容器监控的工具和流程
【编者的话】在容器和微服务场景中,监控解决方案有很多种,包括Docker原生的Stats API和命令、cAdvisor,还有Prometheus和Sysdig这样相对复杂和功能强大的工具,除此之外还有很多供应商提供的解决方案。
随着容器和微服务的引入,监控解决方案必须处理比以往任何时候都要更多的短生命周期服务和服务实例。虽然基础设施的场景发生了变化,运维团队仍然需要在中央处理器(CPU)、随机存取存储器(RAM)、硬盘驱动器(HDD)、网络利用率以及应用程序节点的可用性等方面监控相同的信息。
虽然您可以为传统的基础设施使用旧工具或现有的监控服务,现在有更新的基于云的服务可以确保在服务被构建和监控时监控解决方案是可伸缩的。许多基于云的和自托管的工具都是为容器而设计的。不管您使用什么解决方案或服务,你仍然需要知道如何收集你正想监控的度量指标。
当从你的容器收集度量标准时,有相当多的选项。本文考察了一些对于容器监控有用的软件和服务。我们已经引入了一个混合了自托管的开源解决方案以及商业的云服务的方式,以反映当前的场景。然而,重要的是要记住,与各种各样的可用的解决方案相比,我们引入的还是相对少量的例子。这些例子的目的是展示几种不同的方法来解决收集度量指标的问题。
Docker
Docker Engine本身就提供了访问大部分的我们正想收集的可以作为原生监控功能的核心度量指标的能力。运行 docker stats 命令可以访问运行在你的主机上的所有容器的CPU、内存、网络和磁盘利用率。


图1:运行docker stats命令
如果你需要在任何给定的时刻获得有关容器的快速概况,那么数据是自动流动的并且是有用的,比如您可以添加一些flag:
● flag -all 显示你停止了容器,尽管你看不到任何度量指标
● flag -no-stream 显示第一个运行的输出,然后停止度量指标的数据流
这种方式有一些缺点,第一个就是数据没有在任何地方存储——你不能回溯并审查度量指标。另外就是会非常乏味地在没有参考点的情况下看着一个个不断刷新的端点,很难定位数据中有什么奥秘。
幸运的是, docker stats 命令实际上是一个对于stats应用程序接口(API)端点的命令行界面,stats API暴露了stats命令所有的信息甚至更多。要亲自查看,请运行以下命令:
curl --unix-socket /var/run/docker.sock http:/containers/container_name/stats
正如你从输出中看到的,会有更多的返回信息,它们都是以JSON Array封装的并且可以被第三方工具所接纳。
cAdvisor
cAdvisor是来自Google的原生支持Docker容器的监控工具,这是一个收集、整合、处理以及输出当前运行容器信息的守护进程,cAdvisor其实就是如果你运行docker stats -all命令所获得的信息的图形化版本,这也是理解cAdvisor的最佳方式。
docker run /
--volume=/:/rootfs:ro /
