使用API登录知乎并获得token
之前在公众号转载了一篇 使用Python模拟登录知乎 , 使用了目前实现爬虫比较常用的Web登录方式。我以前写爬虫选择的方式是:
- 如果对方网站有开放平台,满足需求且比较容易获取API权限,优先使用API。
- 如果网页登录及验证非常容易,甚至都不用登录就可以获取爬取网页,也是可以的。但是Web抓取不是最优先的,因为Web页面结构会改变、登录验证方式也会不断更新,可以感受到层出不断的验证码方式,烦。Web抓取,如果对应的移动适配的页面满足我会优先考虑移动端抓取,限制要少一些。我在知乎回答「 你见过哪些令你瞠目结舌的爬虫技巧? 」最后提到过:「第二条: 不要只看 Web 网站, 还有移动版、 App 和 H5, 它们的反爬虫措施一般比较少, 所有社交网站爬虫, 优先选择爬移动版。 」,不过这条大家好像都是直接忽略的… 忧伤
- 当前2种都不好使的时候,虽然没有公开的API,但是只要这个应用有移动版本,就好办….
昨天喜闻知乎获得了新一轮的融资,晚上赶紧研究了下通过抓包获取知乎API的方法,分享给大家。由于之前我写的爬虫被对方寄了律师函(像豆瓣、知乎这种胸襟的公司毕竟是少数),读者请不要分享到掘金等平台(知乎可以),小范围传播就好了,感谢!
昨晚灵机一动的原因是由于之前在写「我的2016年」的时候,fork了 zhihu-oauth ,添加了following接口,跑了个获取参与我的Live的人中有多少关注者的脚本。
其实本文并没有超出zhihu-oauth的技术实现。但是我并不想把我的修改提PR合并给上游,因为对一些代码和实现的理解有一些冲突。
但是能有本文还是非常感谢zhihu-oauth,它其实就是用知乎API实现的抓取,我本文的提到的技术和代码并没有超过它的范畴。但是还是有一些区别:
- 代码量。zhihu-oauth是一个中型组织结构,目录模块分配合理,我这个是它的抓取核心的简化版本,代码量少了很多。「Python之禅」里面有一句「Simple is better than complex.」,我个人不喜欢看结构复杂,尤其有黑科技的项目。当然会这样一般有炫技、作者对写项目的理解、设计能力还是历史遗留等原因。我比较喜欢简单粗暴的展示核心,代码能力在我看来有一个方面是能把复杂的事情非常简单化的表达,以至于让初学Python不久的工程师看起来也会愉悦,我正在朝着这个方向努力。
- 移动设备。zhihu-oauth使用的安卓,我这篇文章用到的是IOS,且是目前最新版。
- 展开细节。zhihu-oauth是一个开箱即用的项目,你可以不必读源码甚至不会写爬虫即可。而我今天是给大家讲整个抓取过程都发生了什么,怎么完成抓取的。相信大家看完之后去抓其他应用的包也会容易很多。
- 其他实现细节。比如zhihu-oauth使用了pickle来序列化token的结果,它是Python独有的,可读性和安全性都不好,我改用了json。
好吧,我们开始。
IOS抓包
安卓的权限控制比较松,能比较方便的抓包。但是IOS由于苹果的一些政策,只能迂回的获的,我使用了 Charles ,Charles的安装设置就不说了,Google能找到一堆教程。开始抓包后,然后在IPhone上设置手动的HTTP代理。
接着就是退出知乎,重新登录。
可以看到下面Charles界面左侧会出现api.zhihu.com的一项,点开可以看到sign_in项,再点开。在右侧就会出现API的信息。但我们先看Contents里面的Headers部分:
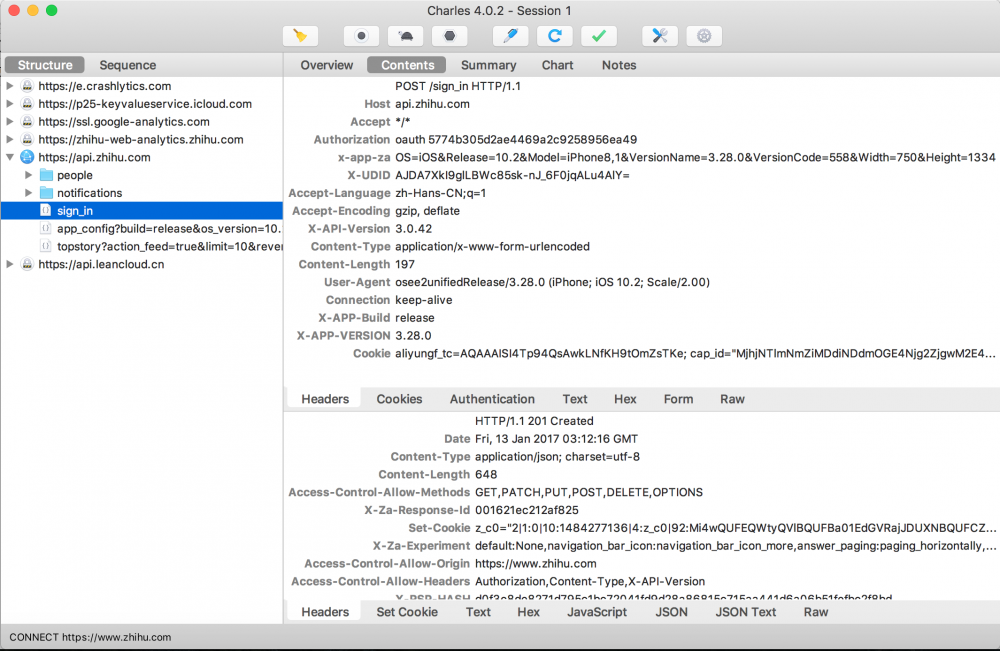
这里面信息很多:
- 登录API地址是: https://api.zhihu.com/sign_in
- 登录请求使用POST(废话)
- 登录需要添加一大坨自定义头信息,还要包含身份认证
其中自定义的头信息可以设置成常量,放进config.py:
API_VERSION = '3.0.42' APP_VERSION = '3.28.0' APP_BUILD = 'release' UUID = 'AJDA7XkI9glLBWc85sk-nJ_6F0jqALu4AlY=' UA = 'osee2unifiedRelease/3.28.0 (iPhone; iOS 10.2; Scale/2.00)' APP_ZA = 'OS=iOS&Release=10.2&Model=iPhone8,1&VersionName=3.28.0&VersionCode=558&Width=750&Height=' CLIENT_ID = '8d5227e0aaaa4797a763ac64e0c3b8' APP_SECRET = b'ecbefbf6b17e47ecb9035107866380'
