Docker帮助数据科学敏捷化
【编者的话】本文介绍了Domino如何使用Docker来帮助科学家和研究人员解决环境敏捷性和可重现的问题。
背景
在Domino,我们非常依赖Docker技术。尽管大多数关于Docker的讨论都集中在如何使用Docker来发布他们的软件,但我们在自己的产品中使用Docker,以允许数据科学家轻松地管理他们所用的工作环境(如包、库等)。换句话说,除了在内部使用Docker作为DevOps工具外,我们还将Docker暴露为面向用户的功能。
大家可能不太了解Domino,简单地说,它是一个供数据科学家运行他们的代码(例如R语言、Python语言等),跟踪他们的实验,分享他们的工作和部署模型的平台。集中的基础设施和知识管理使得数据科学家工作更有效率,以实现可重用、协作的数据科学。
环境管理的问题
研究人员和数据科学家的一个共同痛点是“环境管理”。我使用这个词来描述与软件包安装、配置设置等一些单独或者团队分析工作相关的问题。我们最常见的一些问题是:
- 研究人员通常在中央IT上面临瓶颈,无法安装新的软件包。如果安装软件包太慢或者太耗时,组织将无法紧跟最新的技术和工具。现在开源生态系统比以外任何时候都有更快速的发展,组织需要有足够的敏捷性来测试和使用新的技术和方法。
- 新的软件包被搁置。由于缓慢或官僚过程可能会延缓标准工具和软件包(例如新版本的R、Python等)的更新,导致关键组件过期。
- 由于不同用户的环境不同(例如包含不同版本的软件包),相同的代码不同人使用结果不同,甚至有时根本不能用。
- 新人入职时会有很大阻碍,因为配置他们的工作环境需要很长的时间。
- 旧项目不再可用,旧的运行结果不可再现,因为代码编写后环境已经发生了变化。
