第五届中间件性能挑战赛-冠军队伍攻略分享

0. 公开代码
初赛
:
git clone https://code.aliyun.com/zhangboyang/adaptive-loadbalance.git
复赛
:
git clone https://code.aliyun.com/zhangboyang/mqrace2019.git
不过请注意,我之前没怎么写过 Java,这次比赛是边学边写,因此代码写得比较烂,请不要模仿我。
1. 初赛: 自适应负载均衡的设计实现
1.1 题目简介
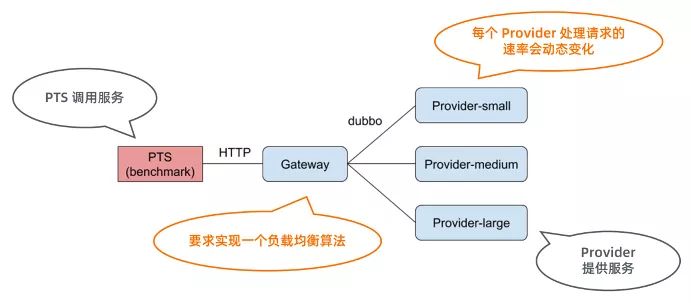
初赛题目要求实现一个负载均衡算法。
PTS 调用 Provider 提供的服务,而 Comsumer 担任负载均衡的角色。
为了模拟真实情况,Provider 同时并发数有限制(即同时进入服务的线程数有限制);
另一方面,进入服务内部的 Provider 处理时间符合指数分布。
其中,并发数和指数分布的参数(即平均处理时间)会随时间变化而变化。
评测成绩的指标为 60s 内请求成功的数量。
1.2 解题思路
在题目给定的条件下,若 Consumer 把请求按照每个 Provider 的允许并发数(下称容量),不多不少地分配给对应的 Provider,就可以拿到理论最高分数。
这是因为,从 Provider 角度看,如果一个 Provider 发生了过载,意味着吞吐量(TPS)不变而响应时间上升,响应时间上升则意味着总请求数下降(因为请求线程数有限,而且请求线程是等一个请求完成后才发送下一个请求的),成绩降低。
另一方面从 Consumer 角度看,如果有一个 Provider 过载,不如将过载的请求分配给空载的 Provider 高效,因为过载不能提高吞吐量,空载却会减少吞吐量。
所以,我们的思路就是通过精准测量并发数,并让 Consumer 将请求按并发数分配给 Provider。
通过理论结合实际实验数据,对过载的 Provider,可设计出以下模型:
响应时间表示为随机变量
Z
=
X
+
Y
,其中 X 符合指数分布(对应服务内响应时间), Y 符合正态分布(对应排队时间)。
查询资料后发现,这种分布叫
EMG 分布
。
不过这个对于分布,维基百科上只给出的矩估计的公式。
虽然矩估计理论上能直接计算出X指数分布的参数,进而推算出容量,然而实际用下来效果比较差,所以我们最终没有采用这种直接估计参数的方法。
直接估计参数的路走不通后,我们更换了思路。