其中CLIENT_ID和APP_SECRET基于安全考虑用的是zhihu-oauth中默认的。我之前介绍过用local_config的方法替换config里面的默认配置,让一些关键常量不必放入版本库。
有一些一般(严谨点)是不会变的, 比如API地址,所以放进settings.py
ZHIHU_API_ROOT = 'https://api.zhihu.com' LOGIN_URL = ZHIHU_API_ROOT + '/sign_in' CAPTCHA_URL = ZHIHU_API_ROOT + '/captcha'
我们知道requests这个库是支持身份认证的,在这里我们按照人家的玩法,自定义ZhihuOAuth类:
from requests.auth import AuthBase
from config import (
API_VERSION, APP_VERSION, APP_BUILD, UUID, UA, APP_ZA, CLIENT_ID)
classZhihuOAuth(AuthBase):
def__init__(self, token=None):
self._token = token
def__call__(self, r):
r.headers['X-API-Version'] = API_VERSION
r.headers['X-APP_VERSION'] = APP_VERSION
r.headers['X-APP-Build'] = APP_BUILD
r.headers['x-app-za'] = APP_ZA
r.headers['X-UDID'] = UUID
r.headers['User-Agent'] = UA
if self._token is None:
auth_str = 'oauth {client_id}'.format(
client_id=CLIENT_ID
)
else:
auth_str = '{type} {token}'.format(
type=str(self._token.type.capitalize()),
token=str(self._token.token)
)
r.headers['Authorization'] = auth_str
return r
然后就可以使用诸如 requests.get('https://api.xxx.com/yy, auth=ZhihuOAuth()) 的方式了,不需要粗暴的拼headers。
上面的auth_str有2种,这是由于在为登录前是没有token的,使用的是oauth,在登录之后会拿到token。之后在调取其他API接口就需要这个token了。之后还会提到。
接着,我们看一下提交的表单和请求登录成功后返回的内容:
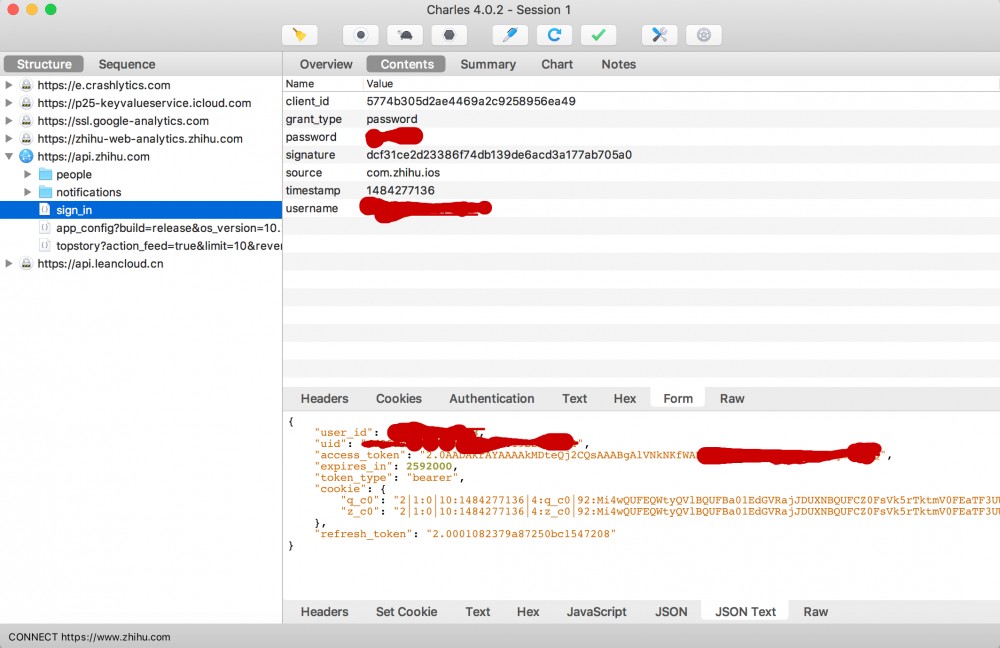
这次选择的是Form,返回的结果是切换到JSON Text这个Tab看到的。处于安全性的考虑,我隐去了一些敏感信息。
当成功之后,会返回一个access_token,也包含了token类型是bearer。之后的API调用就要使用和这个token了。假如我们在刷首页的feed,会有这样的一个请求:

注意其中的头信息中的Authorization,就是拿着这个access_token的值和类型去认证的。
原理说完了,感受下代码怎么写
自定义异常
今天我们讲的是登录,那么就要有登录失败的异常处理。好的习惯是自定义一些异常类exception.py:
class LoginException(Exception):
def __init__(self, error):
self.error = error
def __repr__(self):
return 'Login Fail: {}'.format(self.error)
__str__ = __repr__
可能有同学会问,咦,用复数形式的exceptions.py不是更贴切么?因为exceptions已经被Python占用了 -. -
Token类
对access_token的操作应该放到一个类下面。 所以我也是用了单独的ZhihuToken
classZhihuToken:
def__init__(self, user_id, uid, access_token, expires_in, token_type,
refresh_token, cookie, lock_in=None, unlock_ticket=None):
self._create_at = time.time()