- 升级(例如更改底层版本的R或Python,或者升级特定的软件包)是有风险的,因为很难确定什么将停止工作。
通常,公司使用下面两种方式进行环境管理,然而每种方法都解决了一些问题,也加剧了一些:
- 公司让用户自己管理自己的环境。这给用户带来了灵活性和敏捷性,但这不可避免地导致了环境不一致。这样意味着研究人员的机器上的工作是孤立的,使其难以共享和协作,也制约了用户可使用的计算资源。
- 公司锁定中央环境,例如大型共享的研究用服务器,IT部门负责管理这些机器,用户可以访问一致的环境,但是这些环境很难更改。
基于Docker构建计算环境
Domino定义了计算环境的一级概念:计算环境(Compute Environment)是指包含用于运行分析计算代码的一组软件和配置文件。这样做有以下几个原因:
- 环境和代码所在的项目相关联。因此如果有人在12个月后重新访问一个项目或者一个新员工加入一个项目,可以确保代码按照预期地工作,不管计算机上安装了什么。
- 研究人员可以修改他们的环境,升级或者安装新的库,而无需通过IT部门。最关键的是,这样做不会影响其他人的环境。
- 与研究人员自己管理机器不同,Domino的环境是集中存储和管理的。研究人员可以轻松地共享环境,并且可以同时为所有人升级环境。
在底层,计算环境建立在Docker镜像之上,当研究人员运行代码时,他们的代码在从此镜像启动的容器中运行。
使用Docker后系统非常强大,因为它允许我们保存过去版本的镜像,以便我们可以记录用于生成任何过去结果的确切环境。
新能力
我们来看一下这个设计下的工作流。
使用不同版本的基础工具