主要思想是:
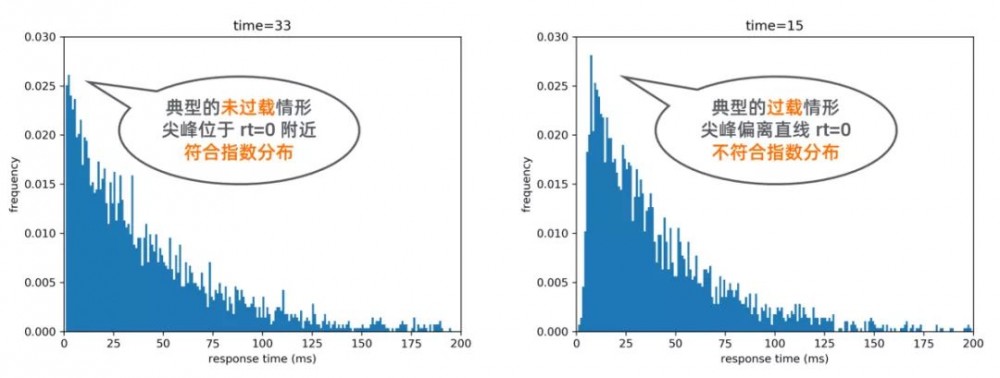
由于服务内响应时间为指数分布,如果发生过载,则会导致该分布不再符合指数分布。
具体实现是,记录从某一时刻后开始的请求,一定时间后,记录已完成的请求的数量和响应时间。
如果没有过载(如左图),则应符合截尾指数分布。
如果发生过载(如右图),则应不符合截尾指数分布。
不妨假设没有过载,根据统计数据,可以用最大似然估计,估计出模型的参数,再使用 KS 检验(KS 检验可以告诉我们观测到的数据是否符合某一理论分布)反过来确认假设是否成立。
如果假设成立,则说明没有过载,可以增加对该 Provider 的压力;
如果假设不成立,则说明发生过载,需要减少 Provider 的压力。
经过调参优化,最终成绩为 129.36 万。
赛后,我们思考了一些后续的优化策略。
通过打印 Consumer 的系统信息,我们发现 Consumer 负载过高,这可能是因为 Consumer 所在的 4C 4G 的机器性能不足。
我们的算法对 Consumer 造成的额外压力几乎没有,但实际测试数据表明,评测机 Load Average 约为 4.6 左右。
这大概也是许多人本地评测分数很高(比如我本地能到 130~131 万),但实际提交上去分数却变低的原因。
如果能优化 Dubbo 本身的代码,减少层层框架调用的开销,或是更换性更高的机器,成绩应该可以进一步提高。
另一方面,Java 语言的 GC 也是一个性能瓶颈,我使用 visualvm 对代码进行了 profile,由于 netty client 会不停地制造垃圾,所以每几秒钟 GC 大概就会运行一次,运行一次就是几十毫秒。
我尝试把 JVM 新生代的 MaxSize 调成 3G,大概成绩能高 1 万左右。
如果能优化网络通信部分的代码,使之不再制造很多垃圾,应该可以进一步提高成绩。
2. 复赛: 实现一个进程内基于队列的消息持久化存储引擎
2.1 题目简介
复赛题目要求实现一个进程内消息持久化存储引擎。
消息包括三个域
long t
、
long a
、
char[34] body
;
其中,t 的含义为时间戳数据,a 和 body 为业务数据。
该存储引擎需要实现三个操作:
存储消息
put()
、查询消息
getMessage()
、查询均值
getAvgValue()
。
评测流程也相应地分成三个阶段,每个阶段内部只进行单一的一种操作。
2.2 解题思路
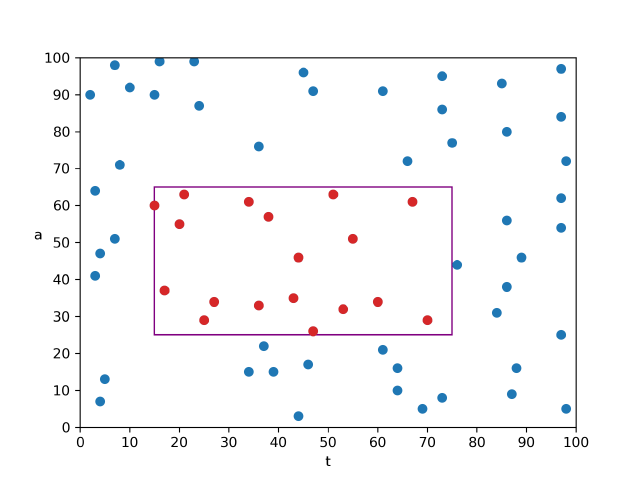