self._user_id = uid
self._uid = user_id
self._access_token = access_token
self._expires_in = expires_in
self._expires_at = self._create_at + self._expires_in
self._token_type = token_type
self._refresh_token = refresh_token
self._cookie = cookie
# Not used
self._lock_in = lock_in
self._unlock_ticket = unlock_ticket
@classmethod
deffrom_file(cls, filename):
with open(filename) as f:
return cls.from_dict(json.load(f))
@staticmethod
defsave_file(filename, data):
with open(filename, 'w') as f:
json.dump(data, f)
@classmethod
deffrom_dict(cls, json_dict):
try:
return cls(**json_dict)
except TypeError:
raise ValueError(
'"{json_dict}" is NOT a valid zhihu token json.'.format(
json_dict=json_dict
))
如果已经有token,用起来是这样的:
In [1]: from client import ZhihuToken, TOKEN_FILE In [2]: token = ZhihuToken.from_file(TOKEN_FILE) In [3]: token._token_type Out[3]: 'bearer' In [4]: token._expires_at Out[4]: 1486884430.011306
类方法from_dict的返回值是一个该类的实例的玩法现在用的非常普遍。
Client类
最后就是实现登录功能,我统一放在ZhihuClient类中,它做了如下事:
- 使用requests.session创建一个会话供全局使用。
- 构造请求登录的表单dict。
- 登录提交前先确认是否需要输入验证码,如果不需要直接提交,如果需要通过API把验证码图片下载到本地,然后等待在终端输入,确认验证成功后再提交。
- 提交成功后保存这个访问token,一段时间内就不用再登录了。
首先看初始化方法:
TOKEN_FILE = 'token.json' # 事实上应该放在config.py里面
classZhihuClient:
def__init__(self, username=None, passwd=None, token_file=TOKEN_FILE):
self._session = requests.session()
self._session.verify = False
self.username = username
self.passwd = passwd
if os.path.exists(token_file):
self._token = ZhihuToken.from_file(token_file)
else:
self._login_auth = ZhihuOAuth()
json_dict = self.login()
ZhihuToken.save_file(token_file, json_dict)
self._session.auth = ZhihuOAuth(self._token)
第一次是需要用户名和密码的,之后它们就不是必选的了,只有token_file是需要的。需要注意,zhihu-oauth项目中还包含如下一句:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
要不然在一些环境中可以看到这个warn信息吗,其次是 self._session.verify = False 也很必要。
如果token_file不存在就会触发登录,方法如下:
LOGIN_DATA = {
'grant_type': 'password',
'source': 'com.zhihu.ios',
'client_id': CLIENT_ID
}
classZhihuClient:
...
deflogin(self):
data = LOGIN_DATA.copy()