假如你的一些用户使用Python3,一些使用Python2。或者一些用户使用标准R发行版,一些使用Revolution Analytics的R发行版。你可以为每个配置创建环境,数据科学家可以选择他们工作时所需要的:
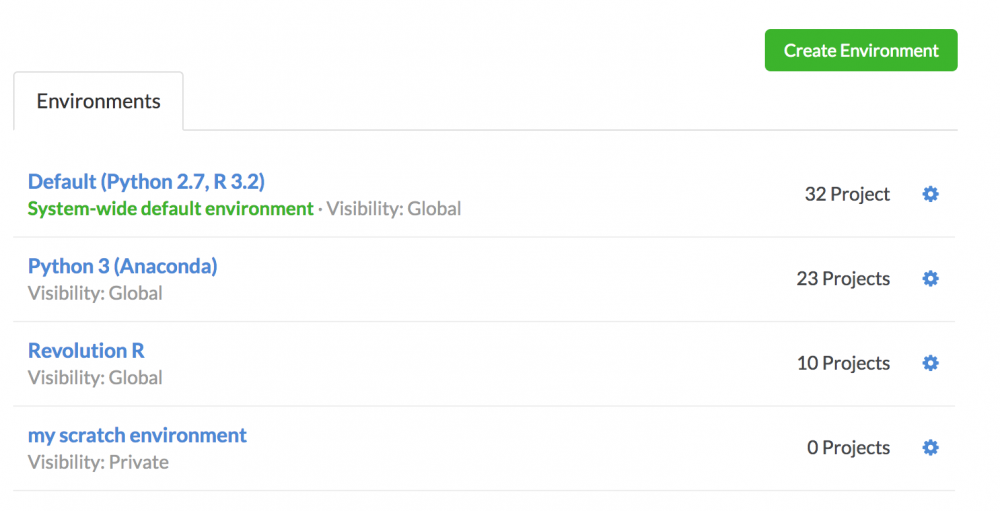
可以在你的组织内创建任意多的环境,并管理他们的共享和权限,以便在组织内创建各种标准环境选择。
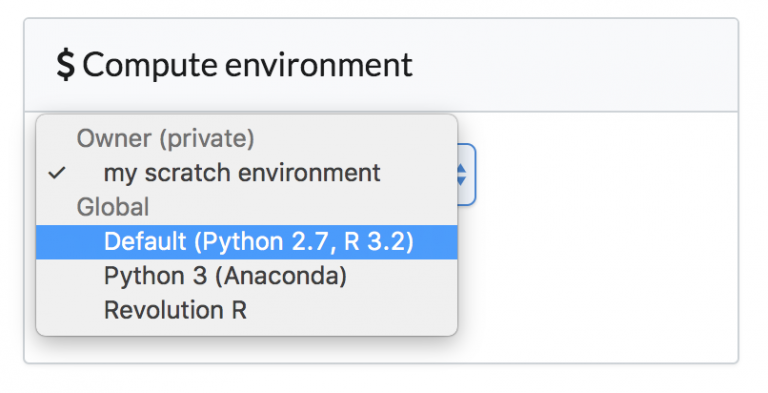
升级关建库
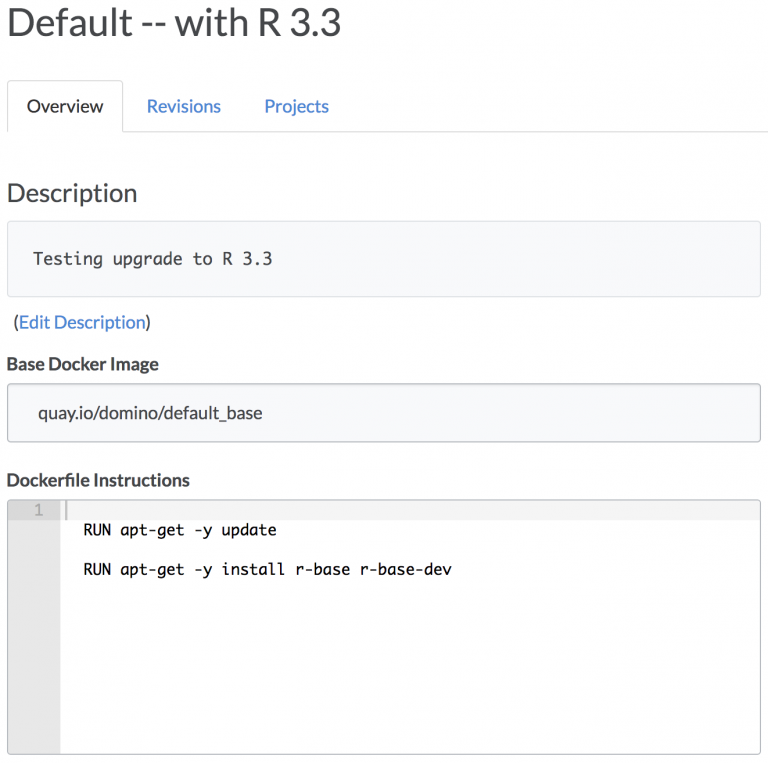
Domino允许通过运行Docker命令来指定环境的内容。为了更好的展示它,我们假设默认环境是R 3.2版本,而你想升级到R 3.3。出于谨慎,我们可以先在自己的项目上测试这个更改,以验证它是否能正常工作,然后再推送给大家。
我们可以创建一个默认环境的副本,并添加我们想要运行的任何Docker命令。
现在仅需修改我们项目使用的环境并重新运行代码即可。
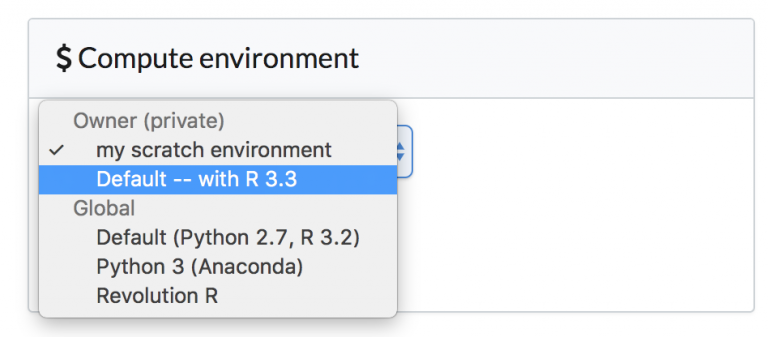
通过运行回归测试脚本,当我改变了运行环境后,可以通过重新运行该脚本来确定是否可以正常地工作。最关键的是,我可以重新运行上次运行的环境版本,所以我可以确定任何结果的差异是由于R升级导致的,而不是我的代码更改导致的。
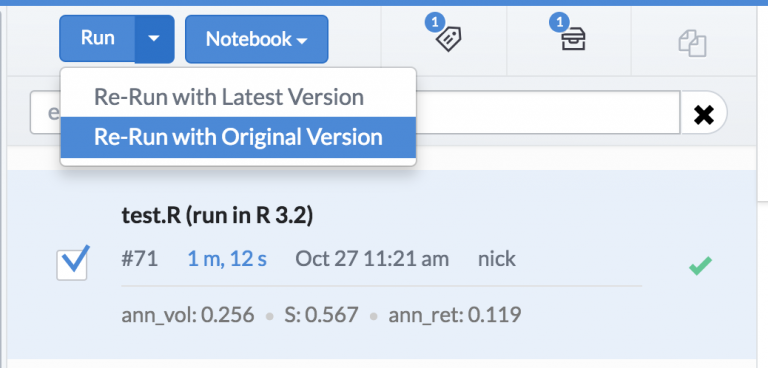
我们甚至可以比较不同环境的运行结果,确保没有发生变化。
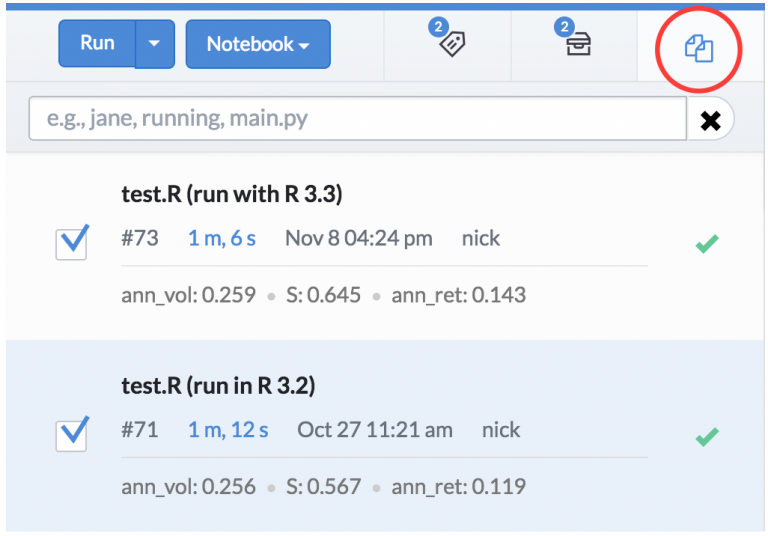