--volume=/var/run:/var/run:rw /
--volume=/sys:/sys:ro /
--volume=/var/lib/docker/:/var/lib/docker:ro /
--publish=8080:8080 /
--detach=true /
--name=cadvisor /
google/cadvisor:latest
cAdvisor容易启动和运行,因为它是在一个容器里交付的。你所需要做的只是运行上述的命令就可以启动cAdvisor容器并在端口8080上公开web界面。
一旦启动之后,cAdvisor会在运行在宿主机上的Docker Daemon里打入一个它自身的钩子并且立即开始收集你所有的正运行的容器的度量指标,包括cAdvisor容器自身在内 。在浏览器中打开 http://localhost:8080/ 将会带你直接到web界面。

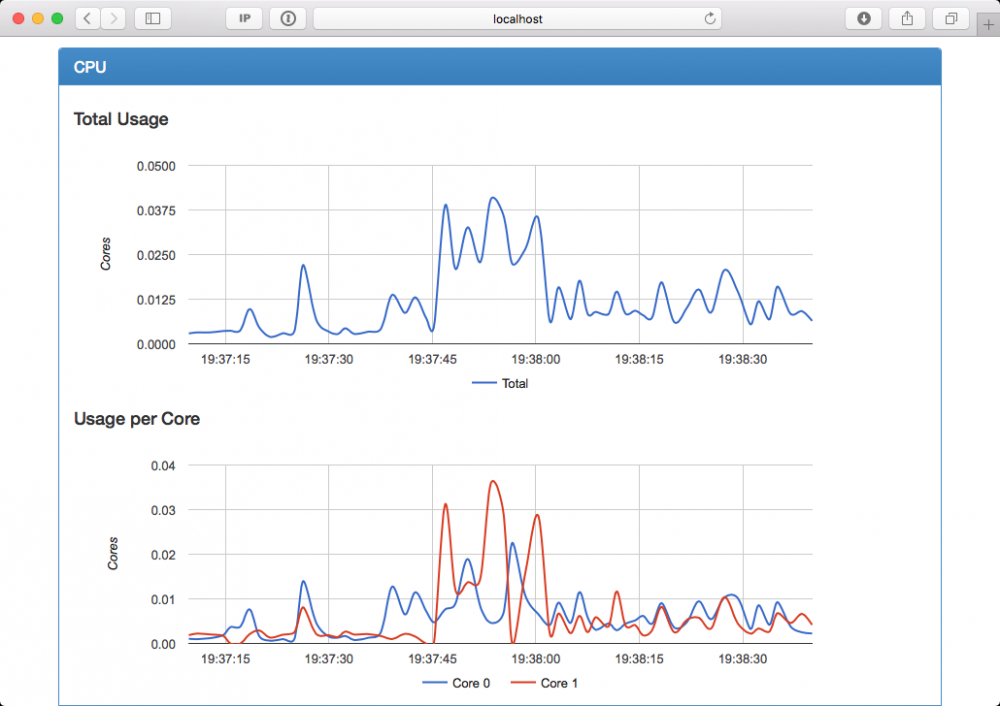
图2:访问本地的web界面
正如你从图2中看到的,里边有着一分钟的实时数据流,然而,鉴于这个只是cAdvisor的标准安装,你不能观察到更多深入的度量指标。幸运的是,Google已经通过引入一些选项来从cAdvisor导出数据到时间序列数据库比如Elasticsearch、influxDB、BigQueery和Prometheus。
总而言之,cAdvisor是一个很棒的快速洞悉正在运行的容器所发生的一切的工具,它安装非常简单,并能赋予你比开箱即用的Docker更细粒度的度量指标。它也可以作为一个其它工具的监控代理,同样的方式在过去Zabbix或Nagios代理也使用过的。
Prometheus
Prometheus是一个开源的监控系统和时间序列数据库,最初是由SoundCloud搭建的,目前这是由云原生计算基金会(CNCF)托管的,同样的项目还有K8S和OpenTracing。在阅读服务描述时,可能听起来很像传统的服务和代理设置,然而,Prometheus的工作方式是不同的,它从主机上的数据节点刮取数据并存储到它自己的时间序列数据库而不是它自己的代理。
在2016年10月底,一个在Docker Engine本身内部公开度量指标端点的pull request被合并了。这可能意味着即将发布的Docker新版本将会开箱即用的支持Prometheus刮取容器度量指标的功能,然而在新版本发布之前,你仍然需要使用中介服务诸如cAdvisor。截止到1.13版本,Docker Engine支持可选的“/metrics”Prometheus端点。目前重要的是要注意,这会暴露内部的Docker度量指标而不是容器度量指标。目前正在进行的讨论是将其扩展到涵盖容器度量指标,甚至可能完全取代Stats API。
Prometheus最大的优势是可以作为数据源。你可以在前面用Prometheus与Grafana刮取数据,其中Grafana在2015年年中就开始支持Prometheus了,现在是Prometheus推荐的前置系统。类似于大多数我们看到的工具,Grafana也可以作为容器启动。
