化器评判的基准也有一定的限制了。
当然,查看这个索引的并行度的时候发现竟然是12,可见之前也有同学尝试改进过这个问题,似乎从并行上下工夫了。
SQL> SELECT DEGREE FROM DBA_INDEXES WHERE INDEX_NAME='IND_TES_BILLDETAIL_CN';
12
当然这个的效果也有,但是解决的力度还是不大。
我们加入hint先来看看效果。
EXPLAIN PLAN FOR SELECT /*+INDEX(TES_BILLDETAIL IND_TES_BILLDETAIL_CN)*/ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_BILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME)
发现索引能够正常启用,而且cost也不高,就按照这个方子来试试。
如果想有一种更好更全面的改进,就是添加复合索引,但是有一些隐患,一来这个表实在太大了,加索引时间,资源都是很大的消耗,二来更重要的是不确定添加索引之后会对其它的语句有很大的影响,所以为了保险起见,我先修改这两个相关的sql,修改它的执行计划,在线就可以做,如果不合适,撤销就可以。
修改执行计划可以使用sqlt来做,coe提供的这套工具还是很不错的。
因为里面有绑定变量,所以尝试用下面的方式来做。
declare
cursor temp_cur is select '582891946' id from dual;
begin
for i in temp_cur loop
execute immediate 'SELECT /*+INDEX(TES_BILLDETAIL IND_TES_BILLDETAIL_CN)*/ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_BILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME) '
using i.id;
end loop;
end;
/
SQL> @a.sql
PL/SQL procedure successfully completed.
然后从v$sql里面去抓取,可以找到修改后的sql的sql_id
SQL_ID SQL_FULLTEXT
------------- ----------------------------------------------------------------------------------------------------
9h0kr4s3365mt SELECT /*+INDEX(TES_BILLDETAIL IND_TES_BILLDETAIL_CN)*/ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG
FROM TES_BILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN = :1 GROUP BY TRUNC(END_TIME)
所以sql_id 9h0kr4s3365mt就是我们努力的目标,使用提供的脚本来得到执行计划的profile信息。输入sql_id和hash_value即可。
SQL>@coe_xfr_sql_profile.sql
Parameter 1:
SQL_ID (required)
Enter value for 1: 8tmf11fvxy09j
PLAN_HASH_VALUE AVG_ET_SECS
--------------- -----------
2129377450 70.743
Parameter 2:
PLAN_HASH_VALUE (required)
Enter value for 2: 2129377450
Values passed to coe_xfr_sql_profile:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
SQL_ID : "8tmf11fvxy09j"
PLAN_HASH_VALUE: "2129377450"
然后输入修改后的sql_id,也得到一个执行计划的proifle信息,我们需要做一个置换。
SQL> @coe_xfr_sql_profile.sql
Parameter 1:
SQL_ID (required)
Enter value for 1: 9h0kr4s3365mt
PLAN_HASH_VALUE AVG_ET_SECS
--------------- -----------
3361841277 .003
Parameter 2:
PLAN_HASH_VALUE (required)
Enter value for 2: 3361841277
Values passed to coe_xfr_sql_profile:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
SQL_ID : "9h0kr4s3365mt"
PLAN_HASH_VALUE: "3361841277"
得到的关于hint部分的信息如下,原来的sql中的信息为:
h := SYS.SQLPROF_ATTR(
q'[BEGIN_OUTLINE_DATA]',
q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
q'[OPTIMIZER_FEATURES_ENABLE('11.2.0.3')]',
q'[DB_VERSION('11.2.0.3')]',
q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
q'[OPT_PARAM('optimizer_index_caching' 90)]',
q'[ALL_ROWS]',
q'[OUTLINE_LEAF(@"SEL$1")]',
q'[INDEX_RS_ASC(@"SEL$1" "TES_BILLDETAIL"@"SEL$1" ("TES_BILLDETAIL"."CN"))]',
q'[USE_HASH_AGGREGATION(@"SEL$1")]',
q'[END_OUTLINE_DATA]');
添加了hint之后启用了CN相关的索引的hint信息如下:
h := SYS.SQLPROF_ATTR(
q'[BEGIN_OUTLINE_DATA]',
q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
q'[OPTIMIZER_FEATURES_ENABLE('11.2.0.3')]',
q'[DB_VERSION('11.2.0.3')]',
q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
q'[OPT_PARAM('optimizer_index_caching' 90)]',
q'[ALL_ROWS]',
q'[OUTLINE_LEAF(@"SEL$1")]',
q'[INDEX_RS_ASC(@"SEL$1" "TES_BILLDETAIL"@"SEL$1" ("TES_BILLDETAIL"."CN"))]',
q'[USE_HASH_AGGREGATION(@"SEL$1")]',
q'[END_OUTLINE_DATA]');
需要把这部分内容替换原来sqlprofile中的hint部分。
拷贝替换之后,就可以生成sqlprofile了,运行脚本的结果如下:
SQL> DECLARE
2 sql_txt CLOB;
3 h SYS.SQLPROF_ATTR;
4 PROCEDURE wa (p_line IN VARCHAR2) IS
5 BEGIN
6 DBMS_LOB.WRITEAPPEND(sql_txt, LENGTH(p_line), p_line);
7 END wa;
8 BEGIN
9 DBMS_LOB.CREATETEMPORARY(sql_txt, TRUE);
10 DBMS_LOB.OPEN(sql_txt, DBMS_LOB.LOB_READWRITE);
11 -- SQL Text pieces below do not have to be of same length.
