『互联网架构』软件架构-mysql终级解决方案分库分表(65)
今天一起说说sharding-Sphere,跟数据库有关的,分库分表的初体验,了解为什么要分库分表,分库分表有哪些方案,分库分表如何做到永远都不需要做扩容的方案。今天一起分享这些知识点。思路就是鸡蛋不放在一个篮子里面。从 3.0 开始,Sharding-JDBC 将更名为 Sharding-Sphere。源码:sharding-sphere有介绍。

(一)为什么分库分表
之前说过为什么要进行分布式,大家用的硬件服务器都是有上限的。这好比我的电脑内存是16个G,我只能做16G的事情,如果系统超过16个G,这就是瓶颈,我就不能做。这就是一个单机它的瓶颈。原来很多项目都是单体的,随着瓶颈要扩的,之前说的应用的拆分,这次说说数据库层级的。
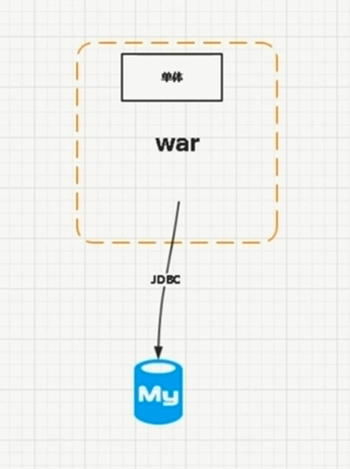
之前连接一个数据库的协议JDBC,JDBC连接mysql,这里只说mysql,单表的容量是在500万(单表条数),但是如果mysql的调优,数据可以达到1000万,以及我们的一个库和单个的应用,单个库好像是不能超过10个G的容量,总体还是跟容量有关系字段越多大小越大,有老铁说我们公司有DBA,可以做SQL的优化,可以多余500万,目前都1000多万了,但是你是不是查询很慢,当数据量特别庞大了,在进行调优效果也是微乎其微的,必须做分库或者分表,或者做读写分离。

读写分离,主要解决的就是高并发的问题,master和slave。master可能会增加,如果把select的查询给slave,master处理insert和update,delete等方案,master和slave进行同步,这是我们读写的一种方案。但是这不是终极解决方案,终极的解决方案就是分库分表。按照日期,规则来进行分库。
- 什么是分库分表
最主要的就是分片的概念,就是数据分片,sharding共享的概念。
- 为什么需要分库分表
随着业务越来越大,单机单个应用瓶颈的问题。数据库持久化硬盘如何去扩容。
- 数据库瓶颈解决方案:
- sql、表优化
- 读写分离
- 分库分表
(二)读写分离
数据库的操作:读取(查询)、修改、插入、删除CRUD。
- 数据库角色
master(主库、写库) slave(从库 读库)。
- 读写分离
insert update delete走主库,然后select走从库。
- 应用
读多写少 从库压力会很大 主库相对来说会低(双十一 写)
- 读写分离java开源框架分类
1.客户端(应用层)
2.中间件(代理层proxy)
读写分离:master一个压力的问题 随着我们业务增大之后 过渡期(试点项目,对于创业公司,今天做电商系统,明天可能就做区块链系统了),瓶颈(mysql本身的机制,机器的性能)产生原因,解决不了数据分片概念。
(三)客户端(应用层)
- TDDL
阿里TDDL分库分表没有开源,读写分离是开源。分析源码的时候不好说。
- Sharding-sphere
当当网的分库分表开源,读写分离是开源。目前作者去了京东金融。
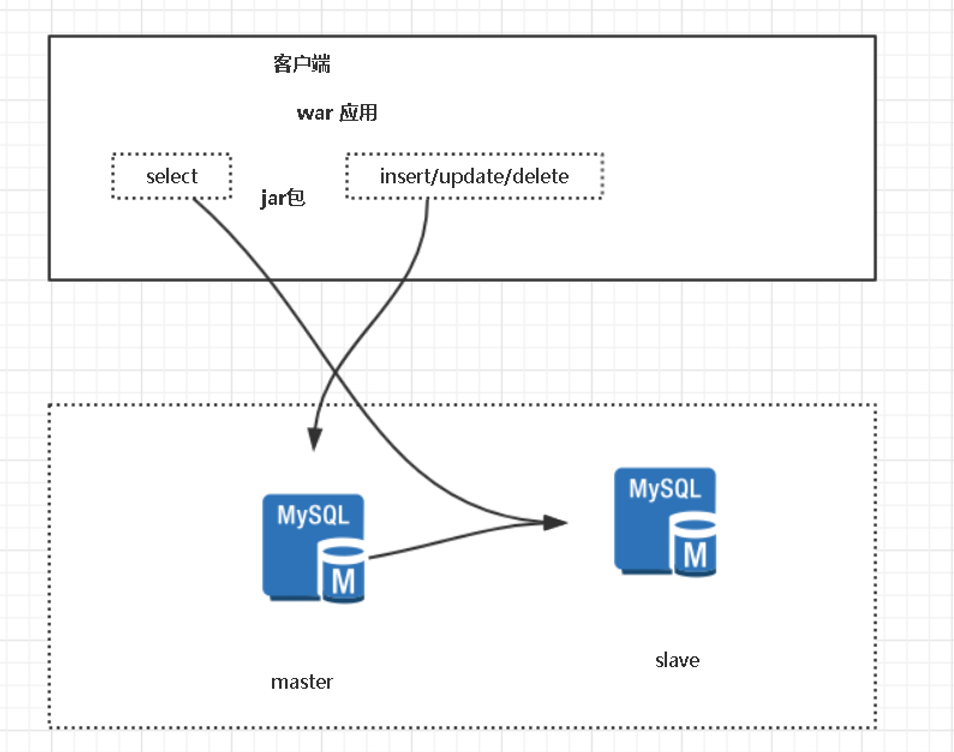
优点
1. 程序自动完成,数据源方便管理。