一旦启动并运行后,唯一需要的配置是添加你的Prometheus URL作为数据源,然后导入一个预定义的Prometheus Dashboard。

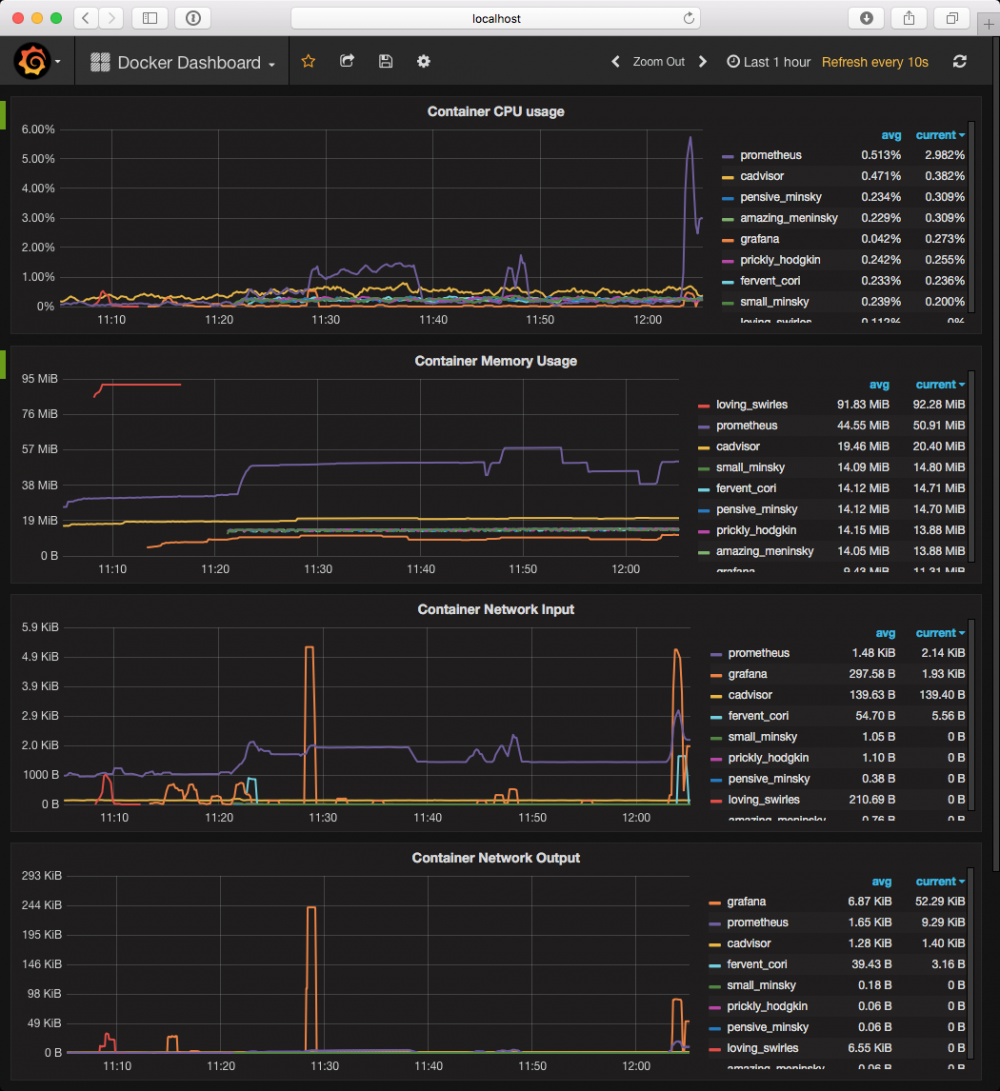
图3:度量指标存储在Prometheus中并用Grafana中显示
图3的Dashboard显示了来自于cAdvisor并存储在Prometheus用Grafana渲染的超过一个多小时信息,Prometheus基本上是以当前cAdvisor的状态作为快照的,它也记录了早已删除的容器的度量指标。
Prometheus还具有告警功能,通过使用内置的上报语言,你可以创建如下的告警:
ALERT InstanceDown
IF up == 0
FOR 5m
LABELS { severity = "page" }
ANNOTATIONS {
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.",
}
一旦告警已经写完并在Prometheus服务器上部署,你可以使用Prometheus Alertmanager来路由你的告警。上面的例子中,我们已经指定了一个标签severity = “page”,Alertmanager将会拦截告警并转发告警到一个服务比如PagerDuty、OpsGenie、一个Slack或者HipChat channel,或者任意数量的不同端点。
Prometheus是一个强大的平台,并且作为不同技术的中间人表现优异。它可以非常容易从类似于上述的一个基本的安装开始起步,然后进行扩展,赋予一个单一的窗格视图可以同时获得你的容器和宿主机实例信息。
无代理的系统爬虫
无代理的系统爬虫(ASC)是一个来自于IBM的支持容器的云监控工具。它从运行的容器收集监控信息,包括度量指标、系统状态和配置信息。ASC提供了对于容器的深度可见性,不仅仅是利用率和性能指标,还有安全和配置分析。它被设计成一个管道,用于为容器构建收集插件,为动态的数据聚合或分析提供功能插件,以及为目标监控和分析端点提供输出插件。提供的插件包括了传统的数据收集功能比如利用率指标、容器内运行的进程及监听的端口,还有与配置文件和应用包相关的数据。
ASC可以部署作为一个Python包或者作为一个单独的具备特权的容器,例如,ASC可以与Docker Daemon、容器cgroup和namespace交互,这里是如何以容器方式方式启动ASC:
docker run /
--privileged /
--net=host /
--pid=host /
-v /cgroup:/cgroup:ro /
-v /var/lib/docker:/var/lib/docker:ro /
-v /sys/fs/cgroup:/sys/fs/cgroup:ro /
-v /var/run/docker.sock:/var/run/docker.sock /