如果将每一条消息看做是平面上的数据点,
 分析要实现的三个操作可以发现:
查询消息一定会访问到所有被查到的消息,性能提升空间存在天花板;
而查询聚合结果则可以通过提前索引等操作避免访问所有被查消息,性能提升空间更大。
因此我们将优化重点放在第三阶段。
为此,我们选择尽量把数据处理操作移到第二阶段,利用第二阶段初始化的时间,整理数据并为第三阶段的查询建立索引。
分析要实现的三个操作可以发现:
查询消息一定会访问到所有被查到的消息,性能提升空间存在天花板;
而查询聚合结果则可以通过提前索引等操作避免访问所有被查消息,性能提升空间更大。
因此我们将优化重点放在第三阶段。
为此,我们选择尽量把数据处理操作移到第二阶段,利用第二阶段初始化的时间,整理数据并为第三阶段的查询建立索引。
key=(t,a) value=body
,那么查询范围可以用平面上的矩形来表示。
分析要实现的三个操作可以发现:
查询消息一定会访问到所有被查到的消息,性能提升空间存在天花板;
而查询聚合结果则可以通过提前索引等操作避免访问所有被查消息,性能提升空间更大。
因此我们将优化重点放在第三阶段。
为此,我们选择尽量把数据处理操作移到第二阶段,利用第二阶段初始化的时间,整理数据并为第三阶段的查询建立索引。
对于第一阶段的
put()
操作,我们分析了性能的瓶颈主要在于磁盘的连续 I/O 速度,然而 CPU 资源也十分紧张。
为了提高写入的性能,我们一方面需要尽量减少磁盘 I/O 的字节数,另一方面需要减少 CPU 的开销。
我们设计了一个通用的数值压缩器(
util.ValueCompressor
类),它模仿了 UTF-8 对数值进行变长编码的方式,可以将
long
范围内的整数压缩为 1~9 字节。
数值的前导 0 越多,压缩的效率就越高。
对于每一个发送线程,我们存储
threadXXXX.zp.data
和
threadXXXX.body.data
两个文件(其中
XXXX
为线程 ID 号)。
threadXXXX.zp.data
文件存储的是经过数值压缩器压缩的
(deltaT, a)
数对,由于我们只存储每一条数据中 t 相对上一条数据的 t 的差值,因此在绝大多数情况下,每条记录中 t 的存储只需 1 字节,而 a 根据数据范围的不同会占用不同的字节数,对于 48bit 左右的 a 值,需要 7 个字节进行存储。
threadXXXX.body.data
文件中存储的是完整的未经过处理的 body 数据,每条数据需 34 字节。