2. 不需要维护,因为没用中间件。
3. 理论支持任何数据库 (sql标准)。
缺点
1. 增加了开发成本、代码有入侵。
2. 不能做到动态增加数据源。
3. 程序员开发完成,运维参与不了。
(三)中间件(proxy)
- mysql proxy
官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差。
- mycat
用java语言开发,是中国开发者以自组织形式(暂且称之中国开源社区吧),基于阿里开源的Cobar打造演变而来,该项目在众多公司使用(超过300 个项目采用Mycat,涵盖银行、电信、电子商务、物流、移动应用、O2O 的众多 领域和公司 ),社区较活跃,有bug或踩坑能及时修复,性能高,功能强大较完善,而且还一同开源了运维管理平台。
- altas
用c/c++语言开发,同时有2大互联网公司360和美团支持的项目并开源,而且作为该公司重点投入和长期演进的方向,360 atlas 2015.04停止更新,美团fork 360 atlas,在此基础上打造持续迭代。
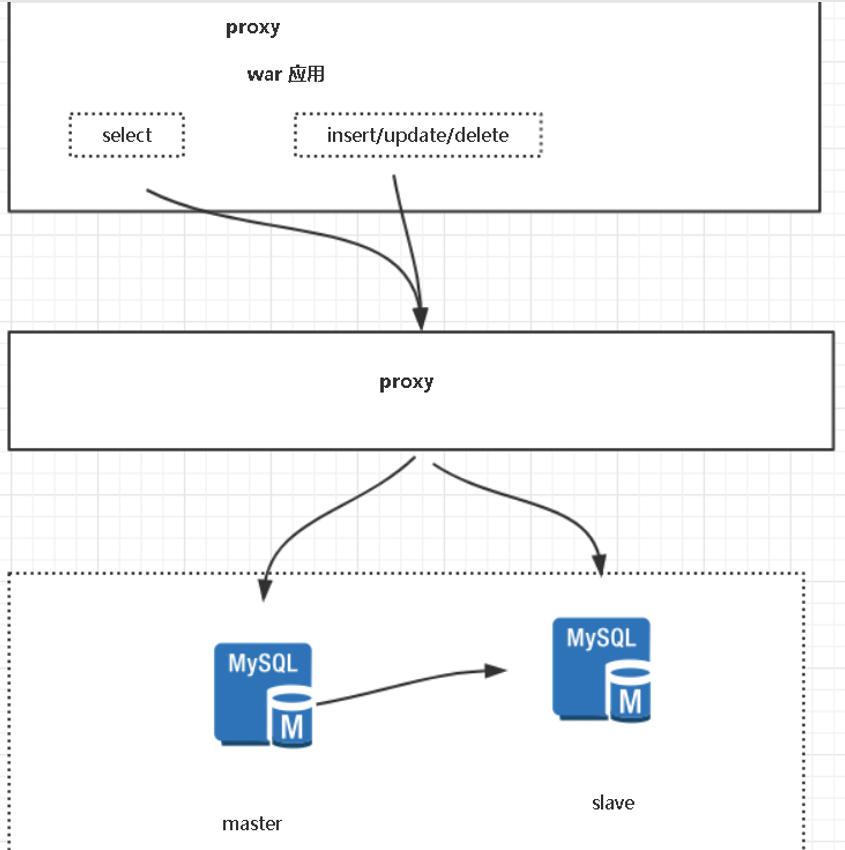
优点
1. 数据增加了,程序没任何影响。
2. 应用层(程序)不需要管数据库方面的事情 。
3. 增加数据源不需要重启程序。
缺点
1. 程序依赖中间件,导致切换数据库变的困难。
2. 增加了proxy 性能下降。
3. 增加了维护工作、高可用问题。
(四)分库分表
分库分表其实基于我们读写分离上面提出的方案(也就是目前关系型数据库的终极解决方案)解决高并发、数据分片。
-
垂直拆分
> 将一个字段(属性)比较多的表拆分成多个小表,将不同字段放到不同的表中降低单(表)库大小的目的来提高性能。
通俗:大表拆小表,拆分是基于关系型数据库的列(字段)来进行
特点
1. 每个库(表)的结构都不一样。
2. 每个库(表)数据都(至少有一列)一样。
3. 每个库(表)的并集是整个数据库的全量数据。
4. 每个库(表)的数据量(count)不会变的。
举例:一个用户表有很多的属性,关联了很多数据,如果放到同一个表里面的话查询是方便了,但是效率不行。
未拆分UserInfo表的字段
| userid | groupid | areaid | amount | point | modelid | message | islock | vip | overduedate | siteid | connectid | from | mobile |
拆分UserInfo表的字段
把常用的字段放一个表,不常用的放一个表,把字段比较大的比如text的字段拆出来放一个表里面,使用的话是根据具体业务来拆,查询时使用多表联查,可以再配合redis存储。
| userid | groupid | areaid | amount | point | modelid | message | 和 | islock | vip | overduedate | siteid | connectid | from | mobile |
解决问题
表与表之间的io竞争。
不解决问题
单表中数据量增长出现的压力。
-
水平拆分
