一步一步教你用Vue.js + Vuex制作专门收藏微信公众号的app
只看不赞,或者只收藏不赞的都是耍流氓,放学别走,我找我哥收拾你们。
项目地址: https://github.com/jrainlau/wechat-subscriptor
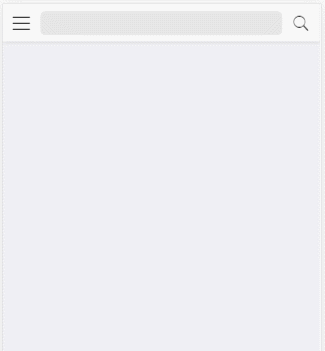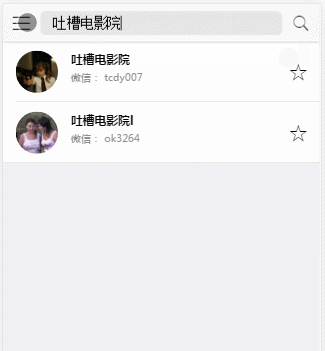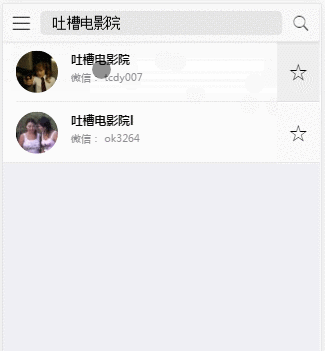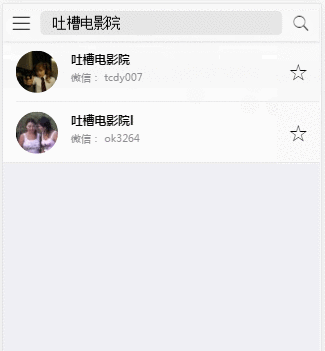

下载&运行
git clone git@github.com:jrainlau/wechat-subscriptor.git cd wechat-subscriptor && npm install npm run dev // run in dev mode cd backend-server && node crawler.js // turn on the crawler server open `localhost:8080` in your broswer and enjoy it.项目介绍
我在微信上关注了不少的公众号,经常浏览里面的内容。但是往往在我阅读文章的时候,总是被各种微信消息打断,不得不切出去,回复消息,然后一路点回公众号,重新打开文章,周而复始,不胜其烦。后来想起,微信跟搜狗有合作,可以通过搜狗直接搜索公众号,那么为什么不利用这个资源做一个专门收藏公众号的应用呢?这个应用可以方便地搜索公众号,然后把它收藏起来,想看的时候直接打开就能看。好吧,其实也不难,那就开始从架构开始构思。
整体架构
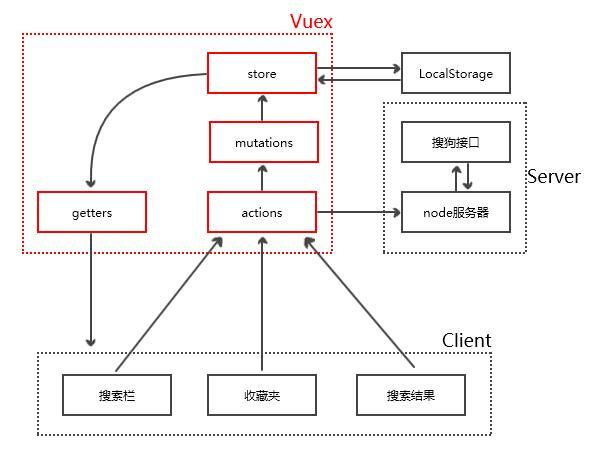
国际惯例,先看架构图:
然后是技术选型:
-
利用搜狗的API作为查询公众号的接口。
-
由于存在跨域问题,遂通过
node爬虫使用接口。 -
使用
vue进行开发,vuex作状态管理。 -
使用
mui作为UI框架,方便日后打包成手机app。 -
使用
vue-cli初始化项目并通过webpack进行构建。
首先分析红圈中的 vuex 部分。它是整个APP的核心,也是所有数据的处理中心。
客户端所有组件都是在 action 中完成对流入数据的处理(如异步请求等),然后通过 action 触发 mutation 修改 state ,后由 state 经过 getter 分发给各组件,满足“单项数据流”的特点,同时也符合官方推荐的做法:
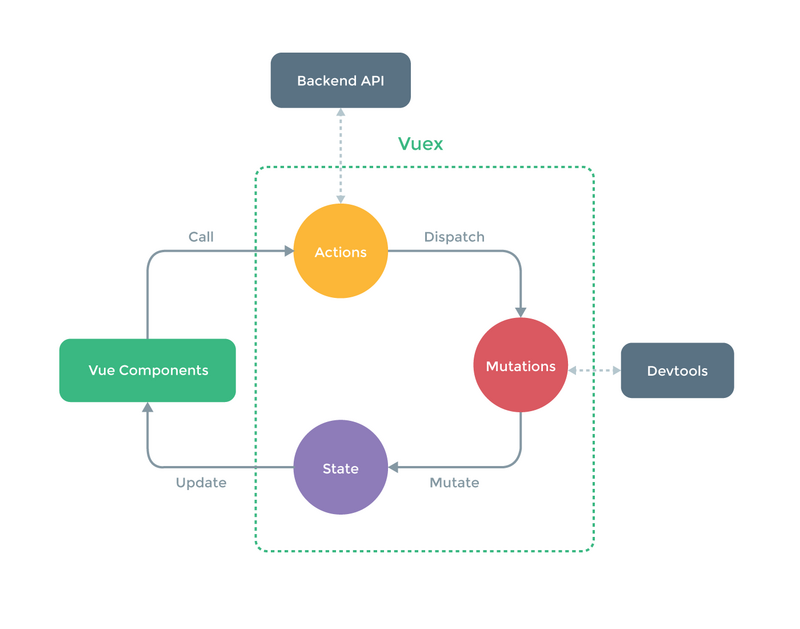
理解完最重要的 vuex 以后,其他部分也就顺利成章了。箭头表示数据的流动, LocalStorage 负责储存收藏夹的内容,方便下一次打开应用的时候内容不会丢失,node服务器负责根据关键字爬取搜狗API提供的数据。
是不是很简单?下面让我们一起来开始coding吧!
初始化项目
npm install vue-cli -g 安装最新版的 vue-cli ,然后 vue init webpack wechat-subscriptor ,按提示经过一步步设置并安装完依赖包以后,进入项目的目录并稍作改动,最终目录结构如下:
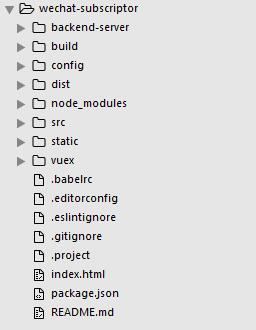
具体的内容请直接浏览 项目
服务器&爬虫
进入 /backend-server 文件夹并新建名为 crawler-server.js 的文件,代码如下:
/*** crawler-server.js ***/ 'use strict' const http = require('http') const url = require('url') const util = require('util') const superagent = require('superagent') const cheerio = require('cheerio') const onRequest = (req, res) => { // CORS options res.writeHead(200, {'Content-Type': 'text/plain', 