按这样计算,所有线程写入磁盘量大约为 84GB,我们在一阶段的得分约为 6800 分。
我们将主要的排序及索引构建工作放到第二阶段进行。
首先要进行的就是排序工作。
由于题目里明确说明,各线程内的t为升序,我们采用了经典的外部排序算法——合并排序。
我们的合并排序算法会为每一个发送线程的数据开辟一块缓冲区作为输入队列。
每次循环,会从所有队列的头部,取出一个最小 t 的消息进行输出。
为了提高性能,我们将排序操作和构建索引操作同时进行(流水化处理),即合并排序产生一条消息输出,就会调用索引构建函数,插入此条消息。
二阶段本身的查询操作比较简单,只需根据t范围到每一个线程的数据文件中进行暴力查找即可,我们就不详细说明了。
第三阶段的聚合查询是我们重点优化的对象。
为此,我们编写了多种查询算法,每种算法所擅长的查询范围有所不同。
我们模仿数据库系统,实现了查询计划器(Query Planner),每次查询它会先对每种算法进行 I/O 代价预估,再选择最小代价的那个算法去执行实际的查询。
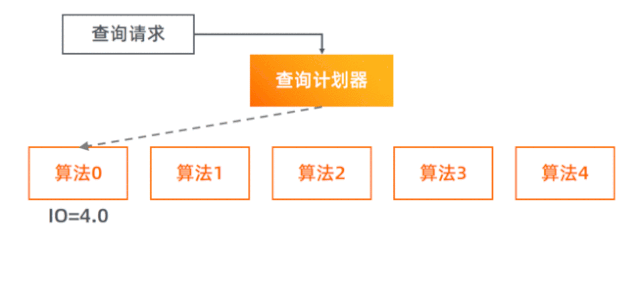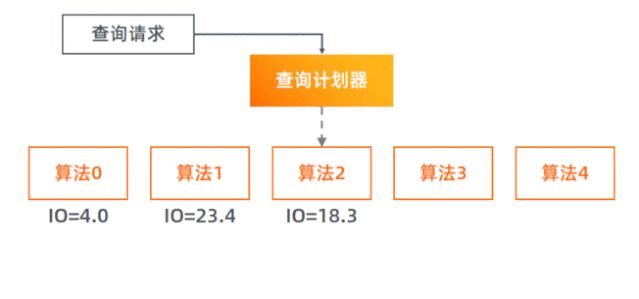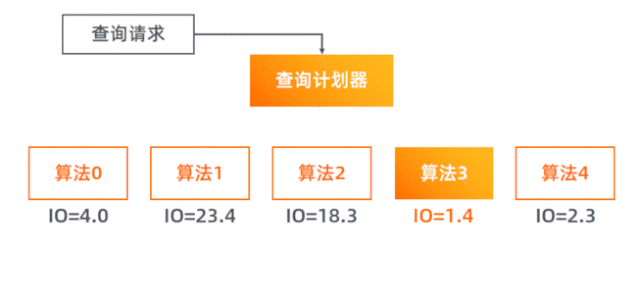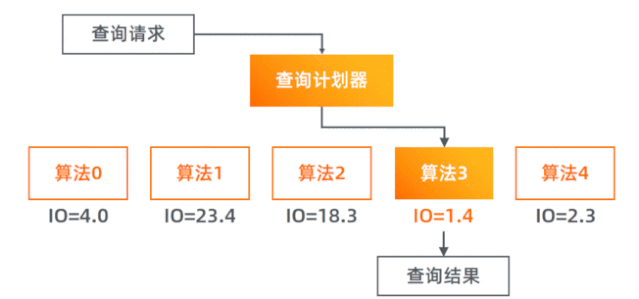
我们一共实现了 5 个查询算法。
我们每个算法都采用了分块思想。
具体而言,我们的算法将 t 轴分为 2500000 块,再将每一个 t 分片中的数据,按 a 轴分为 40 个小块(实际上 a 轴分块数会根据算法不同而有所不同)。
也就是说,将平面分为了2500000x40个小块。
不同的算法需要按不同顺序存储数据点,因此我们需要构建数个不同的索引文件。
接下来我们会逐一介绍每种算法的思路和对应索引的构建方式。
-
算法 0
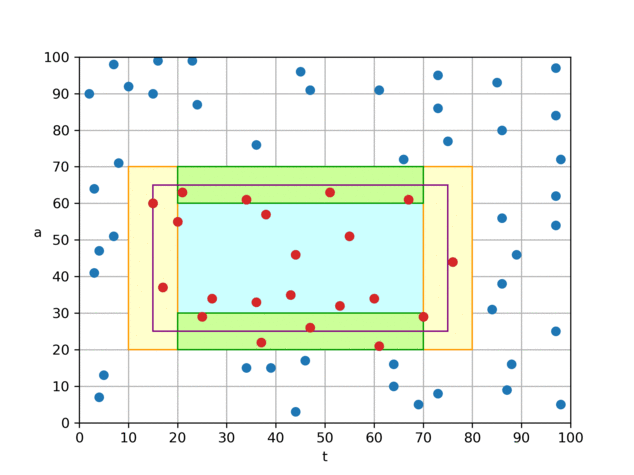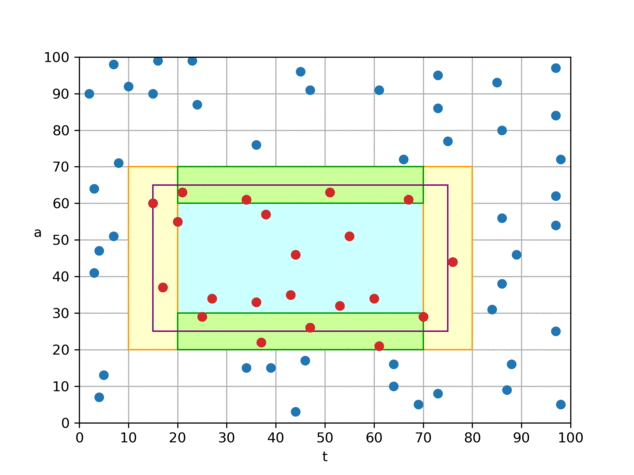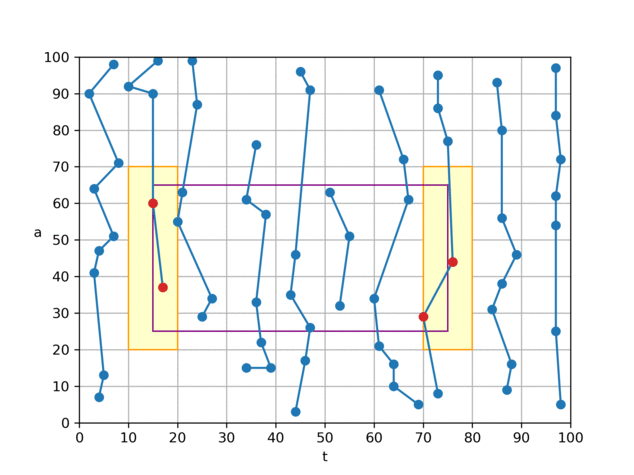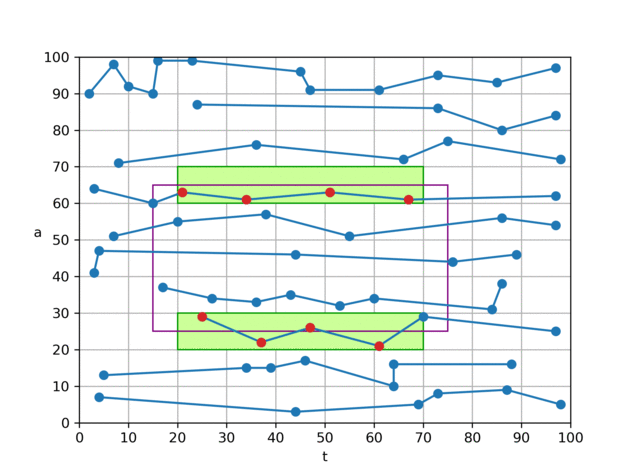
算法 0 是我们认为理论上较为优秀的一个算法。它只会从磁盘中读取与查询矩形四条边相交的块中的数据,对于完全被查询矩形所覆盖到的小块,则由内存中的前缀和可直接计算出“和”、“个数”,无须访问 磁盘, 因此查询的复杂度由 O (查询矩形的面积)降低到 O (查询矩形的边长),相当于从 O(n²) 下降到 O(n) 。