-it crawler --crawlmode OUTCONTAINER ${CRAWLER_ARGS}
一旦运行后,它就会向Docker Daemon订阅事件并周期性地监控系统内运行的所有容器。ASC可以非常容易地利用插件为定制化数据收集进行扩展,有助于收集容器和环境的信息。每一个插件都可以为一个特定的监控功能简单地导出一个crawl()方法,ASC迭代每一个被在部署配置中启用的收集插件实现的crawl()方法。ASC当前可以被配置为导出数据到Kafka、Graphite、文件系统和控制台端点以及允许额外的输出插件。图4展示了一个从ASC配置的视图例子,将容器数据导出到一个Graphite/Grafana端点。

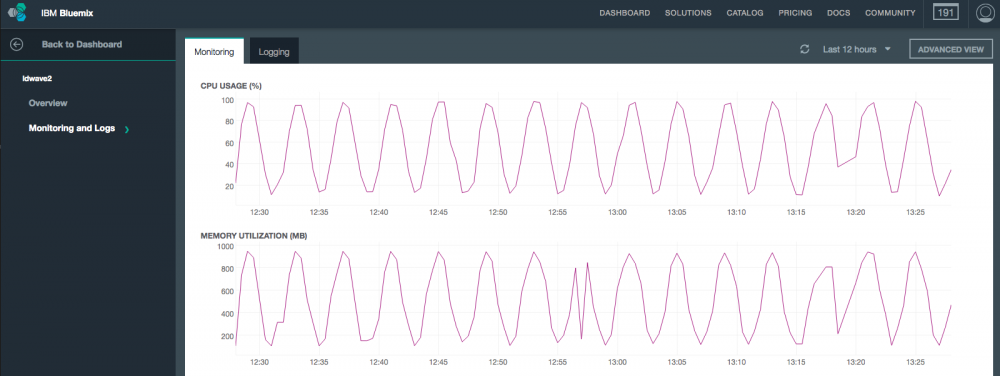
图4:ASC借助于Graphite/Grafana监控容器的视图
ASC的一个使用案例就是获得更深层次的容器执行的信息,下面的例子显示了当配置为除了基础度量指标之外还收集容器的进程和连接特性时的ASC的基本输出帧。基于这个帧,我们可以看到这是一个CPU占用率为100%的容器,其中有一个Python进程监听5000端口。
metadata "metadata" {"id":"ef0fc187dc0a4b85a3cb", …}
cpu "cpu-0" {… ,"cpu_util":100.0}
process "python/1" {"cmd":"python web.py",...
"python","pid":74, …}
connection "74/127.0.0.1/5000"...
{"pid":74,…,"connstatus":"LISTEN"}
这使用户能够将监控与系统状态耦合,更好地了解容器的行为,并推动额外的分析。比如,我们可以更加深入挖掘容器中使用的Python进程,并在本例中通过启用另外一个功能插件“python-package”来追踪应用使用的底层Python包,该插件赋予了我们额外的可以洞悉应用中已使用的包和版本的信息的能力:
python-package "click" {"ver":"6.6","pkgname":"click"}
python-package "Flask" {"ver":"0.11.1","pkgname":"Flask"}
python-package "itsdangerous"{"ver":"0.24",...
"pkgname":"itsdangerous"}
python-package "Jinja2" {"ver":"2.8","pkgname":"Jinja2"}
python-package "pip" {"ver":"8.1.2","pkgname":"pip"}
python-package "setuptools" {"ver":"20.8.0",...
"pkgname":"setuptools"}
python-package "Werkzeug" {"ver":"0.11.11",...