某个字段按一定规律进行拆分,将一个表的数据分到多个表(库)中降低表的数据量,优化查询数据量的方式,来提高性能。
特点
- 每个库(表)的结构都一样。
- 每个库(表)的数据都不一样。
- 每个库(表)的并集是整个数据库的全量数据 。
拆分UserInfo表的字段
# 表0 userInfo_0 | userid | groupid | areaid | amount | point | modelid | message | islock | vip | overduedate | siteid | connectid | from | mobile | # 表1 userInfo_1 | userid | groupid | areaid | amount | point | modelid | message | islock | vip | overduedate | siteid | connectid | from | mobile | # 表2 userInfo_2 | userid | groupid | areaid | amount | point | modelid | message | islock | vip | overduedate | siteid | connectid | from | mobile |
分库分表常见算法
Hash取模:通过表的一列字段进行hash取出code值来区分的。(不好迁移)
Range范围: 按年份、按时间。(不好查找,如果找个数据没有时间,需要全部找)
List预定义:事先设定100找。(判断需要建立多少个分库)
解决问题
单表中数据量增长出现的压力。
不解决问题
表与表之间的io争夺。
分库分表之后带来的问题
- 查询数据结果集合并。
- sql的改变。
- 分布式事务。
- 全局唯一性id。
(四)Sharding-sphere
-
官网
> https://shardingsphere.apache.org/index_zh.html
-
介绍
> ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
PS:介绍了读写分离和分库分表的方案,引出了ShardingSphere,下次重点说说ShardingSphere。
>>原创文章,欢迎转载。转载请注明:转载自,谢谢!>>原文链接地址:上一篇:已是最新文章
正文到此结束
- 本文标签: O2O 开发者 时间 软件 DDL MQ sharding 云 ip 互联网 UI 代码 组织 src IO 本质 mysql db 金融 电子商务 list 查询很慢 message bug 源码 压力 NOSQL 管理 分布式事务 同步 2015 高可用 协议 数据库 sql 大数据 Select 文章 高并发 2019 服务器 银行 京东 IDE HTML 开源 删除 分布式 并发 apache 创业 cat redis 程序员 开发 http id Proxy update 产品 数据 创业公司 美团 颠覆 Master JDBC java https
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