data['username'] = self.username
data['password'] = self.passwd
gen_login_signature(data)
if self.need_captcha():
captcha_image = self.get_captcha()
with open(CAPTCHA_FILE, 'wb') as f:
f.write(captcha_image)
print('Please open {0} for captcha'.format(
os.path.abspath(CAPTCHA_FILE)))
captcha = input('captcha: ')
os.remove(os.path.abspath(CAPTCHA_FILE))
res = self._session.post(
CAPTCHA_URL,
auth=self._login_auth,
data={'input_text': captcha}
)
try:
json_dict = res.json()
if 'error' in json_dict:
raise LoginException(json_dict['error']['message'])
except (ValueError, KeyError) as e:
raise LoginException('Maybe input wrong captcha value')
res = self._session.post(LOGIN_URL, auth=self._login_auth, data=data)
try:
json_dict = res.json()
if 'error' in json_dict:
raise LoginException(json_dict['error']['message'])
self._token = ZhihuToken.from_dict(json_dict)
return json_dict
except (ValueError, KeyError) as e:
raise LoginException(str(e))
首先是构造表单数据,然后判断是否需要验证码(抽出来放在独立的方法中了)。顺便提一下,我习惯的方法的长度标准一般是一屏可以看完,再多了就会把一部分内容剥离开,但是一般也没必要剥离的那么分散,适用就好。
need_captcha方法也比较简单,总之无论哪一步出错我都抛LoginException退出:
defneed_captcha(self):
res = self._session.get(CAPTCHA_URL, auth=self._login_auth)
try:
j = res.json()
return j['show_captcha']
except KeyError:
raise LoginException('Show captcha fail!')
gen_login_signature我并没有去研究,直接抄袭了:
import hashlib
import hmac
import time
from config import APP_SECRET
defgen_login_signature(data):
data['timestamp'] = str(int(time.time()))
params = ''.join([
data['grant_type'],
data['client_id'],
data['source'],
data['timestamp'],
])
data['signature'] = hmac.new(
APP_SECRET, params.encode('utf-8'), hashlib.sha1).hexdigest()
这样就实现了知乎登录以及拿到access_token,token都有了,想干什么就去干吧,对,正好明天周末。
说在最后
最后作为爬虫爱好者我提点意见,爬虫技术拿来分享,我很赞同;爬到数据去做分析,把分析的结果拿来分享我也支持。
但是 我严重鄙视把被爬取的网站的数据整理好直接放在百度网盘之类的共享行为!! 我教大家写爬虫,但请不要涉及工程师的道德底线和法律底线,很low。
之前我转载过一篇文章,当时也留了百度网盘地址但是里面的内容由于格式错乱并不能直接用,而且为了尊重原作者转载都是全部内容不去改动。但是随着最近这种爬虫文章越来越多,甚至感觉自己也做了帮凶,但以后绝不会再发这样的文章。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