12 -- So if you edit SQL Text (i.e. removing temporary Hints),
13 -- there is no need to edit or re-align unmodified pieces.
14 wa(q'[ SELECT ROUND(AVG(SUM(END_TIME-START_TIME)*1440)) AVG FROM TES_B]');
15 wa(q'[ILLDETAIL WHERE END_TIME > TRUNC(SYSDATE - 30) AND CN ]');
16 wa(q'[= :1 GROUP BY TRUNC(END_TIME) ]');
17 DBMS_LOB.CLOSE(sql_txt);
18 h := SYS.SQLPROF_ATTR(
19 q'[BEGIN_OUTLINE_DATA]',
20 q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
21 q'[OPTIMIZER_FEATURES_ENABLE('11.2.0.3')]',
22 q'[DB_VERSION('11.2.0.3')]',
23 q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
24 q'[OPT_PARAM('optimizer_index_caching' 90)]',
25 q'[ALL_ROWS]',
26 q'[OUTLINE_LEAF(@"SEL$1")]',
27 q'[INDEX_RS_ASC(@"SEL$1" "TES_BILLDETAIL"@"SEL$1" ("TES_BILLDETAIL"."CN"))]',
28 q'[USE_HASH_AGGREGATION(@"SEL$1")]',
29 q'[END_OUTLINE_DATA]');
30 :signature := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt);
31 :signaturef := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt, TRUE);
32 DBMS_SQLTUNE.IMPORT_SQL_PROFILE (
33 sql_text => sql_txt,
34 profile => h,
35 name => 'coe_8tmf11fvxy09j_2129377450',
36 description => 'coe 8tmf11fvxy09j 2129377450 '||:signature||' '||:signaturef||'',
37 category => 'DEFAULT',
38 validate => TRUE,
39 replace => TRUE,
40 force_match => FALSE /* TRUE:FORCE (match even when different literals in SQL). FALSE:EXACT (similar to CURSOR_SHARING) */ );
41 DBMS_LOB.FREETEMPORARY(sql_txt);
42 END;
43 /
PL/SQL procedure successfully completed.
SQL> WHENEVER SQLERROR CONTINUE
SQL> SET ECHO OFF;
SIGNATURE
---------------------
4228059721940760383
SIGNATUREF
---------------------
4228059721940760383
... manual custom SQL Profile has been created
COE_XFR_SQL_PROFILE_8tmf11fvxy09j_2129377450 completed
sql profile已经启用了,再次查看就可以看到已经生效了。
SQL> SELECT *FROM TABLE(DBMS_XPLAN.DISPLAY);
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------
Plan hash value: 3361841277
------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 32 | 41 (3)| 00:00:01 | | |
| 1 | SORT AGGREGATE | | 1 | 32 | 41 (3)| 00:00:01 | | |
| 2 | HASH GROUP BY | | 1 | 32 | 41 (3)| 00:00:01 | | |
| 3 | PARTITION RANGE ITERATOR | | 1 | 32 | 40 (0)| 00:00:01 | KEY | 970 |
|* 4 | TABLE ACCESS BY LOCAL INDEX ROWID| TES_BILLDETAIL | 1 | 32 | 40 (0)| 00:00:01 | KEY | 970 |
|* 5 | INDEX RANGE SCAN | IND_TES_BILLDETAIL_CN | 42 | | 35 (0)| 00:00:01 | KEY | 970 |
PLAN_TABLE_OUTPUT
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("END_TIME">TRUNC(SYSDATE@!-30))
5 - access("CN"=:1)
Note
-----
- SQL profile "coe_8tmf11fvxy09j_2129377450" used for this statement
按照这个思路,又对另外两个sql进行类类似的分析,结果也是使用Hint来调整,使用sql monitor来查看实时的执行计划情况,使用sqlt来修改执行计划。
调优之后的效果还是很明显的。DB time大大降低,逻辑读的效果更加明显。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

