大文本文件的字符匹配处理办法
在进行文本处理时,经常会遇到对大文件进行字符串匹配情况。用命令行的 grep/cat 命令处理此类问题时,写法很简单,但效率太低,用高级语言处理此类问题虽然可以获得较高的运行效率,但代码编写复杂度却相当高。
集算器支持大文件字符串匹配和多线程并行计算,代码简洁性能优异,下面通过例子来看一下具体作法。
文件 file1.txt 存储着大量的字符串,现在需要找出以 ”.txt” 结尾的行数据,并输出到 result.txt 中。部分源数据如下:

集算器代码:
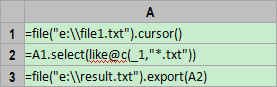 A1 :以游标的形式打开文件。函数 cursor 并不会将数据全部读入内存,而是以游标(流)的方式打开文件,因此不会占据内存空间。函数 cursor 使用了默认参数,即:以 tab 为列分割符读入全部的字段,自动命名为 _1 、 _2 、 _3…_n 。对于本案例来说,只有一个字段 _1 。
A1 :以游标的形式打开文件。函数 cursor 并不会将数据全部读入内存,而是以游标(流)的方式打开文件,因此不会占据内存空间。函数 cursor 使用了默认参数,即:以 tab 为列分割符读入全部的字段,自动命名为 _1 、 _2 、 _3…_n 。对于本案例来说,只有一个字段 _1 。
A2=A1.select(like@c(_1,"*.txt"))
这句代码用来查询出游标 A1 里以“ .txt ”结尾的行数据。函数 select 执行查询,函数 like 进行字符串匹配,其中 _1 表示第一个字段。函数 like 还使用了选项 @c ,这表示匹配时不区分大小写。
值得注意的是, A2 的运算结果是游标,仍然不会占据内存空间。只有遇到 export/fetch/groups 等函数时,集算器引擎才会分配合适的内存缓冲区,并将前面的游标计算自动转化为内存计算。。
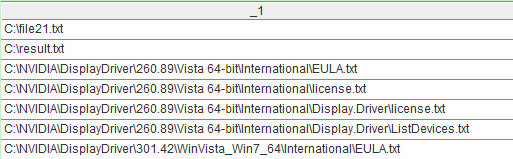
A3=file("e://result.txt").export(A2) ,这句代码将最终计算结果写入文件。部分数据如下:
上面的匹配规则比较简单,如果遇到复杂的情况,那就需要使用正则表达式。比如:找出以“c:/windows”开头,且结尾名不是“.txt”的行数据。
函数 regex 可以进行正则表达式匹配,只需将 A2 改为:
A1.regex@c("^c:////windows.*(?<!////(.txt)$)")
上面代码中,选项 @c 表示不区分大小写。
正则表达式虽然可以实现更复杂的匹配规则,但性能偏低,比如从 2.13G 的文件中找出以“ .txt ”结尾的行数据,在同样环境下测试,用正则表达式需要 206 秒,用普通表达式( select )只需要 119 秒。
事实上,普通表达式也可以实现很多逻辑较复杂的匹配规则,而且语法更加直观,学习成本更低。比如 emp.txt 存储着大量的用户信息,每条用户信息分为多个字段,字段之间用 tab 分割,第一行是字段名。现在要找出符合下列条件的数据: EId 字段在 100 以内, Name 字段的首字母是 a , Birthday 字段大于 1984-01-01 。集算器代码如下:

函数 cursor 的选项 @t 表示将第一行读为列名,之后就可以使用列名来访问数据。
查询条件是三个,可以分别用 EId>100 、 like@c(Name,"a*") 、 Birthday>=date("1984-01-01") 来表示,条件之间是“与”的逻辑关系,可以用 && 来表示。
前面的算法是串行,改成并行可以进一步提高性能,具体做法是用多个线程并行读取文件,每个线程都用游标访问文件的一部分,并同时进行集合计算,最后再将每个游标的结果合并。
在相同的硬件环境下对 2.13G 的大文进行测试,串行时平均耗时 119 秒,并行时平均耗时 56 秒,性能提高一倍左右。例子中的算法复杂度较低,瓶颈会产生在硬盘读取上,如果进一步加大运算的复杂度,性能提升的幅度将会更大。
集算器并行计算的代码如下:
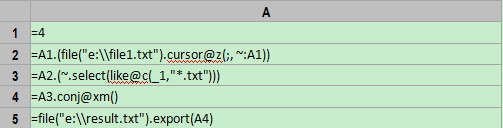
A1=4 , A1 是分段数量,即将文件分成 4 段。分段数量,也就是实际执行时的并行数,一般不要超过 CPU 的核数,否则会形成排队等待,并不能提高性能。实际使用最大并行数量可以在选项中配置。
A2=A1.(file("e://file1.txt").cursor@z(;, ~:A1))
上面的代码按照分段数量生成 4 个游标。其中 A1.(express) 表示按照括号内的表达式依次计算 A1 的成员,括号内可用“ ~ ”来表示当前成员。 A1 一般是集合,比如 [ "file1", " file2" ] 或 [2,3] , A1 如果是从 1 开始的连续数字,比如 [1,2,3,4] ,则可以简写成 4.( express) ,案例中的代码就是这种情况。
括号内的表达式是 file("e://file1.txt").cursor@z(;, ~:A1) ,其中函数 cursor 使用了选项 @z ,这表示将文件分段,用游标取其中的某一段。 ~:A1 表示文件会被大致分为 4 段 (A1=4) ,当前取第 ~ 段。“ ~ ”是 A1 的当前成员,因此每个游标依次对应第 1 、第 2 、第 3 、第 4 段文件。
另外,之所以是“大致分”,是因为精确分会出现半行数据的情况,而集算器会去头补位,自动取出整行数据。
A3=A2.(~.select(like@c(_1,"*.txt"))) , 这句代码针对 A2 中的每个游标(即 ~ )进行计算,求出游标中符合条件的行数据。这里的计算结果仍然是四个游标。
A4=A3.conj@xm() , 这句代码将 A3 中的多个游标进行并行合并。
A5=file("e://result.txt”).export(A4) ,将最终计算结果输出到文件中。
集算器脚本不仅能在 IDE 中独立运行,也可以通过 JDBC 接口被 JAVA 程序调用,用法和普通数据库没有区别。单步的计算脚本还可以直接嵌入 JAVA 代码中,而无需脚本文件。比如前面的 A1-A5 是分步计算,其实可以合为一步: file("e://result.txt").export(4.(file("e://file1.txt").cursor@z(;, ~:4)).(~.select(like@c(_1, "*.txt"))).conj@xm())
在操作系统命令行也可以直接运行这种单步脚本,具体内容请参考相关文档。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