-
具体做法是,对于如图所示的查询矩形,我们将左、右两个 t 分片(黄色)中的
(t,a)数据从磁盘取出并暴力判断,若在查询区域内,则加到结果中; 对于上、下两个夹在 t 分片中间的 a 分片(绿色),根据分片方式,我们可以知晓其 t 一定在查询范围内,因此只需取出 a 数据,并进行判断即可。 为了达到最优 I/O 效率,我们建立了两个文件,一个文件按照 t 方向存储点数据(t,a),另一个文件按照 a 方向,只存储 a 数据,如图中的折线所示。通过这样组织文件,我们可以将 t、a 分片用各自文件的两次连续 I/O 来读取。 这样就可以在 4 次 I/O 代价内,完成平均值的查询。 代码中的实际实现与上文所述略有不同,为了节省空间,我们并未在内存中保留前缀和,而是直接在 a 方向索引文件中保存 a 值在对应 t 分片内的前缀和(文件中只保存前缀和,a 本身的值可通过前缀和来推算),矩形中间的“和”、“数量”便可通过 a 的前缀和、偏移信息推算出来。 另一方面,在内存中我们只保留了一张经过前缀和处理过的“小块内记录数表”(
blockRecordCountPrefixSum数组)。 通过这张表,我们可以在O ( 1 ) 时间内计算每个小块的记录数、每个小块在两个文件中的偏移。 因此,我们的索引实际上只需要在内存中存储一个大小为int[2500000][40]的数组(约占 0.4GB 内存),十分节省内存。虽然算法 0 的效率已经十分优秀,可以在 4 次 I/O 内完成查询,但它的缺点是,不论查询范围是大是小,都需要读取 4 次磁盘。 对于 t 查询范围较小,或 a 查询范围较小的查询,实际上可以用更少的 I/O 次数完成查询。 因此我们针对这类情况设计了其它几个算法。
-
算法 1、算法 2
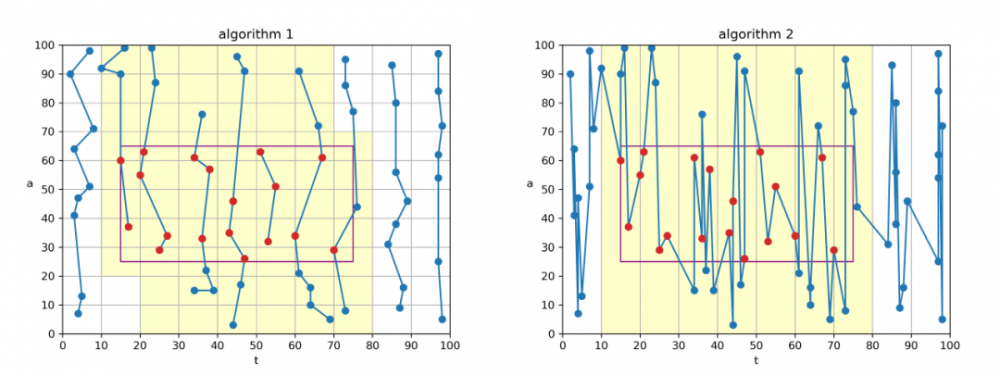
算法 1、算法 2 这两个算法是针对“t 范围小”的查询而设计的。 算法 1 直接采用算法 0 的“t 方向索引”,如果 t 查询范围较少,则可以在 1 次 I/O 之内读取完图中阴影部分的