'Access-Control-Allow-Origin': '*'}) let keyWord = encodeURI(url.parse(req.url, true).query.query) // recieve keyword from the client side and use it to make requests if (keyWord) { let resultArr = [] superagent.get('http://weixin.sogou.com/weixin?type=1&query=' + keyWord + '&ie=utf8&_sug_=n&_sug_type_=').end((err, response) => { if (err) console.log(err) let $ = cheerio.load(response.text) $('.mt7 .wx-rb').each((index, item) => { // define an object and update it // then push to the result array let resultObj = { title: '', wxNum: '', link: '', pic: '', } resultObj.title = $(item).find('h3').text() resultObj.wxNum = $(item).find('label').text() resultObj.link = $(item).attr('href') resultObj.pic = $(item).find('img').attr('src') resultArr.push(resultObj) }) res.write(JSON.stringify(resultArr)) res.end() }) } } http.createServer(onRequest).listen(process.env.PORT || 8090) console.log('Server Start!') 一个简单的爬虫,通过客户端提供的关键词向搜狗发送请求,后利用 cheerio 分析获取关键的信息。这里贴上搜狗公众号搜索的地址,你可以亲自试一试: http://weixin.sogou.com/
当开启服务器以后,只要带上参数请求 localhost:8090 即可获取内容。
使用 Vuex 作状态管理
先贴上 vuex 官方文档: http://vuex.vuejs.org/en/index.html
相信我,不要看中文版的,不然你会踩坑,英文版足够了。
从前文的架构图可以知道,所有的数据流通都是通过 vuex 进行,通过上面的文档了解了有关 vuex 的用法以后,我们进入 /vuex 文件夹来构建核心的 store.js 代码:
/*** store.js ***/ import Vue from 'vue' import Vuex from 'vuex' Vue.use(Vuex) const state = { collectItems: [], searchResult: {} } localStorage.getItem("collectItems")? state.collectItems = localStorage.getItem("collectItems").split(','): false const mutations = { SET_RESULT (state, result) { state.searchResult = result }, COLLECT_IT (state, name) { state.collectItems.push(name) localStorage.setItem("collectItems", state.collectItems) }, DELETE_COLLECTION (state, name) { state.collectItems.splice(state.collectItems.indexOf(name), 1) localStorage.setItem("collectItems", state.collectItems) } } export default new Vuex.Store({ state, mutations })下面我们将对当中的代码重点分析。