"pkgname":"Werkzeug"}
总之,ASC是一个易于安装和使用的工具,类似于cAdvisor来获得当前运行的容器内部的信息。除了基本的监控度量指标外,ASC还把重点放在了容器状态和配置的深度可见性方面,从而启用了监控、安全和其它的分析解决方案。它为数据收集的可扩展性和不同端点的支持提供了一个简单的、基于插件的方式。
Sysdig
Sysdig有两个不同的版本,第一个是在宿主机上安装了一个内核模块的开源版本,第二个是名为Sysdig Cloud的云和本地解决方案,其使用开源版本并且将收集的度量指标流向到Sysdig自己的服务器。
开源Sysdig
Sysdig的开源版本就像运行Docker stats命令,服务会在宿主机内核打钩,这意味着它完全不用依赖从Docker Damon来获得度量指标。
使用Csysdig这个内置的基于ncurses的命令行接口,你可以查看你的宿主机的各种各样的信息。举例来说,运行csysdig -vcontainers命令可以获得图5的视图。

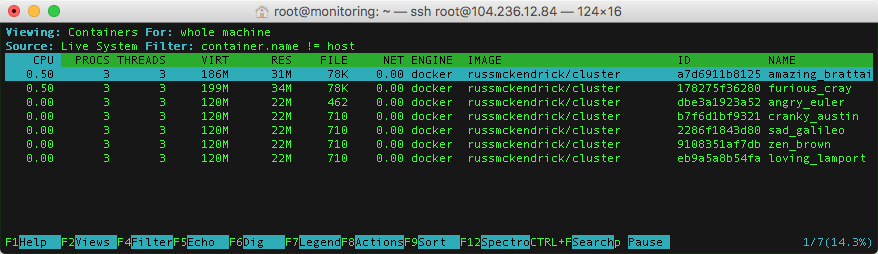
图5:使用Sysdig的命令行接口
正如您可以看到的,这里展示了宿主机上运行的所有容器,你还可以进入容器内部来查看单个进程所消耗的资源。就像运行docker stats命令和使用cAdvisor一样,Sysdig的开源版本也是可以获得你的容器的实时视图的,然而,你可以使用如下的命令来记录和回放系统活动:
● sysdig -w trace.scap命令记录系统活动到一个跟踪文件。
● csysdig -r trace.scap命令回放跟踪文件。
Sysdig的开源版本不是传统监控工具,它允许你深入你的容器,获得更广泛的信息。它还允许你通过直接在你的编排系统打钩来添加编排上下文环境,从而允许你对Pod、集群、namespace以及其它方面进行故障排除。
Sysdig Cloud
Sysdig Cloud获得开源版本抓取的所有数据后并用强大的Dashboard展示出来,该Dashboard具备告警功能。在图6中,你可以看到一个显示容器使用率实时视图的Dashboard,你也可以深入到单独的进程。

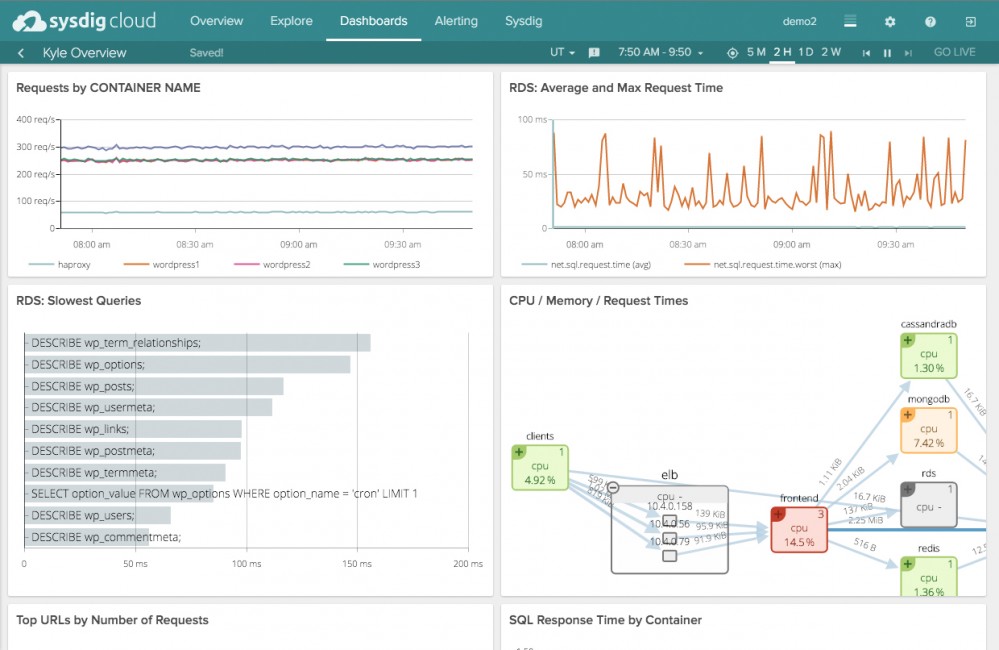
图6:Sysdig Cloud中的Dashboard视图
举例来说,使用Docker Compose运行WordPress会启动两个容器:一个运行Apache及WordPress的PHP代码,另外一个运行MySql数据库。使用Sysdig Cloud,你可以应用过滤器来深入探讨数据库是如何执行的,允许你定位一些状况,比如较慢的查询或者哪些查询运行的最多。
最常见的服务也有类似的过滤器,比如Nginx、PHP-FPM、PostgreSQL、MongoDB和Apache Tomcat。这些过滤器和度量指标告警可以在任何时刻添加。这些告警在触发时可以被分发到诸如Slack或者PagerDuty这样的服务,并且会自动生成系统活动记录。当需要调查故障时,有一个详细信息级别的快照是非常有价值的。
收集数据的其它工具
如前所述,有相当多的服务可以收集、核对和上报来自容器和宿主机实例的度量指标,我们已经创建了其他可用工具的概述,在容器监控目录中列出了更多。
供应商 解决方案描述
CoScale CoScale是一个全栈的监控云服务,其可以监控应用程序的响应能力。它用特定应用程序的性能指标整合了服务器和容器资源指标,其轻量级的代理是几乎没有开销的。
Datadog Datadog对于IT运维和开发团队是一个全栈的云监控和告警服务,它具有容器化的代理可以监控容器环境。
