ZGC,一个超乎想象的垃圾收集器
Z Garbage Collector,即ZGC,是一个可伸缩的、低延迟的垃圾收集器,主要为了满足如下目标进行设计:
- 停顿时间不会超过10ms
- 停顿时间不会随着堆的增大而增大(不管多大的堆都能保持在10ms以下)
- 可支持几百M,甚至几T的堆大小(最大支持4T)
停顿时间在10ms以下,10ms其实是一个很保守的数据,在SPECjbb 2015基准测试,128G的大堆下最大停顿时间才1.68ms,远低于10ms,和G1算法相比,也感觉像是在虐菜。
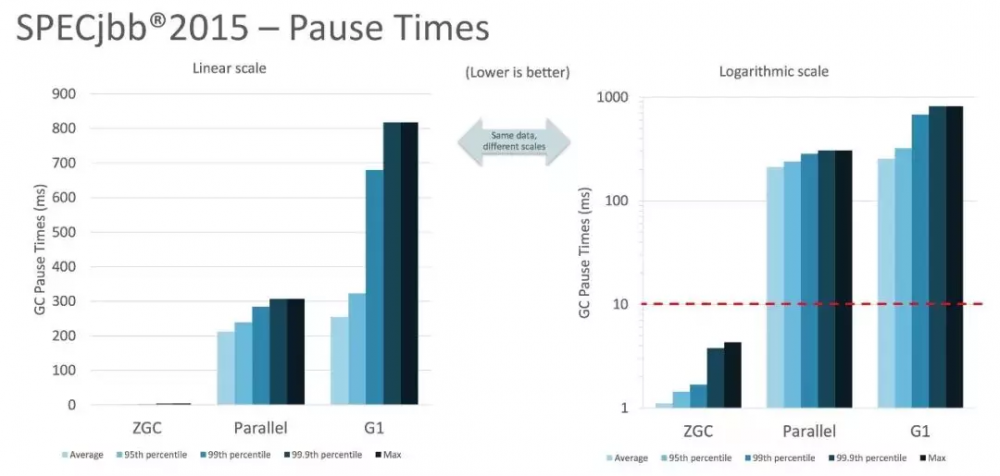
G1算法通过只回收部分Region,避免了全堆扫描,改善了大堆下的停顿时间,但在普通大小的堆里却表现平平,ZGC为什么可以这么优秀,主要是因为以下几个特性。
Concurrent
ZGC只有短暂的STW,大部分的过程都是和应用线程并发执行,比如最耗时的并发标记和并发移动过程。
Region-based
ZGC中没有新生代和老年代的概念,只有一块一块的内存区域page,以page单位进行对象的分配和回收。
Compacting
每次进行GC时,都会对page进行压缩操作,所以完全避免了CMS算法中的碎片化问题。
NUMA-aware
现在多CPU插槽的服务器都是Numa架构,比如两颗CPU插槽(24核),64G内存的服务器,那其中一颗CPU上的12个核,访问从属于它的32G本地内存,要比访问另外32G远端内存要快得多。
ZGC默认支持NUMA架构,在创建对象时,根据当前线程在哪个CPU执行,优先在靠近这个CPU的内存进行分配,这样可以显著的提高性能,在SPEC JBB 2005 基准测试里获得40%的提升。
Using colored pointers
和以往的标记算法比较不同,CMS和G1会在对象的对象头进行标记,而ZGC是标记对象的指针。
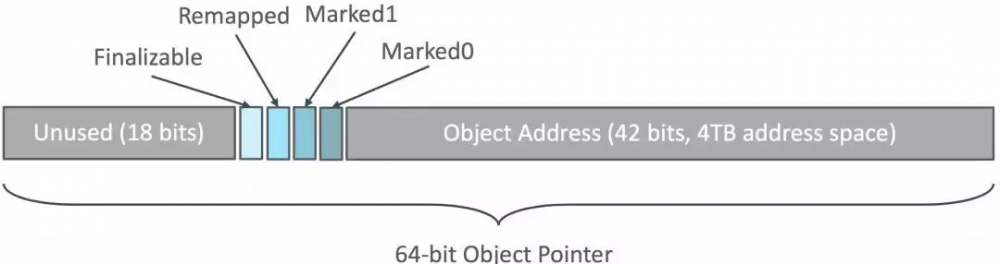
其中低42位对象的地址,42-45位用来做指标标记。
Using load barriers
因为在标记和移动过程中,GC线程和应用线程是并发执行的,所以存在这种情况:对象A内部的引用所指的对象B在标记或者移动状态,为了保证应用线程拿到的B对象是对的,那么在读取B的指针时会经过一个 “load barriers” 读屏障,这个屏障可以保证在执行GC时,数据读取的正确性。
一些变化
JDK11
- ZGC的最初版本
- 不支持类卸载class unloading (using -XX:+ClassUnloading has no effect)
JDK12 - 进一步减少停顿时间
- 支持类卸载功能
平台支持
ZGC目前只在Linux/x64上可用,如果有足够的需求,将来可能会增加对其他平台的支持。
目前只支持64位的linux系统,狼哥在mac跑了半天都是下面的错!

如何编译