首先我们定义了一个 state 对象,里面的两个属性对应着收藏夹内容,搜索结果。换句话说,整个APP的数据就是存放在 state 对象里,随取随用。
接着,我们再定义一个 mutations 对象。我们可以把 mutations 理解为“用于改变 state 状态的一系列方法”。在 vuex 的概念里, state 仅能通过 mutation 修改,这样的好处是能够更直观清晰地集中管理应用的状态,而不是把数据扔得到处都是。
通过代码不难看出,三个 mutation 的作用分别是:
-
SET_RESULT:把搜索结果存入state -
COLLECT_IT:添加到收藏夹操作(包括localstorage) -
DELETE_IT:从收藏夹移除操作(包括localstorage)
组件数据处理
我们的APP一共有两个组件, SearchBar.vue 和 SearchResult.vue ,分别对应着搜索部分组件和结果部分组件。其中搜索部分组件包含着收藏夹部分,所以也可以理解为有三个部分。
-
搜索部分组件
SearchBar.vue
/*** SearchBar.vue ***/ vuex: { getters: { collectItem(state) { return state.collectItems } }, actions: { deleteCollection: ({ dispatch }, name) => { dispatch('DELETE_COLLECTION', name) }, searchFun: ({ dispatch }, keyword) => { $.get('http://localhost:8090', { query: keyword }, (data) => { dispatch('SET_RESULT', JSON.parse(data)) }) } } } 代码有点长,这里仅重点介绍 vuex 部分,完整代码可以参考 项目 。
getters 获取 store 当中的数据作予组件使用。
actions 的两个方法负责把数据分发到 store 中供 mutation 使用。
看官方的例子,在组件中向 action 传参似乎很复杂,其实完全可以通过 methods 来处理参数,在触发 actions 的同时把参数传进去。
-
结果部分组件
SearchResult.vue
/*** SearchResult.vue ***/ vuex: { getters: { wordValue(state) { return state.keyword }, collectItems(state) { return state.collectItems }, searchResult(state) { return state.searchResult } }, actions: { collectIt: ({ dispatch }, name, collectArr) => { for(let item of collectArr) { if(item == name) return false } dispatch('COLLECT_IT', name) } } } 结果部分主要在于展示,需要触发 action 的地方仅仅是添加到收藏夹这一操作。需要注意的地方是应当避免重复添加,所以使用了 for...of 循环,当数组中已有当前元素的时候就不再添加了。
尾声
关键的逻辑部分代码分析完毕,这个APP也就这么一回事儿,UI部分就不细说了,看看项目源码或者你自己DIY就可以。至于打包成APP,首先你要下载HBuilder,然后通过它直接打包就可以了,配套使用 mui 能够体验更好的效果,不知道为什么那么多人黑它。
搜狗提供的API很强大,但是提醒一下,千万不要操作太过频繁,不然你的IP会被它封掉,我的已经被封了……
Weex 已经出来了,通过它可以构建Native应用,想想也是激动啊,待心血来潮就把本文的项目做成 Weex 版本的玩玩……
最后的最后,感谢你的阅读,如果觉得我的文章不错,欢迎关注我的专栏,下次见!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