Dynatrace Dynatrace在立足于Ruxit技术的基础之上具有一套新的监控工具,可以针对容器监控和告警。它的代理是注入到一个容器里的,在其中可以重新发现新的运行在宿主机上的服务并从Docker API中获取数据。Dynatrace也正在开发人工智能来帮助进行根本原因的分析。
Elastic Beats是一个专用的数据交付工具,它安装为一个轻量级的代理并且从机器发送数据到Logstash或者Elasticssearch。Dockerbeat是针对Docker容器的交付工具。如同大多数的Elasticsearch安装,你可以在数据前部使用Kibana Dashboard。X-Pack是一个全栈的监控订阅,其增加了额外的功能比如告警上报到Elastic Stack(以前称之为ELK Stack)。
influxData Telegraf是一个开源的代理,其通过Docker插件来收集度量指标。它是堆栈的一部分,influxData被创建出来收集和分析度量指标,这些度量指标发送到了influxDB或者多种输出渠道。
New Relic New Relic已经围绕它们的数字化智能平台为应用和基础设施性能更新了产品系列。它的基于代理的方式特别适合定位分析应用程序与代码相关的性能问题。
Sematext Sematext有一个Docker原生的监控和日志收集代理,其可以为所有的集群节点和自动发现的容器收集和处理Docker度量指标、事件和日志。它有自己的日志管理解决方案以及性能监控服务。
SignalFx SignalFx的collectd-docker插件使用Docker的stats API来抓取有关CPU、内存、网络和磁盘的度量指标。SignalFx有一个内置的Docker监控Dashboard,其会引导你按照属性添加维度(tag)元数据到聚合、过滤以及分组度量指标中。
结论
我们所涵盖的所有工具将能够让您能够开启容器可见性和监控。它将由你决定需要组合什么样的工具来收集信息,这将有助于您监控和优化应用程序和系统。我们涵盖了每个人都需要知道的基本知识,包括使用Docker的Stats API原生功能和cAdvisor。要向用户介绍基本的容器监控必需品还需要很长的路要走。我们还引入了更新的解决方案比如Prometheus和Sysdig。
有很多种方法来监控容器,并且解决方案供应商对于这些问题都有他们自己的固执己见的解决方法。你可能会认为是从开源和SaaS解决方案中选择一个,但是更多的还是需要寻找一个适合你的工作负载的混合解决方案。无论你如何最终构建监控堆栈,你仍然需要知道如何收集你想监控的度量指标。
原文链接:TOOLS AND PROCESSES FOR MONITORING CONTAINERS(翻译:胡震)
正文到此结束
- 本文标签: root 端口 进程 基金 时间 软件 php-fpm python id PHP cmd 数据库 配置 代码 插件 src ACE 文件系统 web IBM description 安装 Google list lib Word IO apache unix sql API Docker Connection 生命 自动生成 目录 定制 js 安全 管理 json 开源 删除 处理器 云 翻译 ip 集群 CSS 实例 性能问题 http Job mysql 服务器 tomcat cat 数据 MongoDB 开发 主机 IOS wordpress Nginx db 产品 UI 智能 解决方法 ask 2015
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