$ hg clone https://wiki.openjdk.java.net/display/hg.openjdk.java.net/jdk/jdk $ cd jdk $ sh configure $ make images
如果正在编译的版本是 11.0.0, 11.0.1 or 11.0.2,必须加上配置参数 --with-jvm-features=zgc 开启ZGC的编译,在11.0.3或者12之后,可以忽略这个参数,已经默认支持。
编译结束之后,你会得到一个完整的JDK,在Linux中,可以在下面目录中找到这个新的JDK
./build/linux-x86_64-normal-server-release/images/jdk
可以进入bin文件夹,执行 ./java -version 验证一下。
如何使用
编译完成之后,已经迫不及待的想试试ZGC,需要配置以下JVM参数,才能使用ZGC.
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC -Xmx10g -Xlog:gc
参数说明:
Heap Size
通过 -Xmx10g 进行设置。
-Xmx是ZGC收集器中最重要的调优选项,大大解决了程序员在JVM参数调优上的困扰。ZGC是一个并发收集器,必须要设置一个最大堆的大小,应用需要多大的堆,主要有下面几个考量:
- 对象的分配速率,要保证在GC的时候,堆中有足够的内存分配新对象
- 一般来说,给ZGC的内存越多越好,但是也不能浪费内存,所以要找到一个平衡。
Concurrent GC Threads
通过 -XX:ConcGCThread = 4 进行设置。
并发执行的GC线程数,如果没有设置,在JVM启动的时候会根据CPU的核数计算出一个合理的数量,默认是核数的12.5%,但是根据应用的特性,可以通过手动设置调整。
因为在并发标记和并发移动时,GC线程和应用线程是并发执行的,所以存在抢占CPU的情况,对于一些对延迟比较敏感的应用,这个并发线程数就不能设置的过大,不然会降低应用的吞吐量,并有可能增加应用的延迟,因为GC线程占用了太多的CPU,但是如果设置的太小,就有可能对象的分配速率比垃圾收集的速率来的大,最终导致应用线程停下来等GC线程完成垃圾收集,并释放内存。
一般来说,如果低延迟对应用程序很重要,那么不要这个值不要设置的过于大,理想情况下,系统的CPU利用率不应该超过70%。
Parallel GC Threads
通过 -XX:ParallelGCThreads = 20
当对GC Roots进行标记和移动时,需要进行STW,这个过程会使用ParallelGCThreads个GC线程进行并行执行。
ParallelGCThreads默认为CPU核数的60%,为什么可以这么大?
因为这个时候,应用线程已经完全停下来了,所以要用尽可能多的线程完成这部分任务,这样才能让STW尽可能的短暂。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