(t,a)数据(每条为 16 字节),然后进行暴力判断。 算法 2 使用一个单独的索引文件,其内按照 t 方向存储用数值压缩器变长编码的(deltaT,a)数据(每条约 8 字节),然后进行暴力判断。 由于采用了变长编码和 t 差值,为了节省内存,只将分片进行到 t 轴这一层次,不再对 t 轴分片继续划分小块。 因此从数据条数上讲,算法 2 会比算法 1 读入稍多的数据。 不过由于采用了变长编码,从字节数角度讲,算法 2 常常优于算法 1。我们还有一个重要的优化是为算法 2 添加内存缓存。 算法 2 使用到的文件大约为 16GB,我们将其中约 4GB 数据固定于内存中,若读取时命中了内存中的缓存,则直接从内存中取数据,并将 I/O 开销记为 0。 这样可以极大地提高性能。
-
算法 3、算法 4
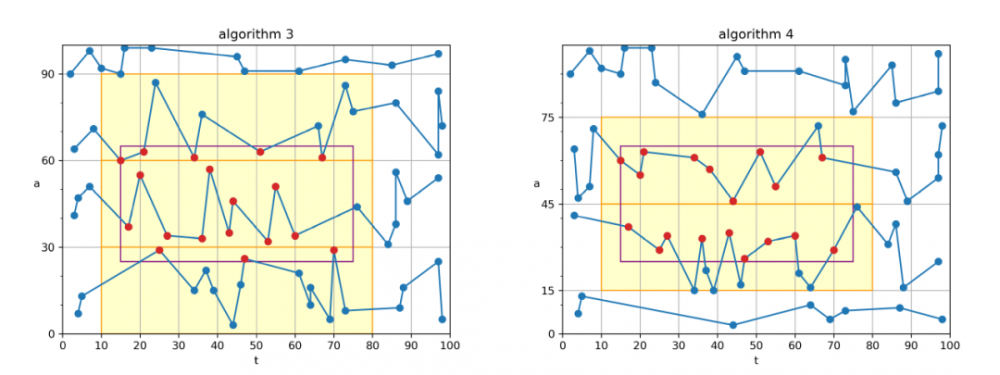
这两个算法是针对“a 范围小”的查询而设计的。 这两个算法代码完全相同,只是 a 轴的划分略有不同。 算法 3 整体采用类似“算法 2”的思路,使用数值压缩器存储
(deltaT,a)数据。 不同的是,存储方向改为 a 轴方向(如左图中的折线所示),而且只对 a 轴分 8 个分片。 通过这样的配置,当 a 查询范围较小时,会落到一个或少数几个分片中,因此可以在一次或少数几个 I/O 内完成查询。 算法 4 与算法 3 采用不同的 a 分片阈值,这样做可以优化“查询矩形恰好跨越边界”这种情况,提高整体的性能。
2.3 一些实现上的细节
-
查询计划器的实现
查询计划器(Query Planner)负责预估各个算法方案的磁盘 I/O 代价并选择最小的那个去执行。 具体的实现是,对于每个算法实现函数,新添加一个参数
boolean doRealQuery,若设置为false,则只查内存中的元数据,计算要读取的字节数,而不进行真正的文件读取及后续处理; 若设为true则进行完整的处理。 查询计划器会先使用doRealQuery=false去调用每一个算法,然后选择 I/O 代价最小的那个,用doRealQuery=true参数去真正执行它。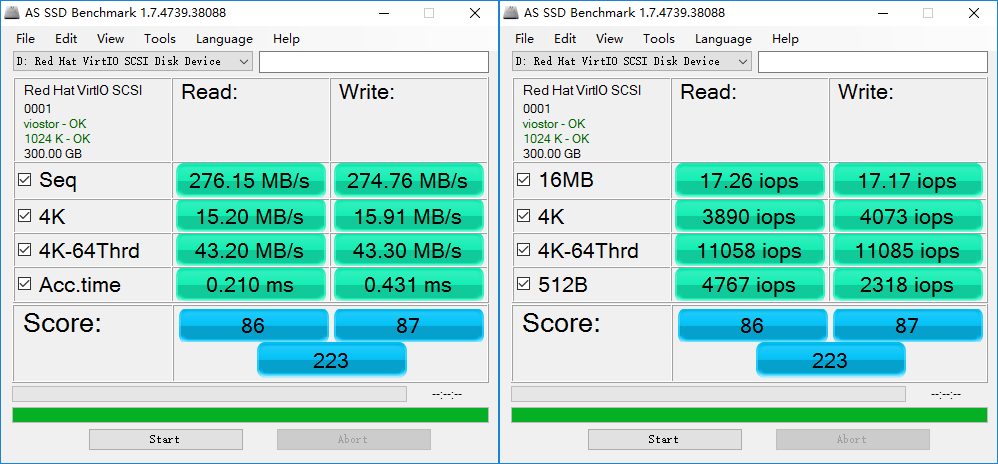
评测机上的 SSD 性能如上图所示。 I/O 代价表现为两个方面: I/O 字节数、I/O 次数。 我们需要一个公式来统一 I/O 代价的计算。 我们选择以 I/O 次数为基准,统一将 I/O 字节数折算为 I/O 次数,具体计算公式如下。 因此一次 I/O 代价最小为 1,最大上不封顶。
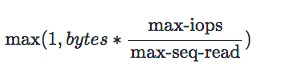
-
一个针对 Java 二维数组的优化