有关如何比较Domino重不同实验结果的更深入讨论,请查看我们的文章 “unit testing” for data science 和 model tuning and experimentation 。
重新生成旧结果
除了为数据科学家提供更多的敏捷性之外,Domino还对代码的每次执行都保持了一个不可变的记录,包括运行环境的信息。因此很容易找到和恢复指定的环境来重现过去的任何结果。
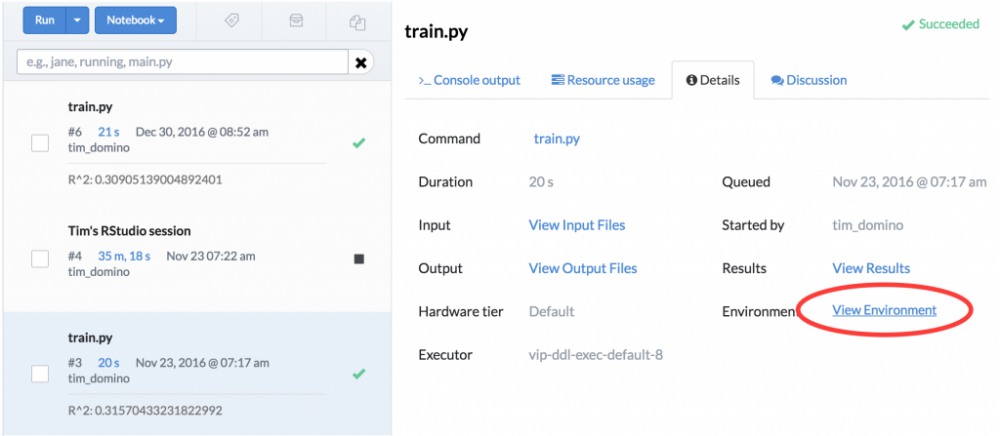
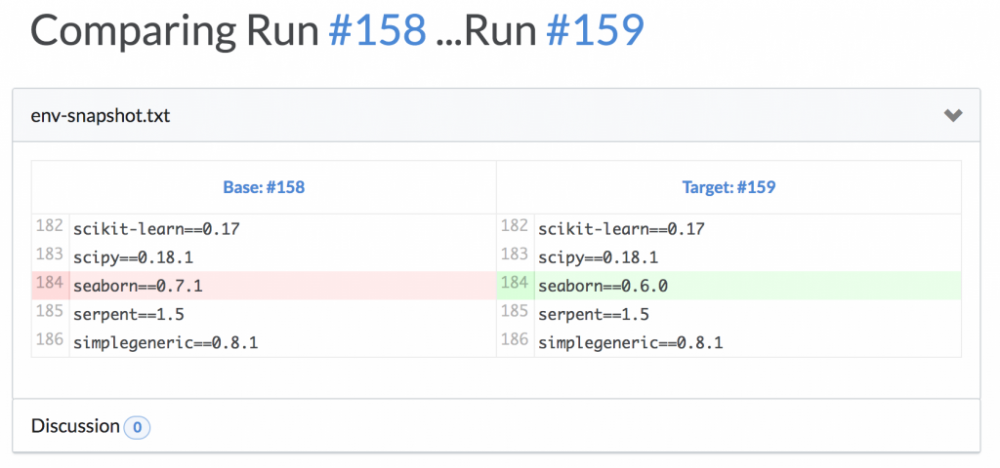
更进一步的,除了在更改环境后比较实验结果之外,Domino还可以配置为在代码运行时保留环境状态的文本快照,这样可以允许我们通过差异比较来快速找出哪些包或软件可能在同一实验的两次不同运行之间更改。
结论
Docker是一个非常强大的技术。除了允许DevOps团队启用新的工作流外,它还可以优雅地解决数据科学家每天面临的问题。以Docker为基础,Domino的计算环境功能使得研究人员能够轻松地实验新软件包而不会破坏同事环境的稳定性。同时,计算环境使研究人员能够在一致的软件和软件包的环境中再现和审核修改。
原文链接: Enabling Data Science Agility with Docker (翻译:刘思贤)
===========================================
译者介绍
刘思贤,爱油科技架构师,PMP,关注互联网相关技术与软件项目管理,是一名DevOps实践者,乐于整理和分享一些实践经验。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