Java 自带的二维数组实际上是“数组套数组”,这样会带来两个问题: (1)如果最右维较小,则对象本身开销占比会很大,浪费内存; (2)如果最左维较大,则会产生很多低维数组对象,给 GC 造成很大压力。 我们自己设计了两个类 Compact2DIntArray 和 Compact2DLongArray。 它们通过使用一维数组来模拟二维数组,既节省内存,也减少 GC 时间。
2.4 代码说明
赛后,我们对最高分版本的代码结构进行了重构,添加了大量注释,大幅提升了代码可读性。
在重构过程中,我们没有对代码进行功能性修改,只是改变了代码的结构。
重构后的每个类的功能如下表所示:
| 类名 | 功能 |
|
IndexWriter
|
排序、生成索引的代码
|
|
IndexMetadata
|
索引的元数据(如前缀和、文件偏移表等)
|
|
SliceManager
|
分片的元数据(如分片阈值等)
|
|
FileStorageManager
|
文件对象
|
|
CachedCompressedPointAxisT
|
算法 2 的文件缓存
|
|
PutMessageProcessor
|
用于 put() 操作的代码
|
|
GetMessageProcessor
|
用于 getMessage() 操作的代码
|
|
AvgQueryProcessor
|
用于 getAvgValue() 操作的代码
|
util
包内是一些工具代码,详细功能如下表所示:
| 类名 | 功能 |
|
Compact2DIntArray
|
用一维数组模拟二维数组(int)
|
|
Compact2DLongArray
|
用一维数组模拟二维数组(long)
|
|
ValueCompressor
|
数值压缩器,用类似 UTF-8 的方式进行变长编码
|
|
Util
|
其它工具代码(如二分查找等)
|

点击下方图片即可阅读

Apache Flink 零基础入门系列 (六)

天池大赛

AI公开课第二期
如果你在学习过程中,有看到一些比较 优质的文章或Paper,或者你平时自己学习笔记和原创文章,请投稿到天池 ,让更多的人看到。除了精美的 丰富的神秘天池大礼以及粮票奖励 ,更有现金大礼在等着你。
分享成功后你也可以通过下方钉钉群:point_down:主动联系我们的社区运营同学(钉钉号: modestt )

天池宝贝们有任何问题,可在戳“留言”评论或加入钉钉群留言,小天会认真倾听每一个你的建议!


在看点这里

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

